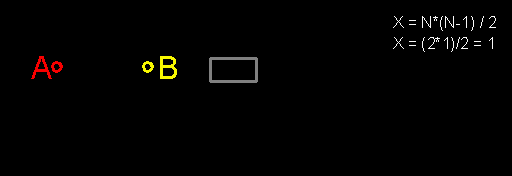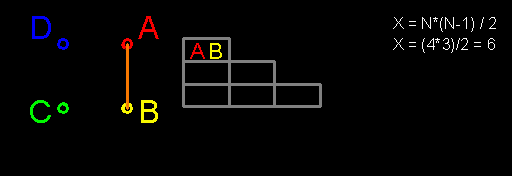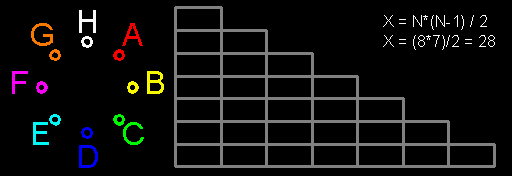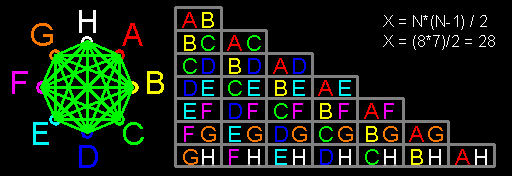Мне нравятся разговоры на тему «мне раньше в школе/институте/родители говорили, а теперь я узнал». Если по счастливой случайности я оказываюсь хоть немного компетентен в обсуждаемом вопросе, то такие разговоры обычно сводятся к одному из трех вариантов: «где вообще ты раньше слышал такую чушь?» (если собеседник прав), «а с чего ты взял, что это так?» (если он не прав) и «ты прав, только это не противоречит тому, что тебе говорили раньше» (в подавляющем большинстве случаев). Нравятся такие разговоры мне по следующей причине: обычно их инициатор не обременен излишним предварительным знанием вопроса, что в некоторых случаях позволяет ему указать на некоторые моменты, которые принимались как очевидные, на самом деле таковыми не являясь. И одной из тем для подобных бесед оказалось функциональное программирование.
Вообще про ФП написано и сказано столько, что вроде бы все вопросы о его применимости, крутости, производительности и т.п. обглоданы до костного мозга. И все-таки такого рода вопросы поднимаются снова и снова, и всегда найдется желающий рассказать о том, что вы все неправильно поняли, а на самом деле оно эвона как. Пожалуй, сегодня я примерю на себя эту неблагодарную роль, поскольку недавно попались на глаза несколько постов на эту многострадальную тему. В
первом и
втором в очередной раз рассказано, что ФП — дрянь и изучать его — только портить свою карму будущего специалиста. Другие (
раз и
два) куда более адекватны, в них автор ставит целью объяснить, что все эти ваши лямбды, комбинаторы, категории — не более, чем пыль в глаза, а само ФП — штука простая, понятная и приятная в быту.
Насколько это соответствует истине?