(ИЛИ каламбур типизации, неопределенное поведение и выравнивание, о мой Бог!)
Всем привет, уже через несколько недель мы запускаем новый поток по курсу
«Разработчик С++». Этому событию и будет посвящен наш сегодняшний материал
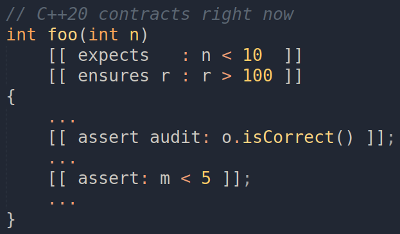
Что такое strict aliasing? Сначала мы опишем, что такое алиасинг (aliasing), а затем мы узнаем, к чему тут строгость (strict).
В C и C ++ алиасинг связан с тем, через какие типы выражений нам разрешен доступ к хранимым значениям. Как в C, так и в C ++ стандарт определяет, какие выражения для именования каких типов допустимы. Компилятору и оптимизатору разрешается предполагать, что мы строго следуем правилам алиасинга, отсюда и термин — правило строгого алиасинга (strict aliasing rule). Если мы пытаемся получить доступ к значению, используя недопустимый тип, оно классифицируется как неопределенное поведение (
undefined behavior — UB). Когда у нас неопределенное поведение, все ставки сделаны, результаты нашей программы перестают быть достоверными.
К сожалению, с нарушениями строго алиасинга, мы часто получаем ожидаемые результаты, оставляя возможность того, что будущая версия компилятора с новой оптимизацией нарушит код, который мы считали допустимым. Это нежелательно, стоит понять строгие правила алиасинга и избежать их нарушения.

Чтобы лучше понять, почему нас должно это волновать, мы обсудим проблемы, возникающие при нарушении правил строго алиасинга, каламбур типизаций (type punning), так как он часто используется в правилах строгого алиасинга, а также о том, как правильно создавать каламбур, наряду с некоторой возможной помощью C++20, чтобы упростить каламбур и уменьшить вероятность ошибок. Мы подведем итоги обсуждения, рассмотрев некоторые методы выявления нарушений правил строго алиасинга.



»")





 Антон — представитель России в ISO на международных заседаниях рабочей группы по стандартизации C++, автор нескольких принятых предложений к стандарту языка C++, Boost-библиотек и книги «Boost C++ Application Development Cookbook».
Антон — представитель России в ISO на международных заседаниях рабочей группы по стандартизации C++, автор нескольких принятых предложений к стандарту языка C++, Boost-библиотек и книги «Boost C++ Application Development Cookbook».  Павел — разработчик-исследователь в Лаборатории Касперского, занимается вопросами применения методов машинного обучения в задачах обеспечения безопасности кибер-физических систем, ведёт преподавательскую деятельность. В ожидании видео с конференции предлагаю вам прочитать расшифровку нашей беседы.
Павел — разработчик-исследователь в Лаборатории Касперского, занимается вопросами применения методов машинного обучения в задачах обеспечения безопасности кибер-физических систем, ведёт преподавательскую деятельность. В ожидании видео с конференции предлагаю вам прочитать расшифровку нашей беседы.
