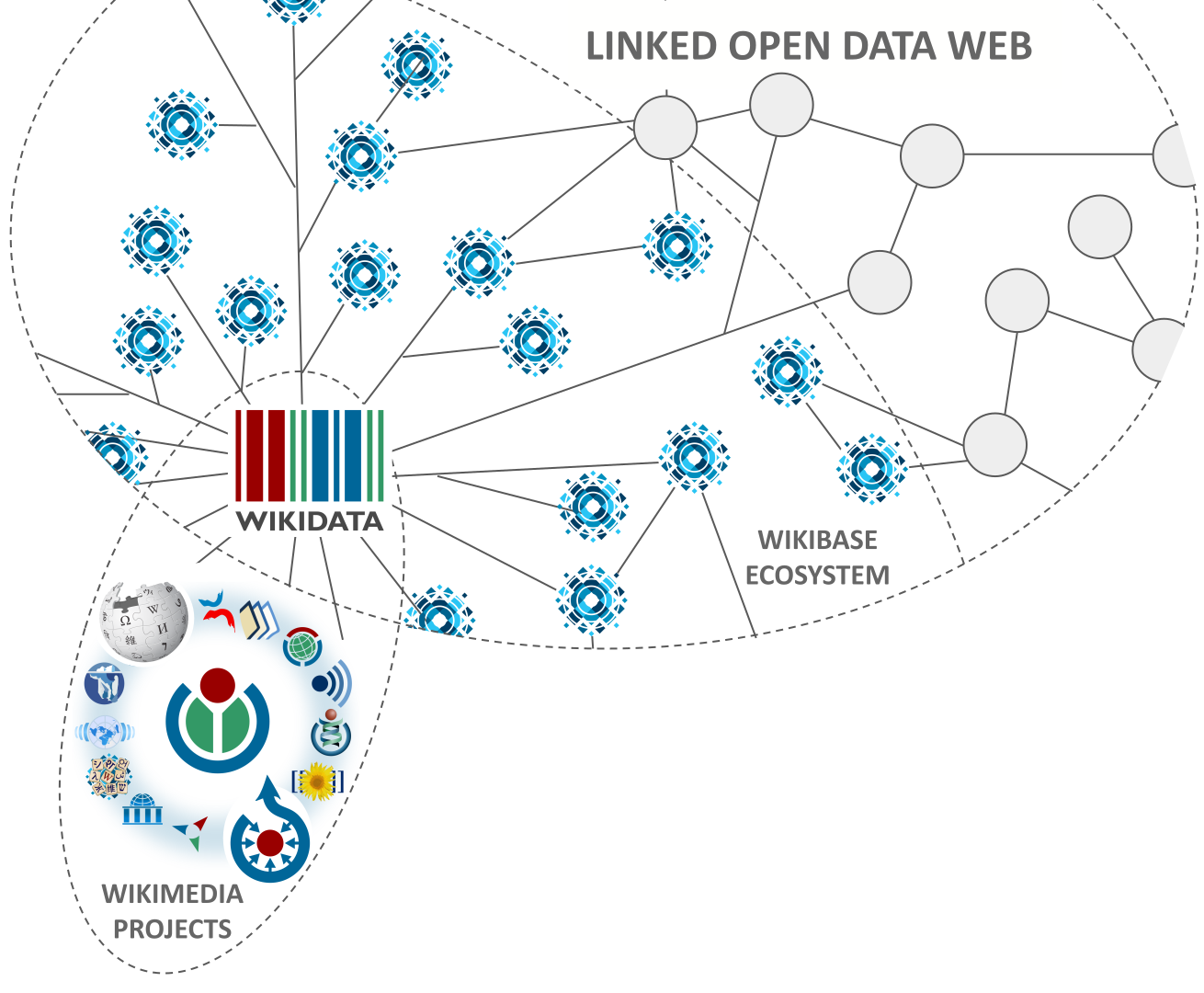
Этому миру требуется новая теория, теория, которая могла бы описать все теории на планете. Теория которая могла бы одинаково легко описывать философию, математику, физику и психологию. Сделать все виды наук вычислимыми.
Именно над этим мы и работаем. Эта теория, если у нас всё получится, станет единой метатеорией всего.
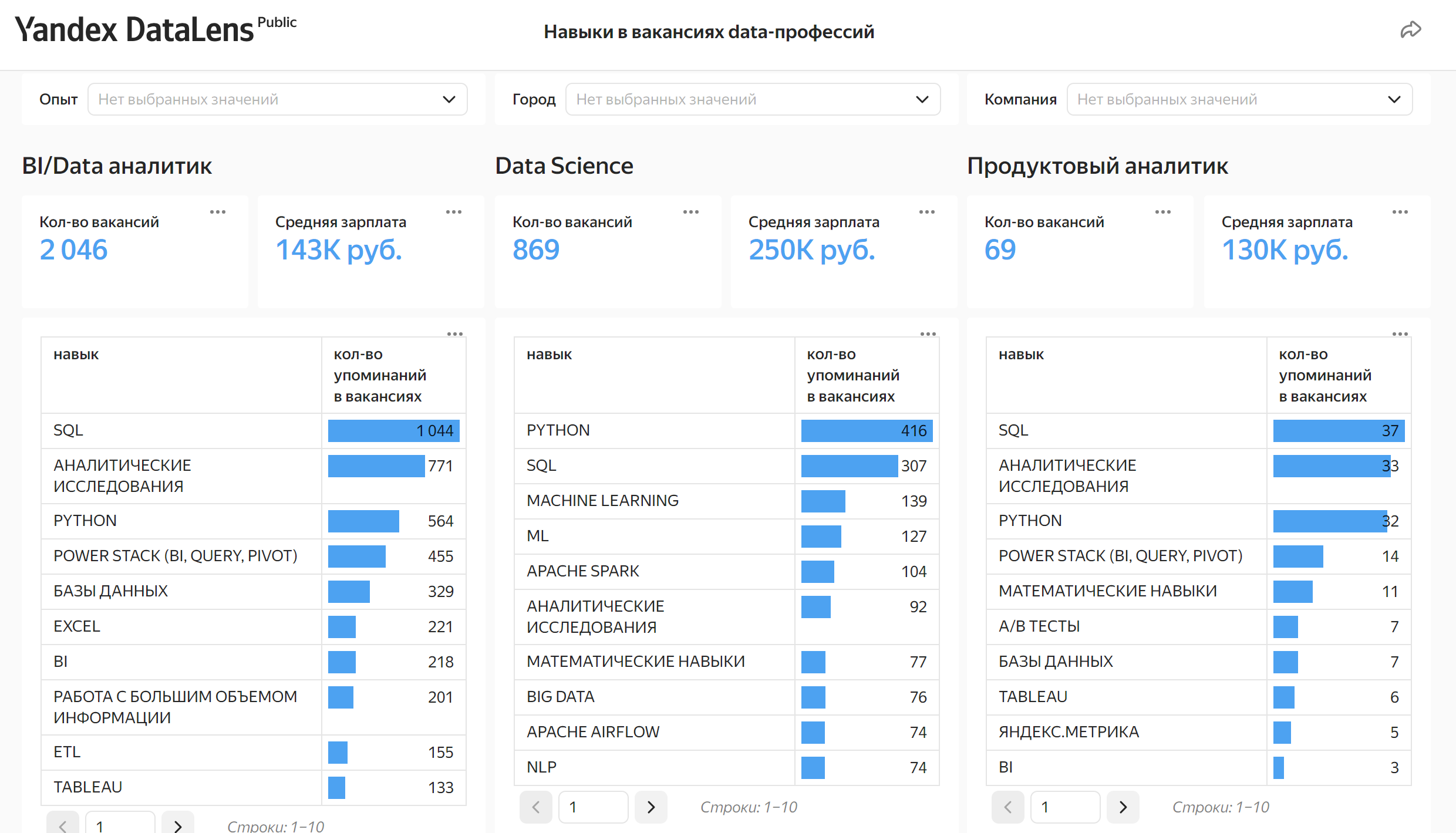
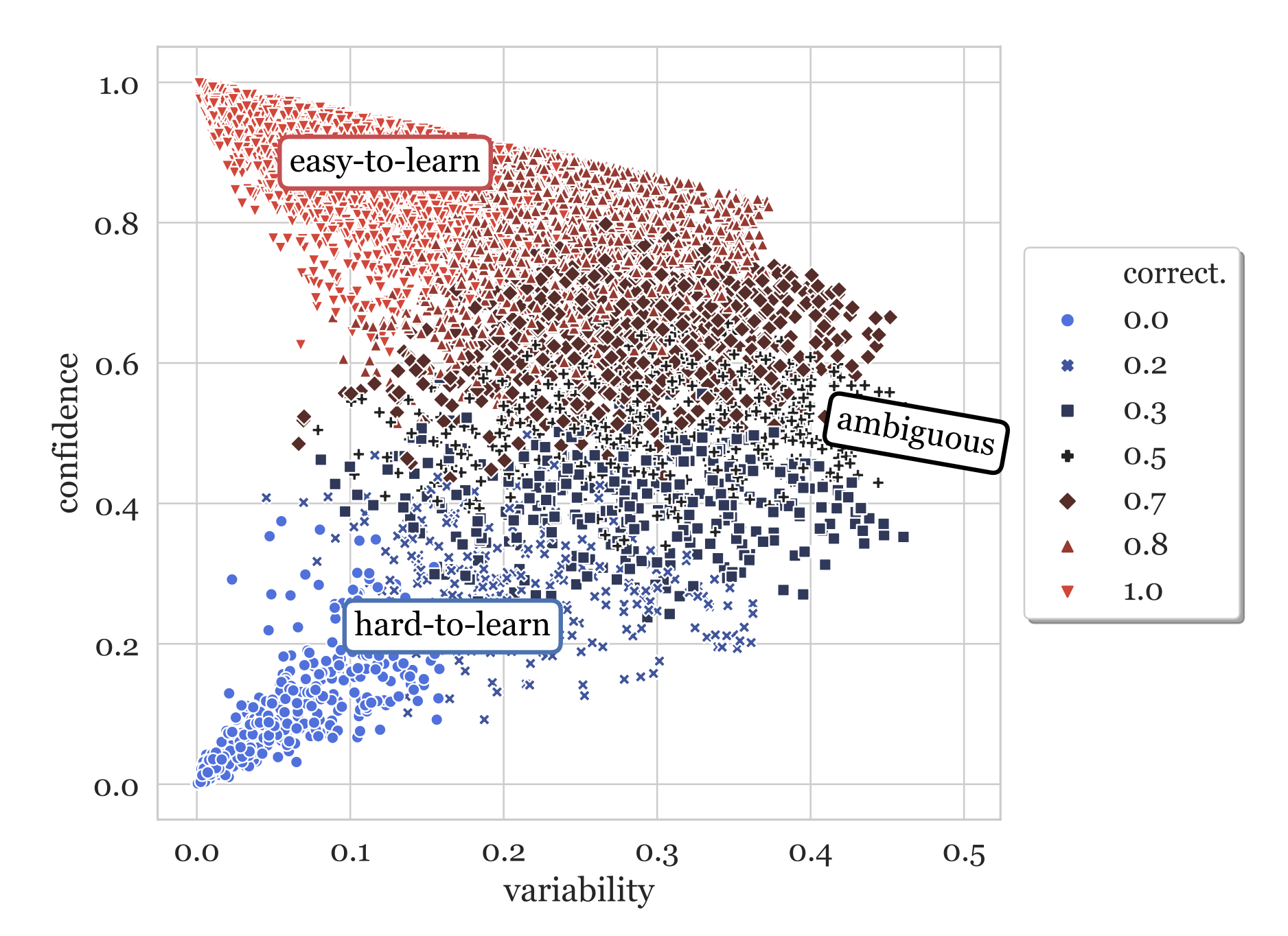
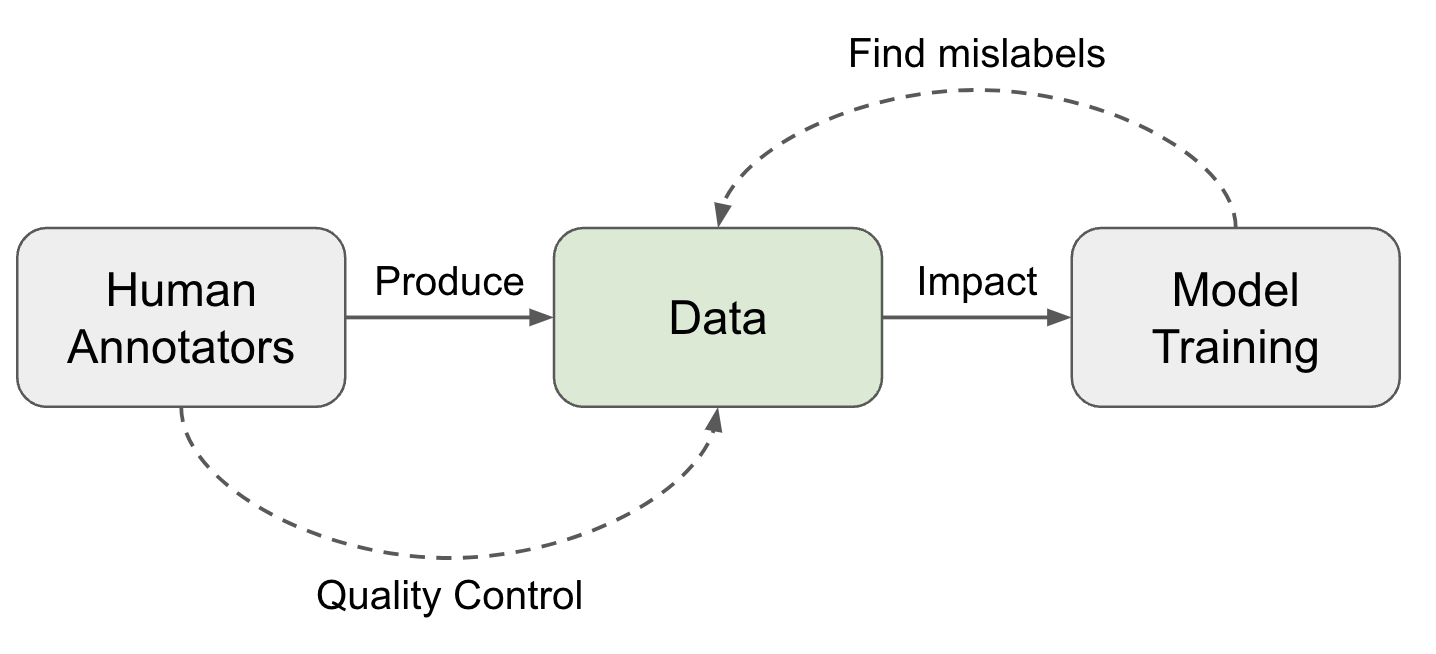
Прошёл год с прошлой публикации, и сейчас наша задача поделиться нашим прогрессом. Это по прежнему не стабильная версия, это черновик. И поэтому мы будем рады любой обратной связи, а так же участию в разработке теории связей.
Как и всё что мы делали до этого, теория связей публикуется и передаётся в общественное достояние и принадлежит человечеству. То есть именно тебе. У этого труда множество авторов, однако сам этот труд намного важнее конкретного авторства. И мы надеемся уже сегодня это сможет быть полезно каждому.
Мы приглашаем тебя стать частью этого увлекательного приключения.