Добрый день, уважаемые читатели! Материал носит теоретический характер и адресован исключительно начинающим аналитикам, которые впервые столкнулись с BI-аналитикой.
Что традиционно понимается под этим понятием? Если говорить простым языком, то это комплексная система (как и, например, бюджетирование) по сбору, обработке и анализу данных, представляющая конечные результаты в виде графиков, диаграмм, таблиц.
Это требует слаженной работы сразу нескольких специалистов. Дата-инженер отвечает за хранилища и ETL/ELT-процессы, аналитик данных помогает в заполнении базы данных, аналитик BI разрабатывает управленческие панели, бизнес-аналитик упрощает коммуникации с заказчиками отчетов. Но такой вариант возможен, только если фирма готова оплачивать работу команды. В большинстве случаев небольшие компании для минимизации затрат делают ставку на одного человека, который зачастую вообще не обладает широким кругозором в области BI, а имеет лишь шапочное знакомство с платформой для отчетов.
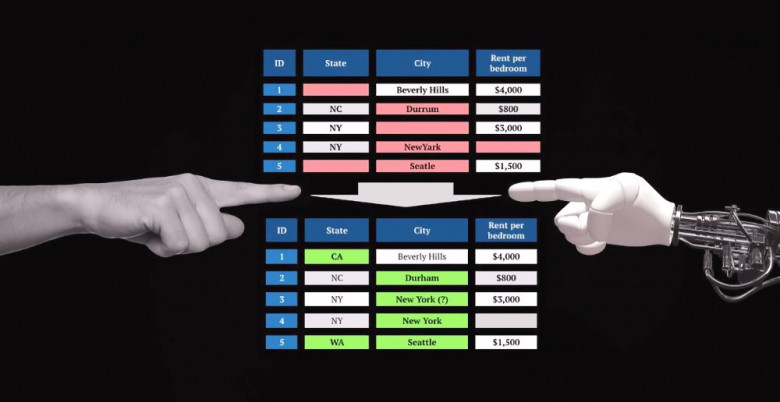
В таком случае происходит следующее: сбор, обработка и анализ данных происходит силами единственного инструмента – самой BI-платформой. При этом данные предварительно никак не очищаются, не проходят компоновки. Забор информации идет из первичных источников без участия промежуточного хранилища. Результаты такого подхода можно легко лицезреть на тематических форумах. Если постараться обобщить все вопросы касательно BI-инструментов, то в топ-3 попадут, наверное, следующие: как загрузить в систему плохо структурированные данные, как по ним рассчитать требуемые метрики, что делать, если отчет работает очень медленно. Что удивительно, на этих форумах вы практически не найдете обсуждений ETL-инструментов, описания опыта применения хранилищ данных, лучших практик программирования и запросов SQL. Более того, я неоднократно сталкивался с тем, что опытные BI-аналитики не очень лестно отзывались о применении R/Python/Scala, мотивируя это тем, что все проблемы можно решить только силами BI-платформы. Вместе с тем всем понятно, что грамотный дата инжиниринг позволяет закрывать массу проблем при построении BI-отчетности.