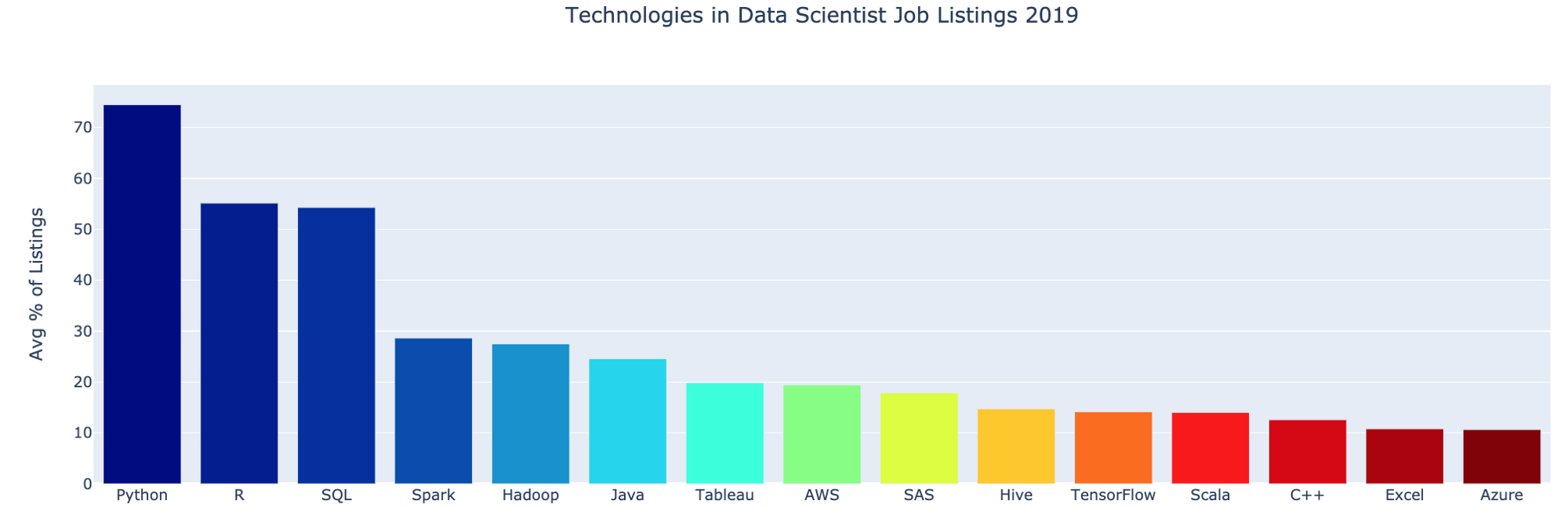
Какие технические знания становятся наиболее популярными у работодателей, а какие теряют свою популярность.
В своей
первоначальной статье 2018-го года я рассматривал спрос на общие навыки – статистику и коммуникацию. Также я рассматривал спрос на Python и язык программирования R. Технологии создания программного обеспечения меняются намного быстрее, чем спрос на общие навыки, поэтому в этот обновленный анализ я включаю только технологии.
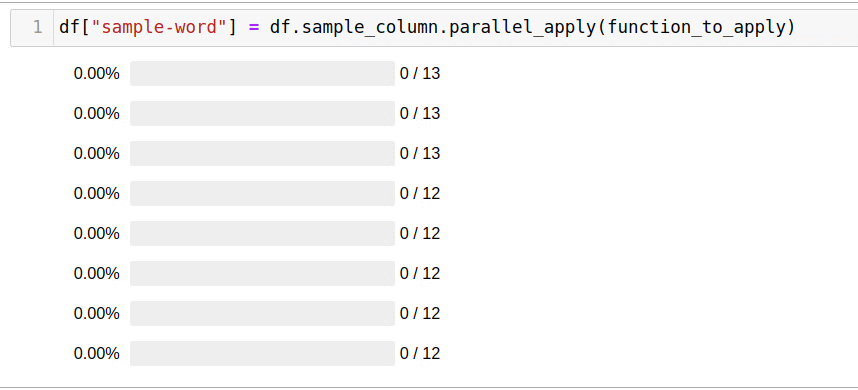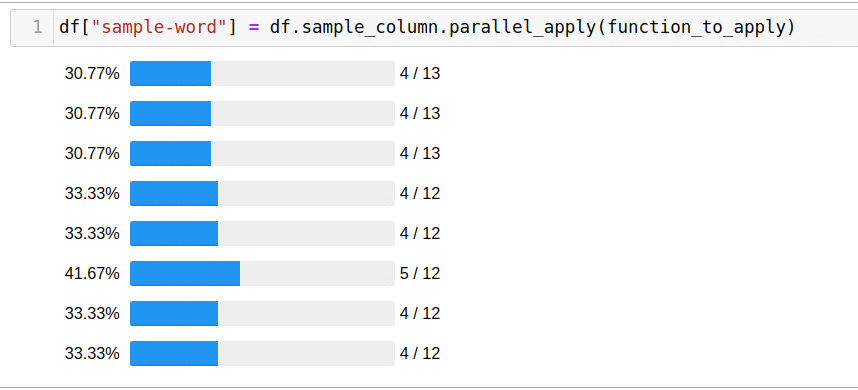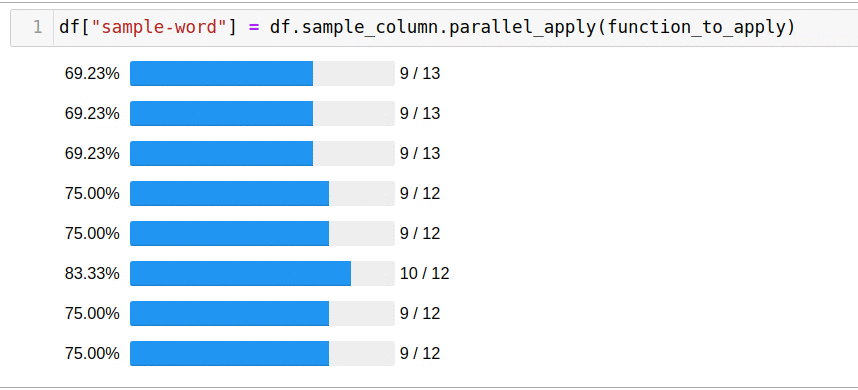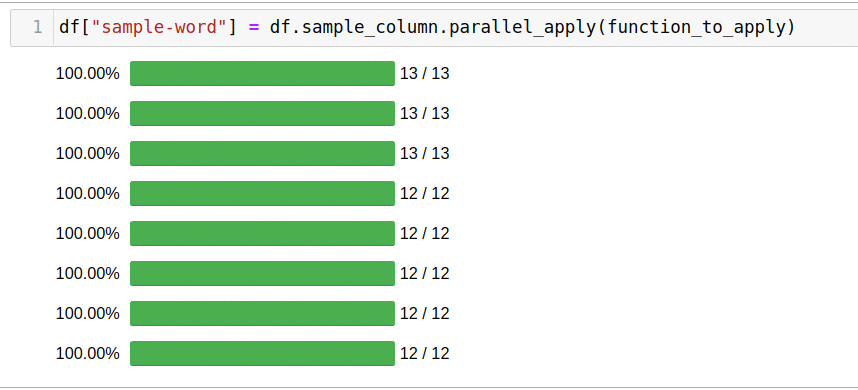
Я искал ключевые слова, которые появлялись в списках вакансий на должность «Data Scientist» в США на таких сайтах как
SimplyHired,
Indeed,
Monster и
LinkedIn. В этот раз я решил написать код, чтобы изучить все списки вместо того, чтобы искать вручную. Это решение оказалось очень успешным для SimplyHired, Indeed и Monster. Я использовал
Requests и
Beautiful Soup из библиотеки Python HTTP. Код с анализом вы можете увидеть в моем
отчете на GitHub.
Продираться через LinkedIn оказалось в разы сложнее. Необходимо пройти процесс авторизации, чтобы просматривать точное количество списков вакансий. Я решил использовать Selenium для просмотра страниц без графического интерфейса пользователя. В сентябре 2019 года
Верховный суд США выиграл дело против LinkedIn, тем самым позволив очистить данные сайта. Тем не менее, я не смог получить доступ к своей учетной записи после нескольких попыток входа. Возможно, эта проблема возникла из-за ограничения скорости. Апдейт: Я все же смог войти, но боюсь, что меня заблокируют при повторной попытке.









 Chief Data Scientist NVIDIA и преподаватель
Chief Data Scientist NVIDIA и преподаватель