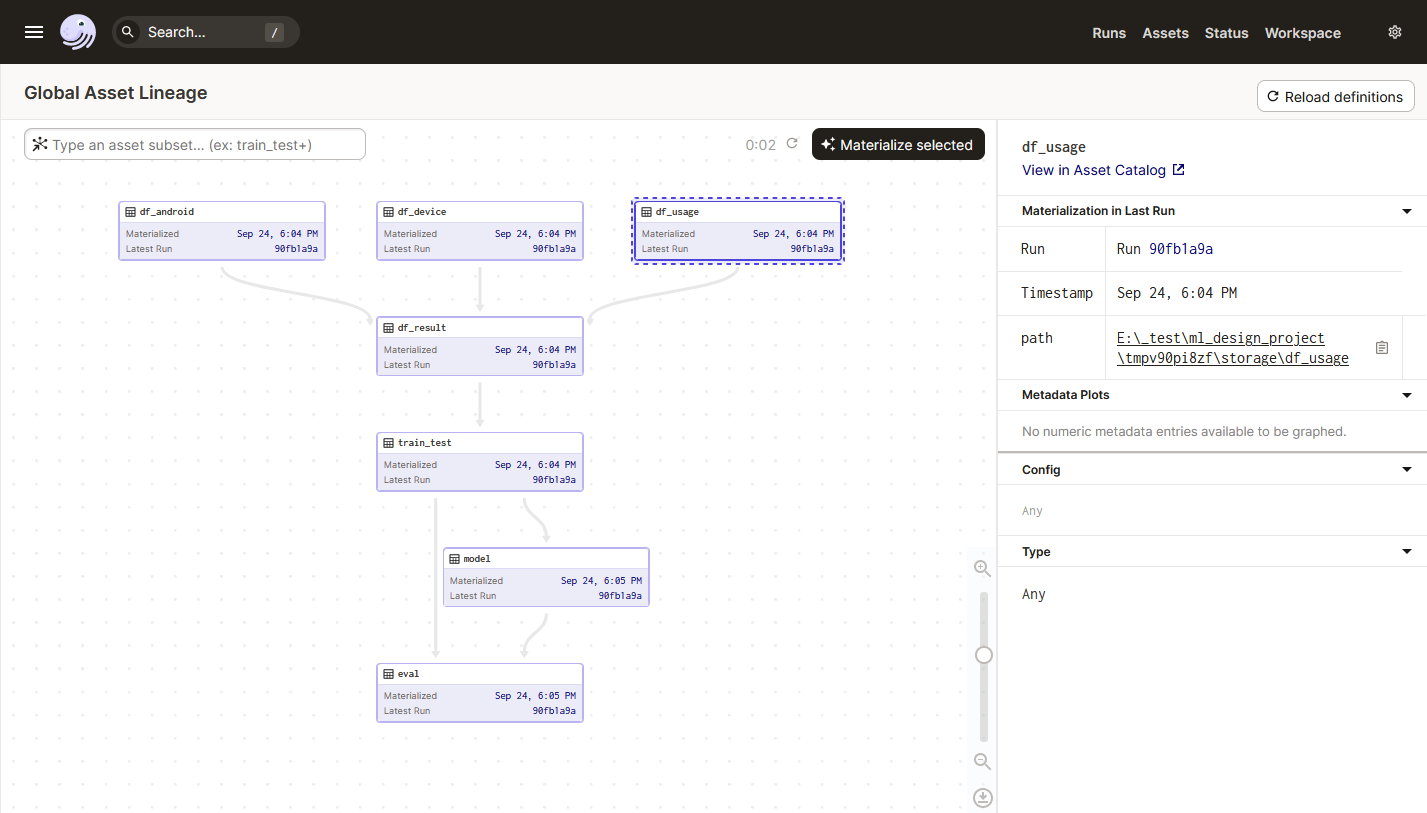
Каждый, кто слышит словосочетание "язык программирования", наверняка представляет себе код или скрипт, который выполняет строгий порядок действий для решения сложной технической задачи. Если спросить прохожего, для каких целей используются языки программирования, первое, что придет ему на ум - разработка, а любой гуманитарий скажет, что это скучно и совершенно не интересно. Однако, мне хотелось бы развеять эти стереотипы. Учитывая современные тенденции роста научно-технического прогресса, важно отметить, что программирование пересало быть чисто "техническим" инструментом. Сегодня оно позволяет не только создавать алгоритмы для управления техникой, но и делать научные открытия, например в биологии. Понять, как устроена биоинжереная машина внутри наших клеток, какие функции выполняеет каждый отдельно взятый ген, какие гены ответственны за наши болезни, как вирусы и бактерии влияют на нас на молекулярном уровне, как создать новый фармацевтический препарат и множество других вопросов, позволяет программирование.
Python - высокоуровневый язык программирования, который широко применяется в самых разных сферах деятельности: в разработке, в тестировании, в администровании, в анализе данных, в моделировании, а также в науке. Широкое распространение он получил не только, благодаря своей простоте и лаконичности, но и в силу своей модульности, возможности интегрироваться с другими языками программирования и наличия большого количества пакетов для анализа больших данных и научных расчетов.