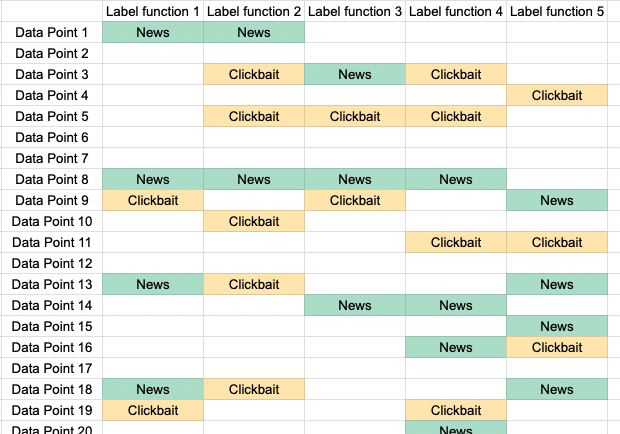
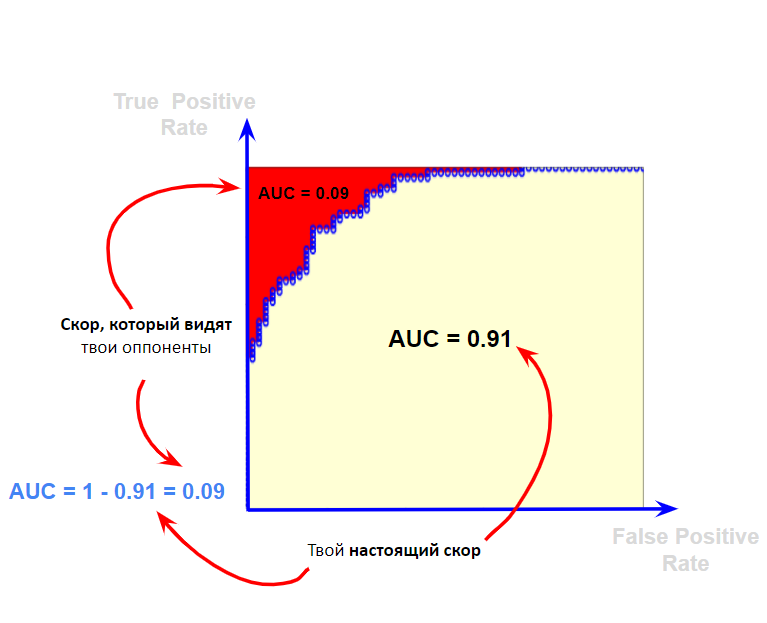
Когда чуть больше года назад я впервые услышал о слабой разметке, то поначалу отнёсся к ней скептически. Суть слабой разметки (weak labelling) заключается в том, что можно заменить аннотированные вручную данные на данные, созданные по эвристическим правилам, написанным специалистами в соответствующей области. Мне это показалось совершенно нелогичным. Если можно создать очень хорошую систему на основе правил, то почему бы просто не использовать эту систему? А если правила недостаточно хороши, то разве не будет плохой и модель, обученная на шумных данных? Это казалось мне возвратом в мир конструирования признаков, которому должно было прийти на смену глубокое обучение.
Однако за последний год моё отношение полностью переменилось. Я поработал над множеством NLP-проектов, в которых было задействовано извлечение данных, и намного сильнее углубился в изучение литературы про обучение со слабым контролем. Также я пообщался с руководителями команд ML в таких компаниях, как Apple, где услышал истории о том, как целые системы заменяли за считанные недели — благодаря сочетанию слабого контроля и машинного обучения им удавалось создать обширные наборы данных для языков, ресурсов по которым было мало и которые раньше попросту не обслуживались!
Поскольку теперь я обладаю энтузиазмом новообращённого, мне хочется рассказать о том, что такое слабый контроль, чему я научился и почему, на мой взгляд, в области аннотирования данных он дополняет такие техники, как активное обучение.