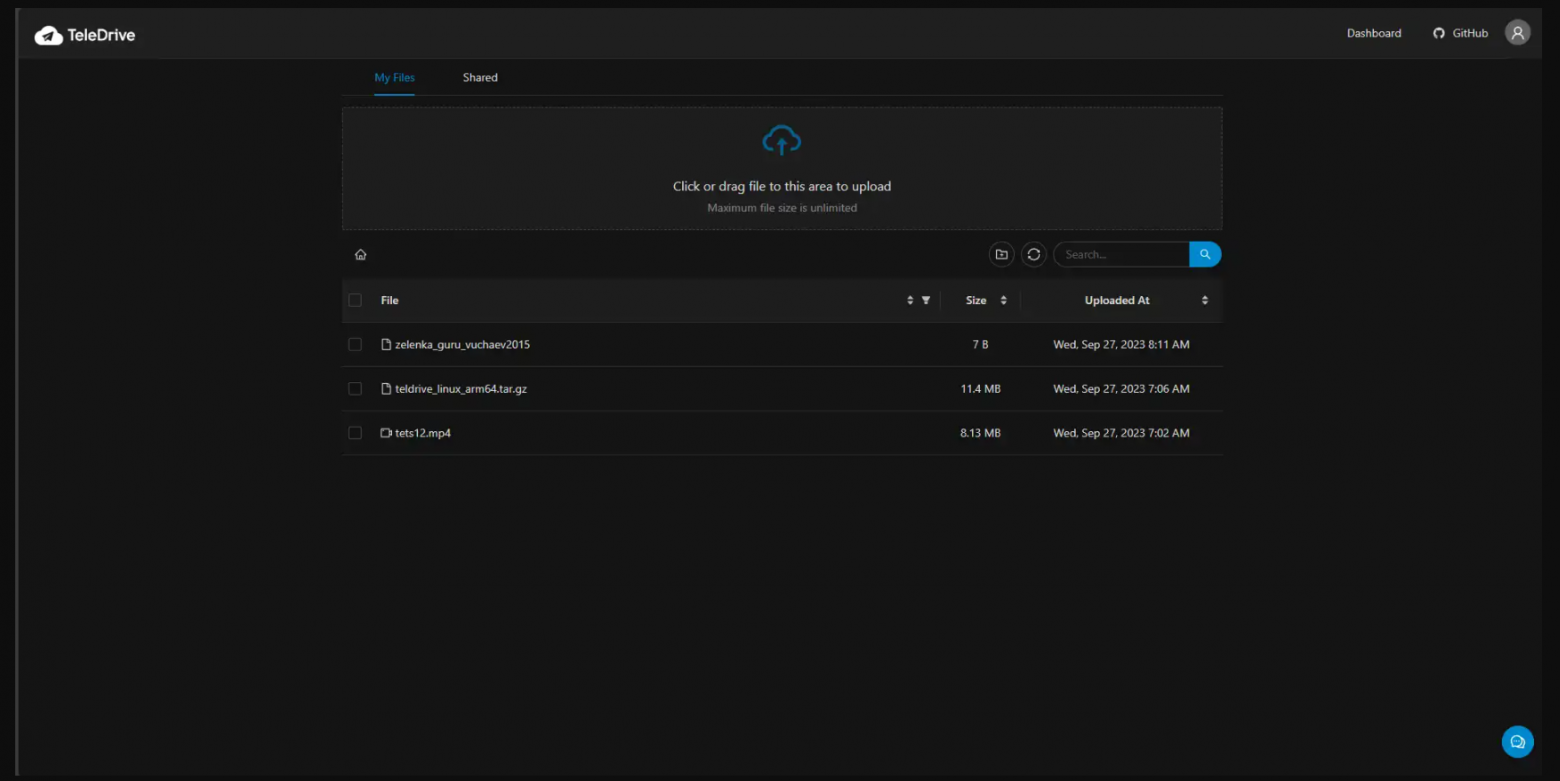
Hey everyone! Today, I'll guide you through creating a boundless cloud storage solution on Telegram using TeleDrive. This open-source project is a game-changer, offering functionalities like Google Drive/OneDrive via the Telegram API.
Hey everyone! Today, I'll guide you through creating a boundless cloud storage solution on Telegram using TeleDrive. This open-source project is a game-changer, offering functionalities like Google Drive/OneDrive via the Telegram API.

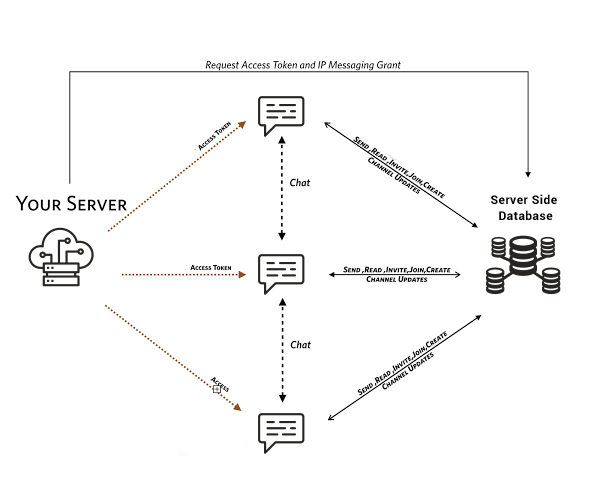
The DHT system has existed for many years now, and torrents along with it, which we successfully use to get any information we want.
Together with this system, there are commands to interact with it. There are not many of them, but only two are needed to create a decentralized database: put and get.

This is a TANGO archiving system, allows you to save data received from devices in the TANGO system.
Working with Linux will be described here (TangoBox 9.3 on base Ubuntu 18.04), this is a ready-made system where everything is configured.
It took me ~ 2 weeks to understand the architecture and write my own scripts for python for this case.
Allows you to store the history of the readings of your equipment.

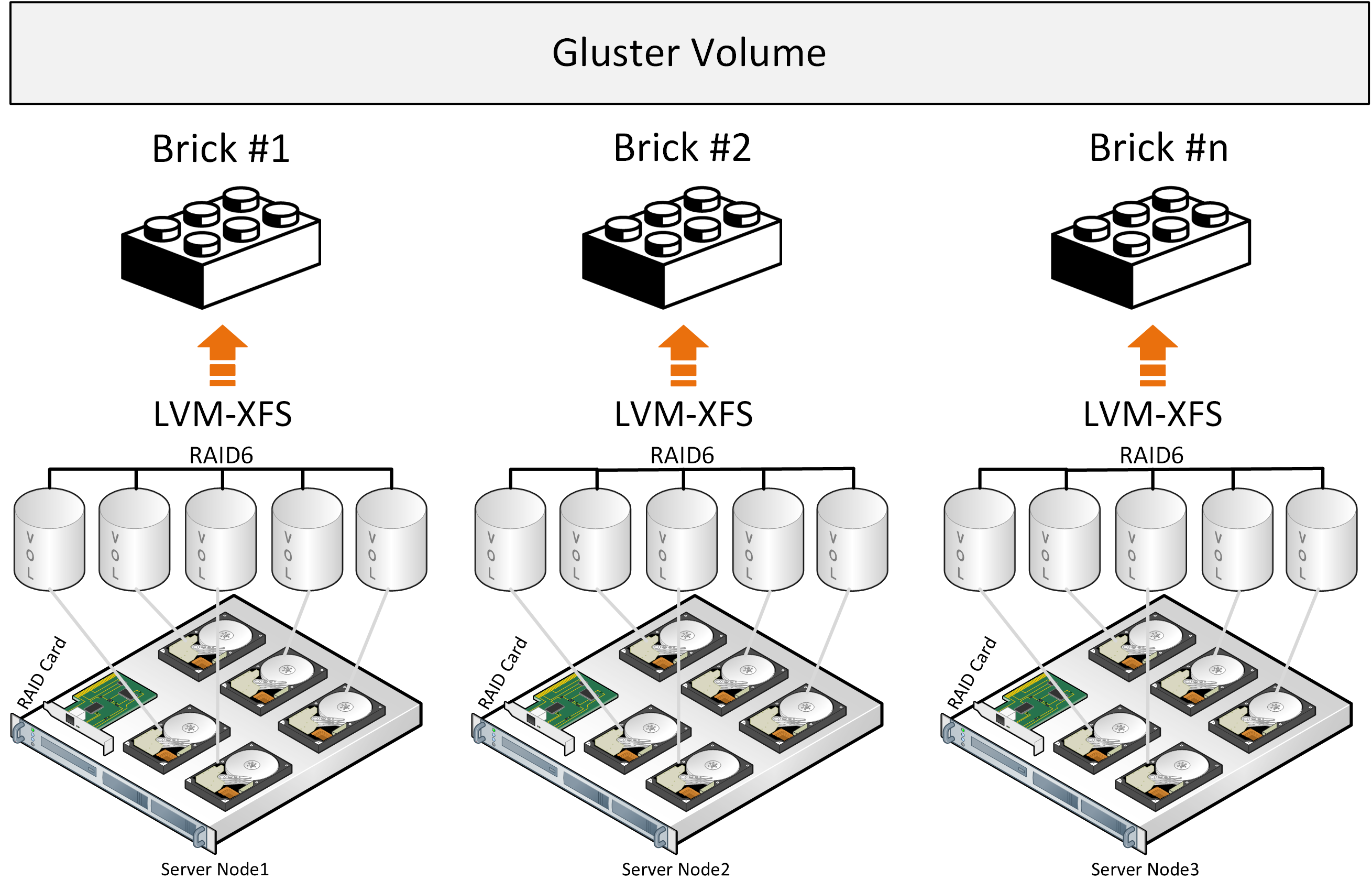
"Come, let us make bricks, and burn them thoroughly."
– legendary builders
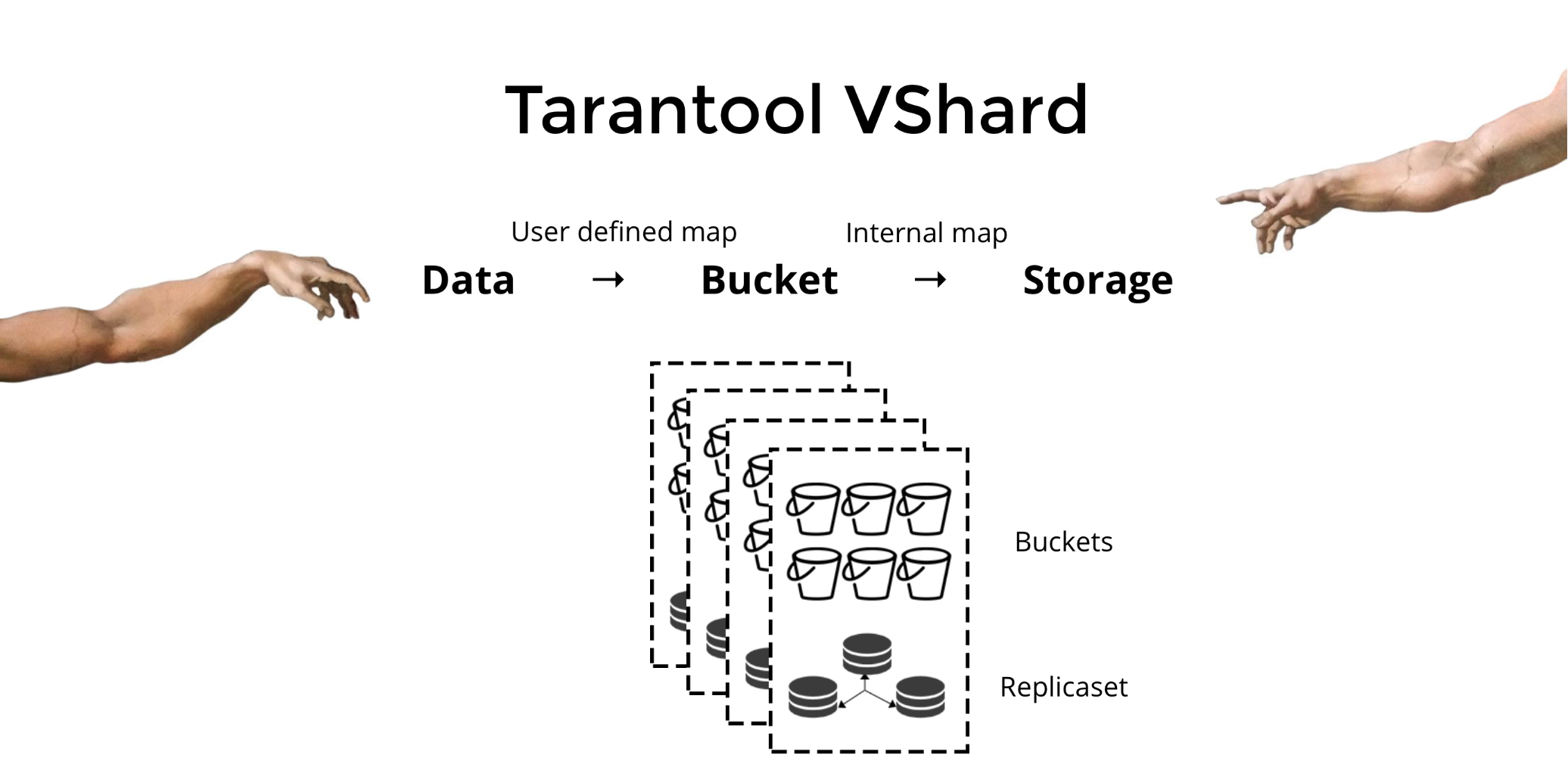
You may have noticed by 2020 that data is eating the world. And whenever any reasonable amount of data needs processing, a complicated multi-stage data processing pipeline will be involved.
At Bumble — the parent company operating Badoo and Bumble apps — we apply hundreds of data transforming steps while processing our data sources: a high volume of user-generated events, production databases and external systems. This all adds up to quite a complex system! And just as with any other engineering system, unless carefully maintained, pipelines tend to turn into a house of cards — failing daily, requiring manual data fixes and constant monitoring.
For this reason, I want to share certain good engineering practises with you, ones that make it possible to build scalable data processing pipelines from composable steps. While some engineers understand such rules intuitively, I had to learn them by doing, making mistakes, fixing, sweating and fixing things again…
So behold! I bring you my favourite Rules for Data Processing Pipeline Builders.