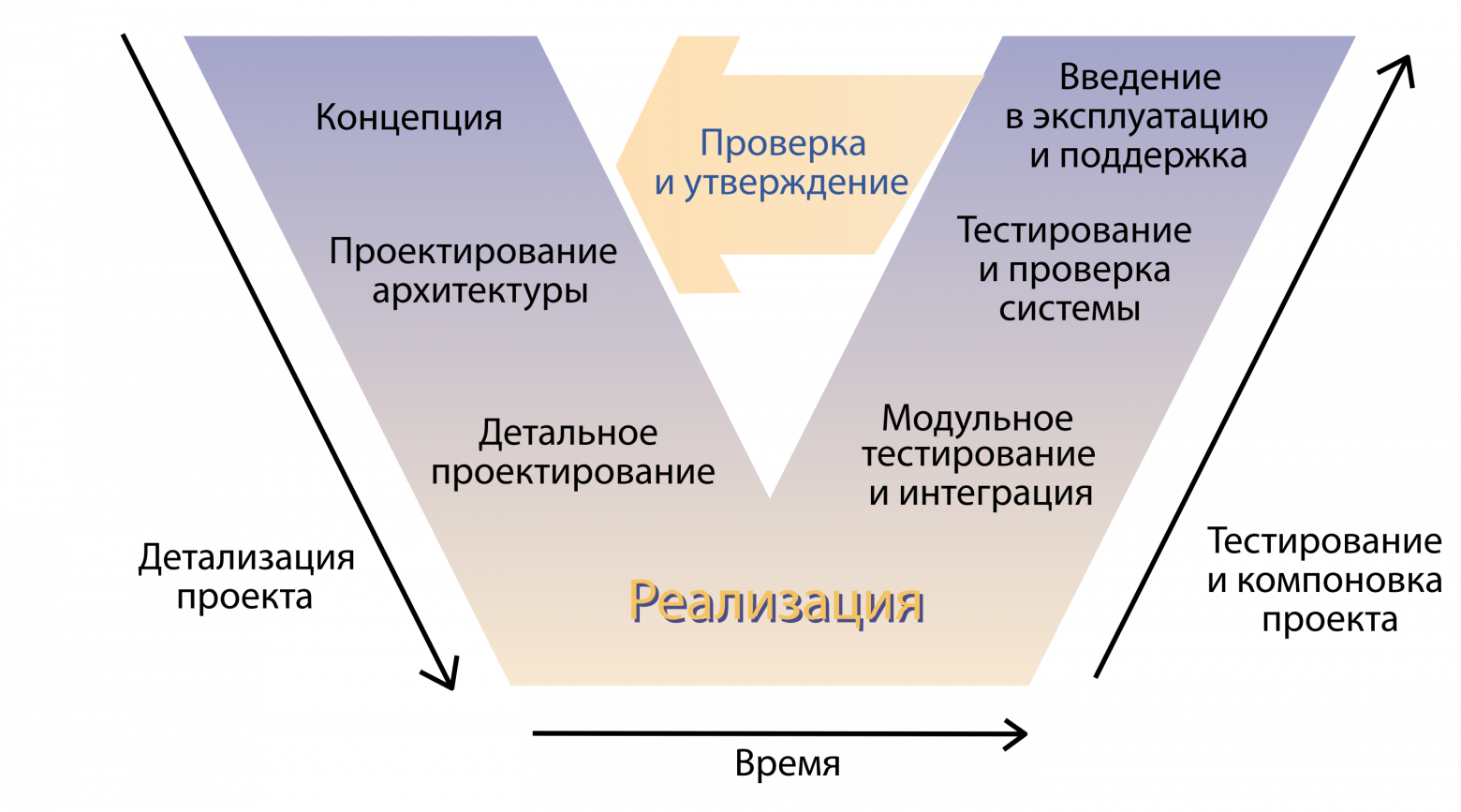
На днях мне пришло сообщение от портала Госуслуги, с предложением поучаствовать в тестировании дистанционного электронного голосования (ДЭГ). Стало интересно, начал гуглить и поисковик сразу же выдал ссылку на хабровскую статью «Обзор системы дистанционного электронного голосования ЦИК РФ». Ознакомился…и…после прочтения, испытал противоречивые чувства, которые вылились в эту статью, созданную на базе идеи, описанной мной еще в 2018 году на сайте change.org.
Подобно продвижению среди искусных воинов доспеха, с полностью отсутствующей защитой от тяжелого металлического ботинка в задней части чуть пониже спины, я искренне не понимаю, как можно было всерьез пытаться продать систему-решето из упомянутой выше статьи хабровчанам.
Ведь, очевидно, что процессе проведения выборов возникает конфликт интересов между
• власть имущими, не желающими уступать дорогу другим
• теми, кто власти пока не имеет, но желает её получить
• теми, кто хорошо устроился при действующей власти и ничего менять не хочет.
• простыми гражданами, радеющих за принципы сменяемости власти и соблюдения своих избирательных прав.
И главная проблема любой избирательной системы – представители первой группы, потому что у власть имущих есть доступ к данным всех жителей страны, которые могут быть использованы для формирования потока фейковых бюллетеней. Есть огромный админ ресурс. Есть доступ к бюджетным деньгам. Под рукой имеется силовой аппарат и карманная судебная система.
Каким образом система, предложенная ЦИК-ом защищена от организатора выборов? Да, никак. И дочитав эту статью до конца, вы поймете почему.