
Распределённые системы *
Нюансы проектирования распределенных систем
Новая программная модель чейнкода Hyperledger Fabric

Не так давно был выпущен первый релиз fabric-contract-api-go — реализации новой программной модели чейнкода по RFC 0001. Давайте разберемся, что это и как этим пользоваться.
Celery throttling — настраивам rate limit для очередей
В этой статье я покажу как решить одну из проблем, возникающих при использовании распределенных очередей задач — регулирование пропускной способности очереди, или же, более простым языком, настройка ее rate limit'a. В качестве примера я возьму python и свою любимую связку Celery+RabbitMQ, хотя алгоритм, который я использую, никак не зависит от этих инструментов и может быть реализован на любом другом стэке.

So what's the problem?
Для начала пара слов о том, какую проблему я вообще пытаюсь решить. Дело в том, что 99.9% сервисов в интернете запрещают бесконтрольно закидывать их сотнями/тысячами запросов в секунду, угрожая дать в ответ какой-нибудь 403 или 500. Нет, ну правда, жалко им чтоле? Иногда таким сервисом может выступать даже своя собственная БД… Вобщем, доверять нынче нельзя никому, поэтому приходится себя как-то сдерживать.
Конечно, если вся работа ведется внутри 1го процесса, то никакой проблемы нет, но т.к мы работаем с Celery, то у нас может быть не только N процессов (далее воркеров), но и M машин, и задача все это дело синхронизировать уже не кажется столь тривиальной.
Как миновать мины информационных технологий
 В статье сформулированы некоторые проблемы информационных технологий (ИТ) и рассматривается подход к их решению, который может быть интересен разработчикам архитектур вычислительных систем и языков программирования, а также бизнесу в сфере ИТ. Но все они, исключая некоторых, вряд ли полагают, что тут есть проблемы, по крайней мере в том, о чём повествуется в этой статье, тем более что отрасль развивается более чем. Но, хотя некоторые проблемы и не осознаются, однако решать их «ползучим образом» уже давно и постепенно приходится. А можно бы сэкономить силы и средства, если решать их осознанно сполна и сразу.
В статье сформулированы некоторые проблемы информационных технологий (ИТ) и рассматривается подход к их решению, который может быть интересен разработчикам архитектур вычислительных систем и языков программирования, а также бизнесу в сфере ИТ. Но все они, исключая некоторых, вряд ли полагают, что тут есть проблемы, по крайней мере в том, о чём повествуется в этой статье, тем более что отрасль развивается более чем. Но, хотя некоторые проблемы и не осознаются, однако решать их «ползучим образом» уже давно и постепенно приходится. А можно бы сэкономить силы и средства, если решать их осознанно сполна и сразу.Ни экономика, ни социальные коммуникации уже невозможны без использования развитых ИТ. Вот и рассмотрим, почему используемые сейчас технологии далее непригодны и на что их следует заменить. Автор будет признателен за конструктивное квалифицированное обсуждение и надеется узнать полезную информацию о современных решениях затронутых «проблем».
SPTDC 2020 — третья школа о практике и теории распределённых вычислений
Practice is when everything works but no one knows why.
In distributed systems, theory and practice are combined:
nothing works and no one knows why.
Чтобы доказать, что шутка в эпиграфе — абсолютная глупость, мы уже в третий раз проводим SPTDC (school on practice and theory of distributed computing). Об истории школы, её сооснователях Петре Кузнецове и Виталии Аксёнове, а также об участии JUG Ru Group в организации SPTDC мы уже рассказывали на Хабре. Поэтому сегодня — о школе в 2020 году, о лекциях и лекторах, а также об отличиях школы от конференции.
Школа SPTDC пройдёт с 6 по 9 июля 2020 года онлайн.
Все лекции будут на английском языке. Основные темы лекций: persistent concurrent computing, cryptographic tools for distributed systems, formal methods for verifying consensus protocols, consistency in large-scale systems, distributed machine learning.

Сразу догадались, в каком воинском звании персонажи на картинке? Я вас обожаю.
Почему может понадобиться полусинхронная репликация?

Введение
Из-за того, что на HDD может выполняться лишь порядка 400-700 операций в секунду (что несравнимо с типичными rps'ами, приходящимися на высоконагруженную систему), классическая дисковая база данных является узким горлышком архитектуры. Поэтому необходимо уделить отдельное внимание паттернам масштабирования данного хранилища.
На текущий момент имеются 2 паттерна масштабирования базы: репликация и шардирование. Шардирование позволяет масштабировать операцию записи, и, как следствие, снижать rps на запись, приходящийся на один сервер вашего кластера. Репликация позволяет делать тоже самое, но с операциями чтения. Именно этому паттерну и посвящена данная статья.
Распределение данных в Apache Ignite
Учимся разворачивать микросервисы. Часть 3. Helm

Привет, Хабр!
Это третья часть в серии статей "Учимся разворачивать микросервисы", и сегодня речь пойдет о Helm 3. В прошлой части мы создали Kubernetes конфигурацию для учебного проекта из 2 микросервисов (бекенда и шлюза) и задеплоили все это в Google Kubernetes Engine. В этой статье мы напишем Helm-чарт для нашей системы, создадим для него репозиторий на основе GitHub Pages и задеплоим проект в GKE с помощью Helm.
Башни Кремля в объятьях гидры: конференция о параллельных и распределённых вычислениях Hydra 2020
В общем, никогда такой конференции не было, и вот опять она случится. Снова с докладами на английском, потому что нет лучше языка, чтобы говорить о параллельных и распределённых вычислениях. Снова летом, 6-9 июля, потому что спикеры успевают исследовать и преподавать, например, в университетах Кембриджа, Рочестера и Санкт-Петербурга, и другое время года не для них.
На новой Гидре — более замысловатая программа, новые спикеры вместе с героями прошлого года, а также уже знакомое ощущение распределённого между участниками восторга от параллельного хардкора в трёх залах.

Как мы работаем над качеством и скоростью подбора рекомендаций

С чего начинается Elasticsearch
 Elasticsearch, вероятно, самая популярная поисковая система на данный момент с развитым сообществом, поддержкой и горой информации в сети. Однако эта информация поступает непоследовательно и дробно.
Elasticsearch, вероятно, самая популярная поисковая система на данный момент с развитым сообществом, поддержкой и горой информации в сети. Однако эта информация поступает непоследовательно и дробно.
Самое первое и главное заблуждение — "нужен поиск, так бери эластик!". Но в действительности, если вам нужен шустрый поиск для небольшого или даже вполне себе крупного проекта, вам стоит разобраться в теме поподробней и вы откажетесь от использования именно этой системы.
Логирование в микросервисной среде .Net на практике
Логирование является очень важным инструментом разработчика, но при создании распределённых систем оно становится камнем, который нужно заложить прямо в фундамент вашего приложения, иначе сложность разработки микросервисов очень быстро даст о себе знать.
В .Net Core 3 добавилась отличная возможность передачи контекста корреляции в HTTP-заголовках, поэтому если ваши приложения используют прямые HTTP-вызовы для межсервисного взаимодействия, то вы можете воспользоваться этой коробочной функцональностью. Однако, если архитектура вашего бекенда подразумевает взаимодействие через брокера сообщений (RabbitMQ, Kafka и т.п.), то вам по-прежнему необходимо озаботиться темой передачи корелляционного контекста через эти сообщения самостоятельно.
В этой статье мы возьмём простое веб-апи приложение и организуем логирование, которое будет
сохранять сквозную корелляцию между логами независимых сервисов так, чтобы можно было легко посмотреть все активности, которые были вызваны конкретным запросом с клиента
иметь единую точку входа с удобным анализом, чтобы инструментом логирования смогла пользоваться даже Поддержка, к которой летят вопросы вроде «у меня тут в приложении выскочила ошибка с таким-то айдишником запроса»
Распределенный реестр для колесных пар: опыт с Hyperledger Fabric
Ближайшие события
Учимся разворачивать микросервисы. Часть 2. Kubernetes

Привет, Хабр!
Это вторая часть из серии статей "Учимся разворачивать микросервисы". В предыдущей части мы написали 2 простеньких микросервиса — бекенд и шлюз, и разобрались с тем, как их упаковать в docker-образы. В этой же статье мы будем организовывать оркестрацию наших docker-контейнеров с помощью Kubernetes. Мы последовательно составим конфигурацию для запуска системы в Minikube, а затем адаптируем ее для деплоя в Google Kubernetes Engine.
Service Discovery в распределенных системах на примере Consul. Александр Сигачев
Предлагаю ознакомиться с расшифровкой доклада Александра Сигачева Service Discovery в распределенных системах на примере Consul.
Service Discovery создан для того, чтобы с минимальными затратами можно подключить новое приложение в уже существующее наше окружение. Используя Service Discovery, мы можем максимально разделить либо контейнер в виде докера, либо виртуальный сервис от того окружения, в котором он запущен.
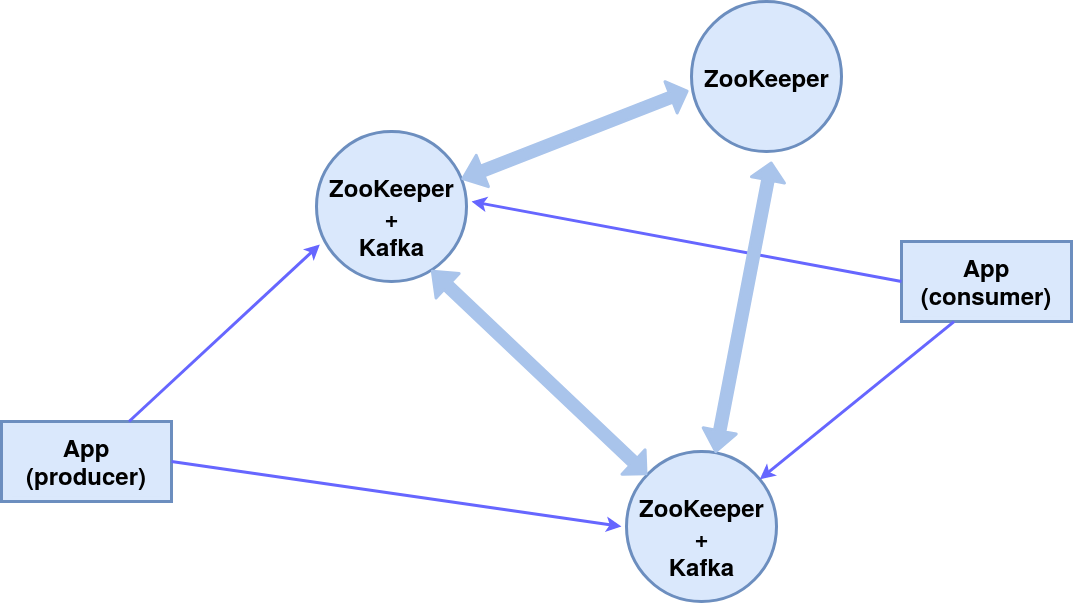
Повторная обработка событий, полученных из Kafka

Привет, Хабр.
Недавно я поделился опытом о том, какие параметры мы в команде чаще всего используем для Kafka Producer и Consumer, чтобы приблизиться к гарантированной доставке. В этой статье хочу рассказать, как мы организовали повторную обработку события, полученного из Kafka, в результате временной недоступности внешней системы.
Современные приложения работают в очень сложной среде. Бизнес-логика, обернутая в современный технологический стек, работающая в Docker-образе, который управляется оркестратором вроде Kubernetes или OpenShift, и коммуницирующая с другими приложениями или enterprise-решениями через цепочку физических и виртуальных маршрутизаторов. В таком окружении всегда что-то может сломаться, поэтому повторная обработка событий в случае недоступности одной из внешних систем — важная часть наших бизнес-процессов.
«Hadoop. ZooKeeper» из серии Технострима Mail.Ru Group «Методы распределенной обработки больших объемов данных в Hadoop»
Предлагаю ознакомиться с расшифровкой лекции "Hadoop. ZooKeeper" из серии "Методы распределенной обработки больших объемов данных в Hadoop"
Что такое ZooKeeper, его место в экосистеме Hadoop. Неправда о распределённых вычислениях. Схема стандартной распределённой системы. Сложность координации распределённых систем. Типичные проблемы координации. Принципы, заложенные в дизайн ZooKeeper. Модель данных ZooKeeper. Флаги znode. Сессии. Клиентский API. Примитивы (configuration, group membership, simple locks, leader election, locking без herd effect). Архитектура ZooKeeper. ZooKeeper DB. ZAB. Обработчик запросов.
Как создать децентрализованное приложение, которое масштабируется? Используйте меньше блокчейна
Нет, запуск децентрализованного приложения (dapp) на блокчейне не приведет к успешному бизнесу. На самом деле, большинство пользователей даже не задумывается работает ли приложение на блокчейне — они просто выбирают продукт, который дешевле, быстрее и проще.
К сожалению, даже если у блокчейна есть свои уникальные особенности и преимущества, большинство приложений, которые работают на нем, гораздо дороже, медленнее и менее понятны, чем их централизованные конкуренты.

Довольно часто в whitepaper'ах приложений, которые построены на блокчейне, можно найти параграф, в котором сказано: "блокчейн дорогой и не способен поддерживать требуемое число транзакций в секунду. К счастью, много умных людей работает над масштабированием блокчейна и к моменту запуска нашего приложения он станет достаточно масштабируем".
В одном простом параграфе, разработчик dapp'а может отказаться от более глубокого обсуждения проблем масштабируемости и альтернативных решений проблем. Это часто приводит к неэффективной архитектуре, где бэкендом и ядром приложения служат смарт-контракты, работающие на блокчейне.
Однако, существуют еще неопробованные подходы в архитектуре децентрализованных приложений, которые позволяют гораздо лучше масштабироваться, благодаря уменьшению зависимости от блокчейна. Например, Blockstack работает над архитектурой, где большинство данных и логики приложения хранится за пределами блокчейна.
Давайте сперва глянем на более традиционный подход, в котором блокчейн используется, как прямой посредник между пользователями приложения, и который не особо хорошо масштабируется.
Пример реактивного приложения Spring (релиз от 14.01.2020)
Так как начинается очередной удивительный год разработки и улучшений в экосистеме Spring, хочу поделиться с вами обновленным примером приложения, демонстрирующего часть прогресса, достигнутого в портфеле проектов Spring в части поддержки Реактивной модели программирования.
Образец приложения BookStore Service Broker был обновлен для демонстрации интеграции нескольких различных проектов Spring, включая Spring Cloud Open Service Broker, Spring Data, Spring Security, Spring HATEOAS и, конечно, Spring WebFlux и Spring Boot. Все эти проекты имеют версии GA, включающие Реактивную поддержку и готовые к продакшену в ваших собственных приложениях и сервисах.
Переведено @middle_java
Блеск и нищета atomic swaps
Главная мотивация любого специалиста по безопасности— желание избежать ответственности.
Провидение было милостиво, я покинул ICO, не дожидаясь первой необратимой транзакции, но вскоре обнаружил себя за разработкой криптобиржи.