Система управления конфигурацией сети фильтрации Qrator
6 мин
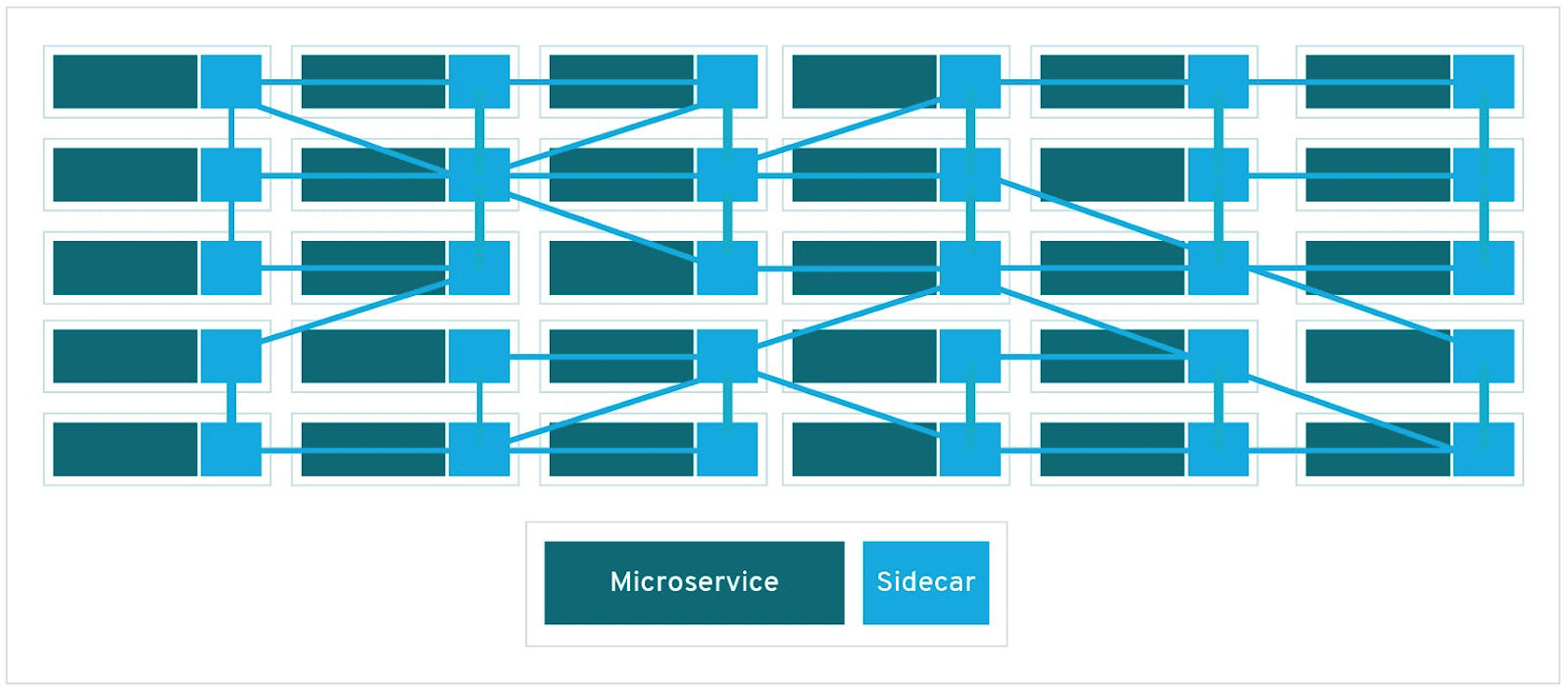
TL;DR: Описание клиент-серверной архитектуры нашей внутренней системы управления конфигурацией сети, QControl. В основе лежит двухуровневый транспортный протокол, работающий с упакованными в gzip сообщениями без декомпрессии между эндпойнтами. Распределенные роутеры и эндпойнты получают конфигурационные апдейты, а сам протокол позволяет установку локализованных промежуточных релеев. Система построена по принципу дифференциального бэкапа (“recent-stable”, объясняется ниже) и задействует язык запросов JMESpath вместе с шаблонизатором Jinja для рендера конфигурационных файлов.
Qrator Labs управляет глобально распределенной сетью нейтрализации атак. Наша сеть работает по принципу anycast, а подсети анонсируются посредством BGP. Будучи BGP anycast-сетью, физически расположенной в нескольких регионах Земли мы можем обработать и отфильтровать нелегитимный трафик ближе к ядру интернета — Tier-1 операторам.
С другой стороны, быть географически распределенной сетью непросто. Коммуникация между сетевыми точками присутствия критически важна для провайдера услуг безопасности, для того чтобы иметь согласованную конфигурацию всех узлов сети, обновляя их своевременным образом. Поэтому с целью предоставить максимальный возможный уровень основной услуги для потребителя нам необходимо было найти способ надежно синхронизировать конфигурационные данные между континентами.
В начале было Слово. Оно быстро стало коммуникационным протоколом, нуждающимся в апдейте.









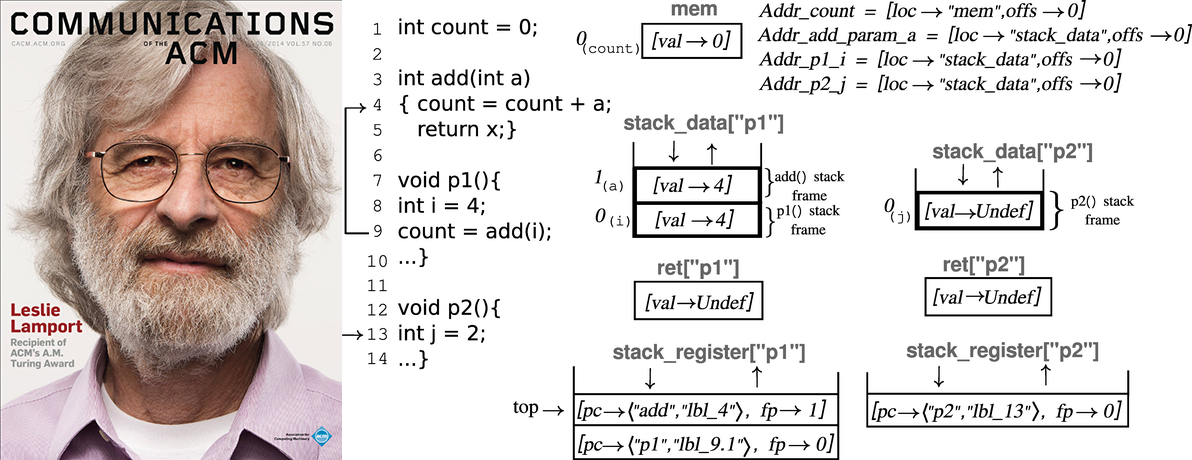
 Клифф Клик — CTO компании Cratus (IoT сенсоры для улучшения процессов), основатель и сооснователь нескольких стартапов (включая Rocket Realtime School, Neurensic и H2O.ai) с несколькими успешными экзитами. Клифф написал свой первый компилятор в 15 лет (Pascal для TRS Z-80)! Наиболее известен за работу над С2 в Java (the Sea of Nodes IR). Этот компилятор показал миру, что JIT может производить качественный код, что стало одним из факторов становления Java как одной из основных современных программных платформ. Потом Клифф помог компании Azul Systems построить 864-ядерный мейнфрейм с софтом на чистой Java, который поддерживал паузы GC на 500-гигабайтной куче в пределах 10 миллисекунд. Вообще, Клифф успел поработать над всеми аспектами JVM.
Клифф Клик — CTO компании Cratus (IoT сенсоры для улучшения процессов), основатель и сооснователь нескольких стартапов (включая Rocket Realtime School, Neurensic и H2O.ai) с несколькими успешными экзитами. Клифф написал свой первый компилятор в 15 лет (Pascal для TRS Z-80)! Наиболее известен за работу над С2 в Java (the Sea of Nodes IR). Этот компилятор показал миру, что JIT может производить качественный код, что стало одним из факторов становления Java как одной из основных современных программных платформ. Потом Клифф помог компании Azul Systems построить 864-ядерный мейнфрейм с софтом на чистой Java, который поддерживал паузы GC на 500-гигабайтной куче в пределах 10 миллисекунд. Вообще, Клифф успел поработать над всеми аспектами JVM.