У вас бывает такой сон: вы оказываетесь на экзамене или выступаете перед некоторой аудиторией, и вдруг осознаете, что вы вообще не готовились и сейчас прийдется импровизировать. Именно в такой ситуации, но не во сне, а в реале, я оказался перед майскими праздниками в Москве, куда прилетел из Калифорнии, чтобы провести трехдневный семинар для тщательно отобранных школьников ведущих московских физматшкол. Под эгидой РОСНАНО, в гимназии РУТ (МИИТ) и в присутствии преподавателей из МИЭТ, МИРЭА, МИФИ, МЭИ и ВШЭ МИЭМ.
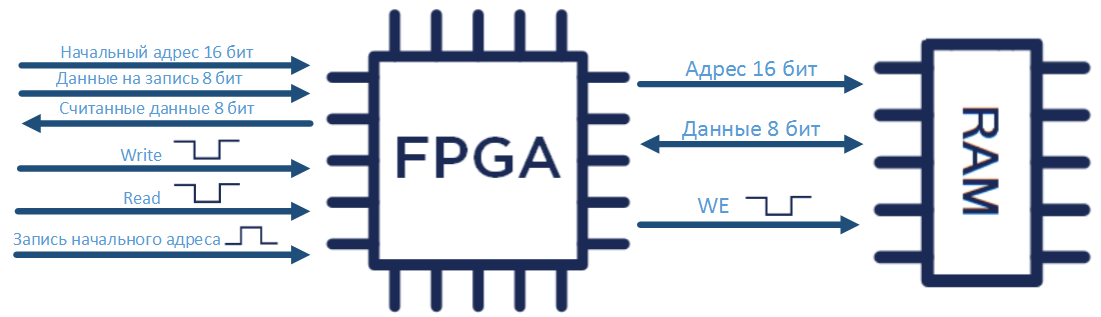
Московские коллеги на меня понадеялись, и теоретически я должен был бы привезти с собой пошаговые инструкции и примеры разнообразных упражнений на плате с микросхемой реконфигурируемой логики. Реально у меня была куча каких-то примеров для других плат, из которых я в суматохе перелетов и других мероприятий ничего не построил.
Поэтому я взял некий универсальный пример, который написал полтора года назад, сидя в самолете Алма-Ата — Астана, выкинул из примера все внутренности и начал со школьниками его наполнять, без жесткого плана чем. И как ни странно — это получилось. В процессе наполнения возникли поучительные моменты цифровой схемотехники и языка описания аппаратуры Verilog, которые при планировании бы не возникли.
4 июня я с коллегами по Wave Computing провожу похожий семинар в Лас-Вегасе, но только для взрослых, а 8-19 июля помогаю МИЭТ провести летнюю школу в Зеленограде. Планы этих мероприятий (не окончательные, а для обсуждения в группе преподавателей и инженеров, в том числе здесь, на Хабре) — в конце поста.


 На картинке Linux kernel шлёт вам привет через GPIO.
На картинке Linux kernel шлёт вам привет через GPIO.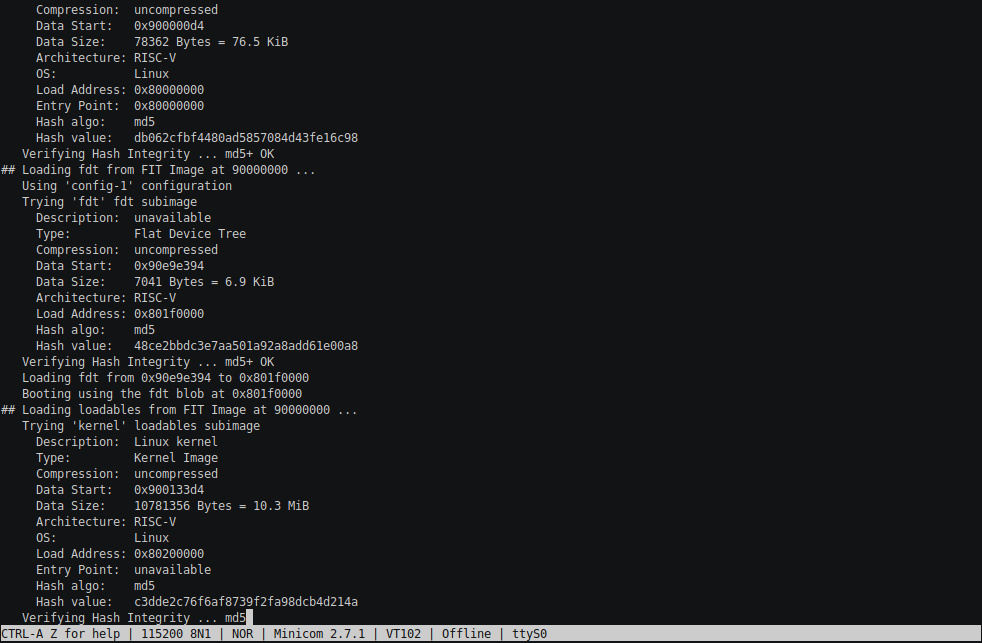 В
В 
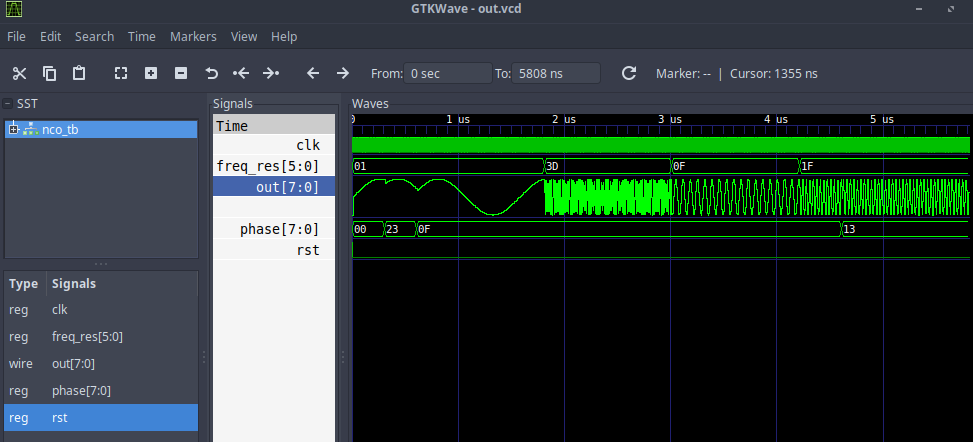
 В
В