Не-фон неймановский компьютер на базе комбинаторной логики
8 мин
Здравствуйте. В этой статье я расскажу про свой хобби-проект не-фон неймановского компьютера. Архитектура соответствует функциональной парадигме: программа есть дерево применений элементарных функций друг к другу. Железо — однородная статическая сеть примитивных узлов, на которую динамическое дерево программы спроецировано, и по которой программа «ползает» вычисляясь.

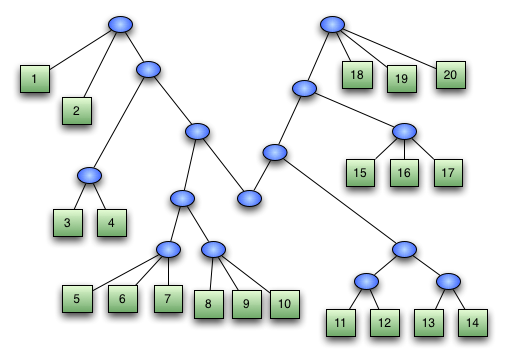
Примерно так работает дерево, только здесь для наглядности вычисляются арифметическое выражение, а не комбинаторное; шаг на рисунке — один такт машины.
Сейчас готов ранний прототип, существующий как в виде потактового программного симулятора, так и в виде реализации на ПЛИС.
Примерно так работает дерево, только здесь для наглядности вычисляются арифметическое выражение, а не комбинаторное; шаг на рисунке — один такт машины.
Сейчас готов ранний прототип, существующий как в виде потактового программного симулятора, так и в виде реализации на ПЛИС.

 В последнее время определенную известность получили
В последнее время определенную известность получили