Обзор современных подходов персонализации диффузионных нейронных сетей
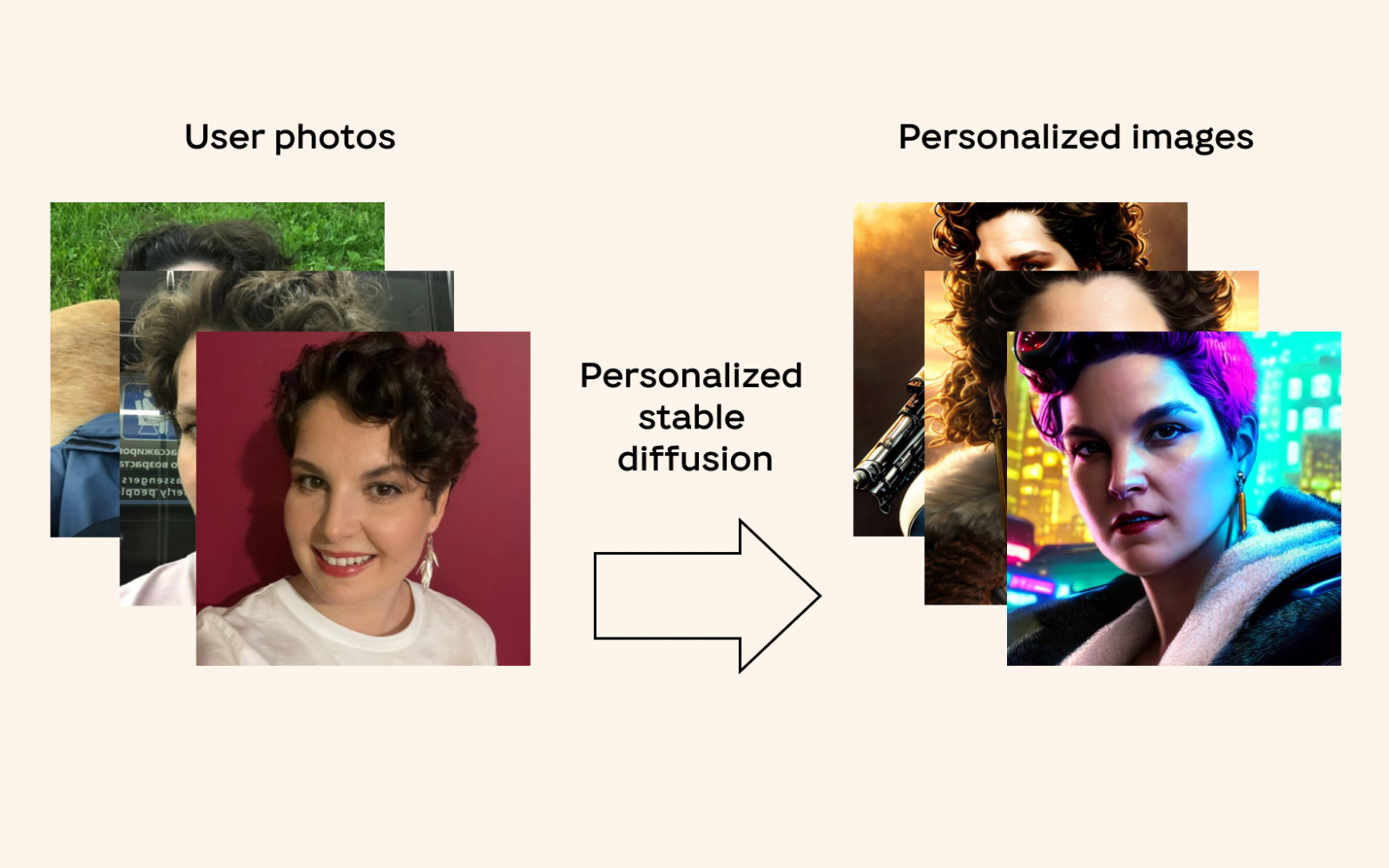
Задача персонализации text-to-image модели состоит в донастройке предобученной нейронной сети так, чтобы она могла генерировать изображения заданного объекта в выбранных сценах. Несмотря на то, что подходы к решению этой задачи существуют, для их применения в высоконагруженных системах необходимо решить ряд проблем: большое время дообучения, высокие требования к видеопамяти, неспособность точно захватывать детали целевого объекта и др.
Меня зовут Сергей Михайлин. Я разработчик группы машинного обучения в ОК. В данной статье дан обзор современных подходов к персонализации text-to-image моделей на базе открытой архитектуры Stable Diffision. Мы приводим технические подробности каждого подхода и анализируем его применимость в реальных высоконагруженных системах. На основании собственных экспериментов по персонализации text-to-image моделей мы выделяем список возникающих при решении этой задачи проблем и перспективных способов их решения.