Потихоньку начнём разговор для понимания приёмов и возможностей нейросетевых инструментов. Они с нами навсегда, неплохо бы разобраться в самом начале.
Для примера выберем, конечно же, девчонок.
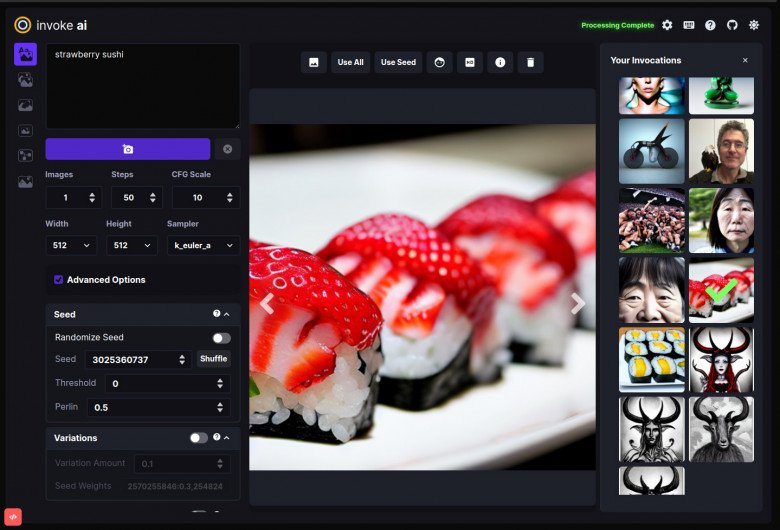
Prompth: full frontal, stunning blonde, (perfect face), suggestive, bright smile, gorgeous hair, squat,
Negative prompt: paint, anime, cartoon, art,drawing,3d render, digital painting, body out of frame, ((deformed)), (cross–eyed), (closed eyes), blurry, (bad anatomy), ugly, disfigured, ((poorly drawn face)), (mutation), (mutated), (extra limbs), (bad body)
Перед началом генерирования у вас есть много разных настроек и возможностей . Например запрос может быть и отрицательным - negative prompt, фактически запрет, очень мощный инструмент, в котором описывается чего бы вы не хотели видеть в результате. Как правило туда включают все заклинания призванные исключить появление в результирующем изображении шестипалых рук и множества других мутаций, которые только отнимают ценное время. Рисовать правильные пальцы - это вообще больное место нейросетей, поэтому их часто и не видно в сгенерированных изображениях. Впрочем, продолжим.
На картинке ниже результат работы нейросети от компании StableDiffusion, а именно запрос к парсеру img2img — инструменту, который служит для доработки уже имеющегося изображения. В качестве исходника, был взят мем из сети Интернет. Текст запроса: