Беспростойная миграция RabbitMQ в Kubernetes
5 мин
Туториал

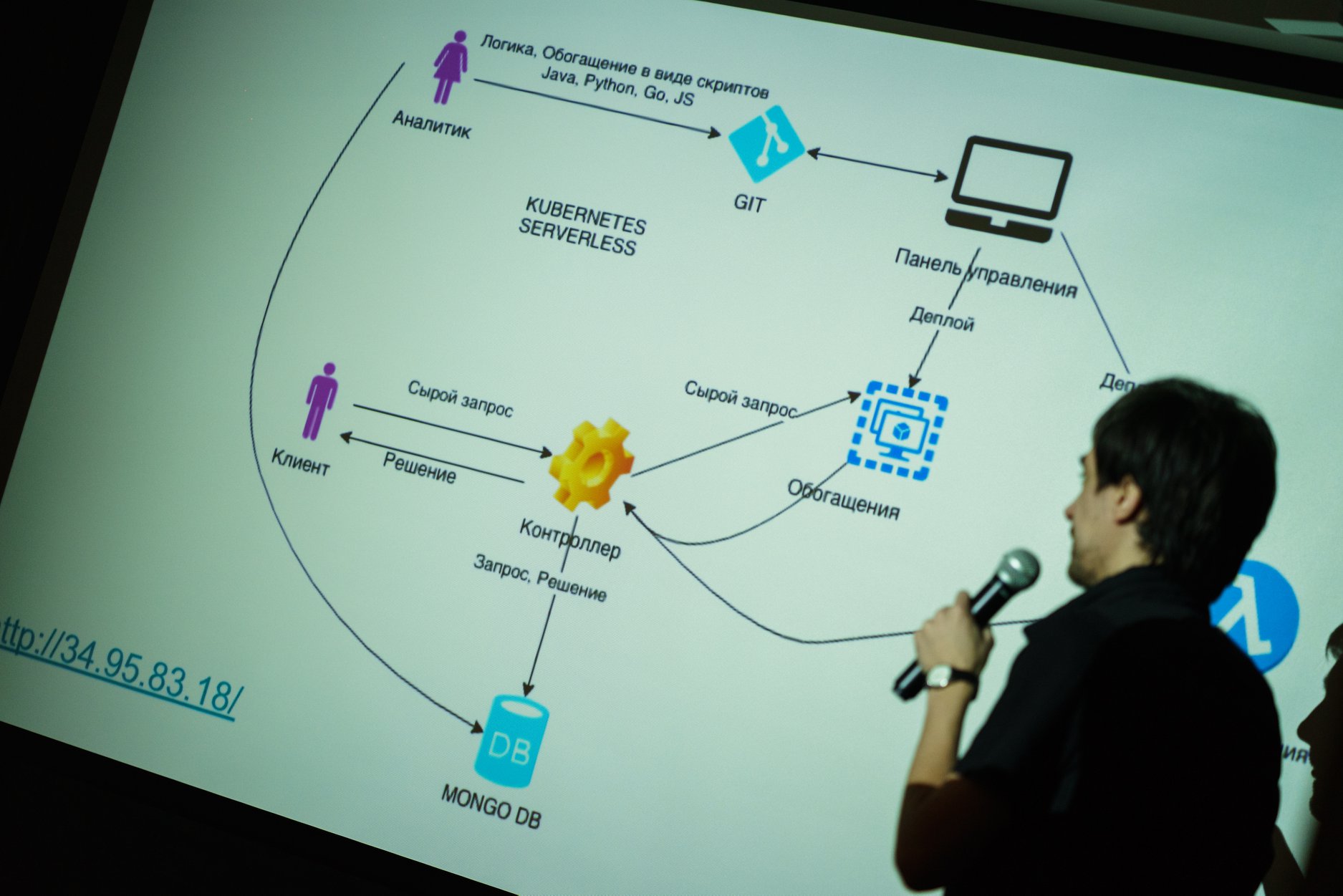
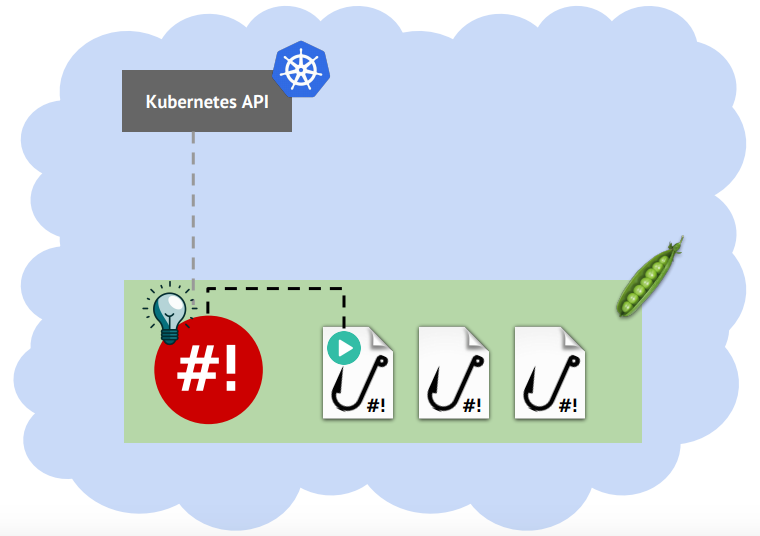
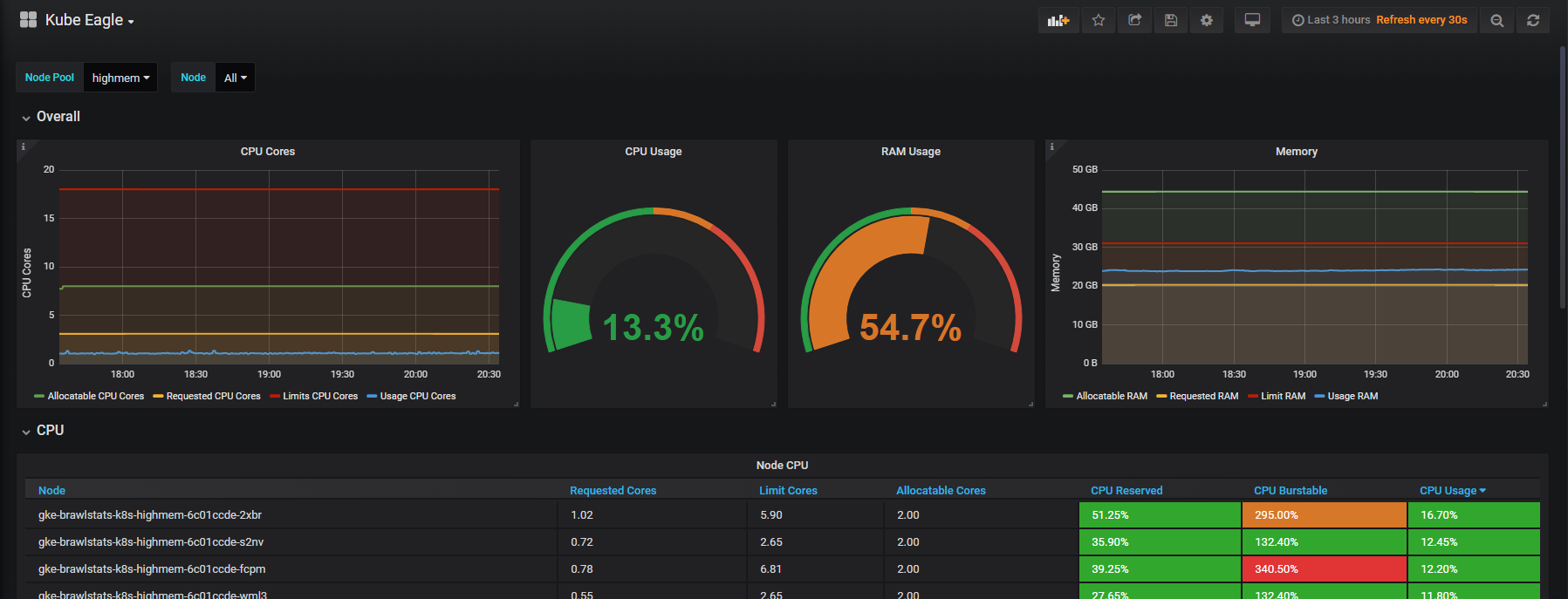
RabbitMQ – написанный на языке Erlang брокер сообщений, позволяющий организовать отказоустойчивый кластер с полной репликацией данных на несколько узлов, где каждый узел может обслуживать запросы на чтение и запись. Имея в production-эксплуатации множество кластеров Kubernetes, мы поддерживаем большое количество инсталляций RabbitMQ и столкнулись с необходимостью миграции данных из одного кластера в другой без простоя.