
Детекция объектов. R-CNN, Fast R-CNN, Faster R-CNN. Часть 1
Средний
5 мин

Кто такой детектор?
Данная статья посвящена постановке задачи детекции и обзору первых двухстадийных детекторов, таких как: R-CNN, Fast R-CNN и Faster RCNN.
Кто такой детектор?
Данная статья посвящена постановке задачи детекции и обзору первых двухстадийных детекторов, таких как: R-CNN, Fast R-CNN и Faster RCNN.

Паралич сети - это явление, при котором глубокие слои не обучаются. Это происходит из-за затухания градиента при обратном распространении ошибки. Затухание градиента может возникнуть из-за большой глубины сети или больших выходных значений.
Цель статьи - объяснить проблему, причины ее возникновения и показать несколько решений. Дополнительно статья связывает редкое понятие «паралича сети» и распространённое понятие «затухания градиента».

Цель данной работы – оценить возможность создания эффективной системы распознавания дефектов рельсов по дефектограммам ультразвукового контроля методами ML

Этой весной мы проведём ряд конференций, и среди них целых три новых (про Go, ML и безопасность приложений). Одни мероприятия будут полностью онлайновыми, а другие пройдут в Москве (но и к таким возможно подключиться удалённо).
Все билеты уже в продаже, а в случае с частью конференций ещё не поздно подать заявку на доклад. Лайфхак: тебе не понадобится покупать билет на конференцию, если сам на ней выступаешь! Хотя, конечно, для спикеров это обычно не главное: важнее, что пока объясняешь другим тему, сам её понимаешь куда лучше прежнего.
Этот пост — сразу обо всём конференционном сезоне:
• Flow (системный и бизнес-анализ), 12 марта, онлайн
• SafeCode (безопасность приложений), 13-14 марта, онлайн
• GoFunc (разработка на Go), 14-15 марта, онлайн
• TechTrain (профессиональный рост в IT), 6 апреля
• HolyJS (JS-разработка), 15 апреля в онлайне и 26-27 апреля в Москве
• Heisenbug (тестирование), 16 апреля в онлайне и 22-23 апреля в Москве
• JPoint (Java-разработка), 17 апреля в онлайне и 24-25 апреля в Москве
• Mobius (мобильная разработка), 14 мая в онлайне и 20-21 мая в Москве
• C++ Russia (понятно что), 15 мая в онлайне и 22-23 мая в Москве
• I'ML (работа с ML), в июне, онлайн

Привет, Хабр! Меня зовут Никита Мелентьев, я Lead Data Scientist в команде дата-акселератора «Леруа Мерлен». Сегодня мы с коллегой Алексеем Зубаревым поделимся нашим кейсом по использованию ML для прогнозирования оттока и возврата профессиональных (ПРО) клиентов в «Леруа Мерлен».
Коснемся не только модели прогнозирования, но также подхода к построению ML-продуктов, который мы используем: от оценки эффекта перед разработкой — до продуктивизации сервиса и интеграции в системы компании. Разберем методологии разметки ушедших клиентов и A/B-тестирования. И, конечно, затронем тему метрик. Оставайтесь, будет интересно!

Если вы не провели последние два года на ферме в Сибири, вы, вероятно, слышали о Stable Diffusion или пробовали генерировать изображения с помощью моделей, вроде Dall-e или Midjourney. Они становятся все лучше каждый день, и по качеству уже сравнимы с людьми, а во многих аспектах даже лучше (например, им не нужно платить).
Исследования в области создания видео уже идут полным ходом во многих лабораториях и компаниях, так что это лишь вопрос времени, когда генеративные модели сместят людей с очередного столпа на котором держится наше общества — порно. Я не вижу чтобы кто то поднимал тревогу об огромном количестве людей, которые потеряют работу из-за этого. Я не такой бессердечный, поэтому, прежде чем наступил этот печальный момент, я решил принять меры и создать базовое руководство, которое даже работник индустрии для взрослых сможет понять и использовать, чтобы оставаться в игре. Давайте посмотрим, что к чему.

Майнинг и использование для майнинга в этой статье не обсуждается.
У меня есть пара старых статей (про A100, и про 3090 и A10) и также вот есть тоже старое, но всё еще неплохое и актуальное сравнение карточек для расчетов от Selectel. С тех пор прошло примерно два года и пора написать что-то новенькое и попробовать новые ускорители для расчетов. Да, это всё ещё статья про карточку Nvidia, не AMD и не Intel, и не про китайцев и какие-то модные большие чипы, увы.
С тех пор появились новые карточки уже аж двух новых поколений - Ada Lovelace и Hopper. При этом Hopper вроде как должны были прийти на замену очень удачному поколению Ampere (это древняя традиция Nvidia - за супер успешным поколением следует менее удачное), но не пришли. Но возможно из-за торговых войн с Китаем карточки поколения Hopper стали выдавать только нужным вендорам и в виде собранных систем и при этом запретили экспорт в Китай.
В этой статьей мы разберем первые впечатления от карточки NVIDIA RTX 5000 Ada Generation (AD103), но начнем с небольшой дозы юмора.

В данной статье я подробно опишу один из методов обучения с подкреплением - обучение на основе функции полезности (Q-обучение или Q-learning).

Всем привет! Меня зовут Артём Важенцев, я аспирант в Сколтехе и младший научный сотрудник AIRI. Наша группа занимается исследованием и разработкой новых методов оценивания неопределенности для языковых моделей. Этим летом мы опубликовали две статьи на ACL 2023.
Про одну из них я уже рассказывал в одном из предыдущих текстов — там мы описали новый гибридный метод оценивания неопределенности для задачи выборочной классификации текстов. Другая же статья про то, как мы адаптировали современные методы оценивания неопределенности на основе скрытого представления модели для задачи генерации текста, а так же показали их высокое качество и скорость работы для задачи обнаружения примеров вне обучающего распределения. Ниже я хотел бы подробнее рассказать об используемых методах и результатах, которые мы получили.

Привет!
Концепция дифференциальной приватности впервые появилась в начале 2000-х. Она позволяет проводить анализ данных, сохраняя информацию о личности индивидов неприкосновенной. В машинном обучение это означает возможность обучать модели, делающие общие выводы, не раскрывая информацию о конкретных индивидах в наборе данных.

Привет, Хабр! Меня зовут Наталья Макарова, я ведущий разработчик команды геоданных в CDEK. В этой статье расскажу, как мы с помощью ML решили проблему, не дававшую нашей компании перейти на автоматическую маршрутизацию курьеров.
Мы умеем отслеживать прохождение грузом всей транспортной цепочки, включая промежуточные склады. Но посылку нужно ставить на конкретный маршрут до того, как весь груз придет на склад доставки. И даже до того, как он попадет в ERP‑систему СDEK (посылки оформят в офисах). То есть задача такая: определить, на какой маршрут поставить конкретный заказ до того, как появился сам маршрут!
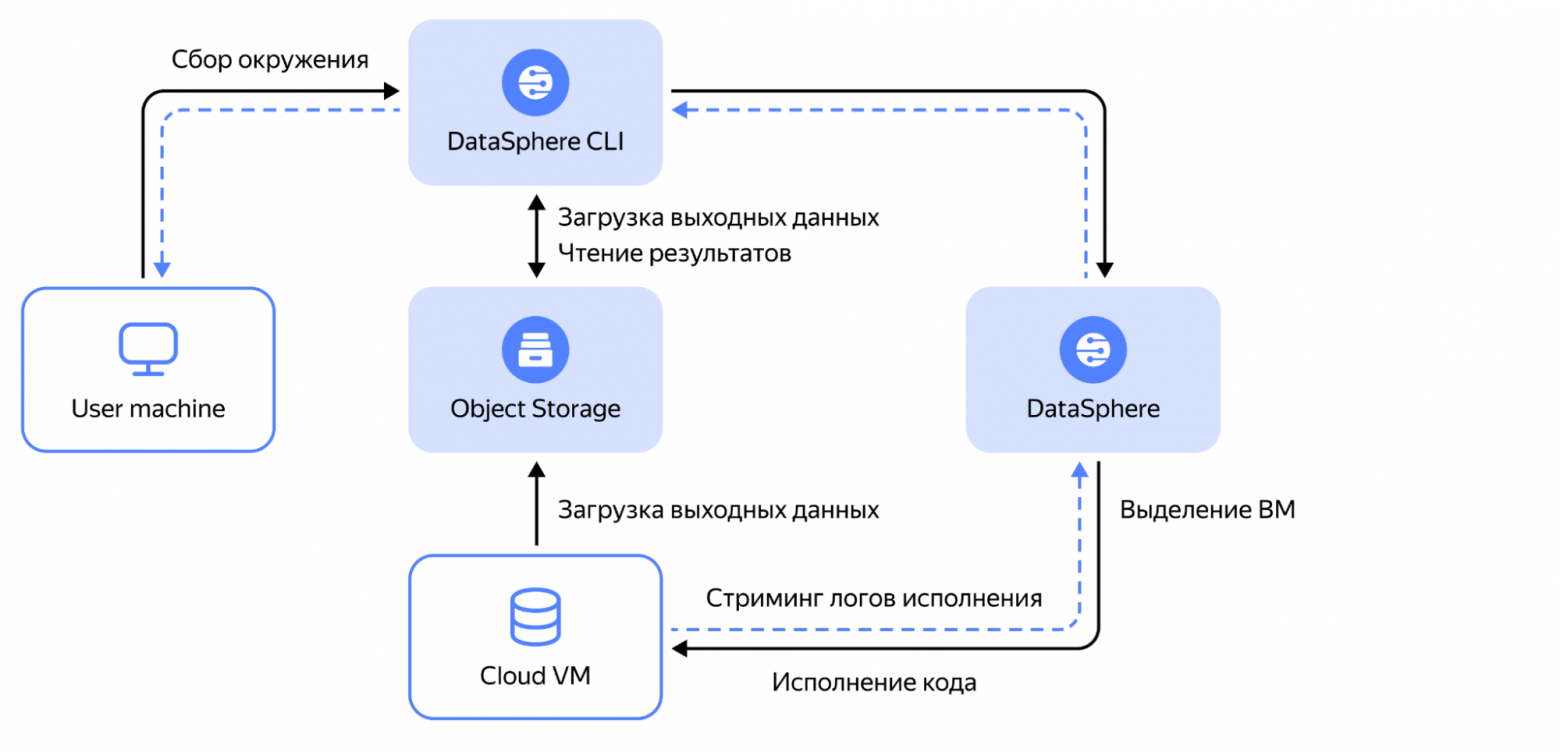
В сообществе ML-инженеров и дата-сайентистов популярны инструменты с быстрой обратной связью наподобие JupyterLab — они помогают легко и без лишних обвязок проверять гипотезы или создавать прототипы. Но довольно часто бывает, что при разработке ML-пайплайна, будь то инференс или обучение модели, хочется пользоваться установленной локально полноценной IDE, в которой открыт проект со многими зависимостями, окружением, сложной структурой. При написании кода и его отладке хочется пользоваться дебагером и уметь быстро менять код, а при запуске — скейлить ресурсы исполнения и не думать о том, как перенести код и окружение на продакшн-сервера. Всех этих возможностей в Jupyter-экосистеме из коробки нет, поэтому разработчикам часто приходится создавать костыли.
Помочь в решении этих задач могут инструменты для удалённого исполнения кода в ML. Сегодня на конкретном примере покажу, как устроен и как работает один из таких инструментов, созданный нами для пользователей облака, — DataSphere Jobs. А в следующий раз вместе с моими коллегами рассмотрим опенсорс-инструменты для подобных задач.

Сотрудник надомной мануфактуры мисье Жибер доходчиво объясняет, в каком положении он оказался, когда увидел сколько ткани выпускает недавно построенная неподалеку фабрика

На связи команда курсов Data Science OTUS. В данной статье Product Manager Мария Кузьмина собрала аналитические выкладки c hh, бизнес-секреты от Tinkoff и комментарии профессионалов о том, что они думают о специфике рынка труда в Data Sciencе/ML, а также какой стек нужен для разных позиций.
Согласно прогнозу американской консалтинговой компании Gartner, мировые расходы на информационные технологии в 2024 году увеличатся на 8% и составят порядка 5,1 трлн долларов. Это говорит об очередном повышении спроса на ИТ-специалистов в мире и росте профильных вакансий на рынке труда. А среди языков программирования 1‑е место в области Data Science / ML Engineering занимает Python.
На российском рынке труда, есть хорошие новости для кандидатов из возрастной группы 35+. Ситуация в России в 2023 году характеризовалась значительным дефицитом кадров, который связывают в том числе с последствием демографического спада 90-ых годов. Уровень дефицита достиг максимальных значений за всю историю наблюдений, с hh.индексом опустившимся до 3,1 пункта. Количество вакансий увеличилось на 76% по сравнению с началом 2021 года, в то время как число резюме за этот же период выросло всего на 15%. Рекрутеры прогнозируют и рекомендуют компаниям расширять привычную воронку найма и смотреть на кандидатов вне определенных негласных стереотипов даже в ИТ сегменте.
Средняя зарплата российского специалиста по Data Science / ML enginer / Аналитика-разработчика варьируется от 115 до 180 тысяч рублей, причем джуниоры зарабатывают от 60 до 80 тыс. руб., миддлы — от 100 до 250 тыс. руб., а синьоры — от 250 тыс. руб. и выше. Ведущие специалисты с опытом около 5-6 лет могут зарабатывать до 400-500 тыс. рублей в месяц.


По прогнозам к 2050 году смертность от инфекционных и бактериальных заболеваний, не поддающихся лечению в связи с устойчивостью возбудителей к антибактериальным препаратам, составит 10 млн человек в год и выйдет на одно из лидирующих мест наряду с сердечно-сосудистыми и онкологическими заболеваниями. Основным объектом данного исследования как раз является один из таких типов бактерий – метициллинрезистентный золотистый стафилококк (MRSA), устойчивый к стандартным лекарственным препаратам, известным и применяемым на практике антибиотикам.
Данной проблемой уже долгие годы занимаются ученые и медицинские организации по всему миру, и, наконец, с мертвой точки позволили сдвинуться силы искусственного интеллекта и глубокого обучения, основанного на применении графовых моделей нейронных сетей, знакомых для каждого из нас.
Ученым из Массачусетского университета удалось осуществить данное исследование за счет использования глубокого обучения. Помимо того, что новый класс антибиотиков способен уничтожать MRSA бактерии, он также обладает очень низкой токсичностью по отношению к клеткам человека, что является безупречным результатом.
В данной статье я подробнее расскажу о методах и ходе данного исследования, от зарождения идеи, до ее реализации и практических результатов.
Приятного прочтения! :)

Такие истории редко оказываются публичными: мало кто любит хвастаться тем, как их пошифровали (даже если это хэппиэнд). Но пора признать — эти истории есть, они ближе, чем мы думаем, и их абсолютно точно в разы больше, чем все привыкли считать. Шифровальщики все еще остаются в топе угроз среди атак на организации. Одну из таких атак сумела запечатлеть система поведенческого анализа сетевого трафика PT Network Attack Discovery (PT NAD), которая в это время пилотировалась в компании. И если бы только оператор SOC обратил внимание на алерты в интерфейсе новой системы… но история не терпит сослагательного наклонения.
Здравствуйте, уважаемые читатели!
Тема сегодняшней статьи будет несколько нестандартная, однако, безусловно связанная с информационными технологиями, нейросетями и технологическим гигантом нашего времени – компанией Яндекс.
Сразу хочу отметить – я отлично осознаю факт того, что Хабр не является площадкой для сведения счетов, размещения жалоб или ломания копий. И идея о том, чтобы написать свой отзыв об опыте общения с компанией Яндекс так и осталась бы идеей, лежащей где-то чуть ли не на дальней полочке в моем мозге, если бы буквально на днях, 18.01.2024 г., спустя 5 месяцев после того, как поступили со мной, я не увидел полностью аналогичный случай, о котором написали в сети. См. ссылку ниже:
https://journal.tinkoff.ru/kak-ia-pytalas-ustroitsia-na-rabotu-v-iandeks/
Прочитав пост, я понял, что эпопея “Яндекс-швырялово” длится уже около полугода и при этом все её организаторы чувствуют себя предельно комфортно, поэтому я был просто вынужден расчехлить перо.

В вводной части обзора мы познакомились с концепцией Retrieval Augmented Generation (RAG) и её расширением через методологию RAGAS (Retrieval Augmented Generation Automated Scoring). Мы разобрались, как RAGAS подходит к процессу оценки эффективности и точности RAG-систем.
В этой части мы более подробно рассмотрим техническую сторону RAGAS. Как обычно, начнем с более простых и интуитивно понятных примеров, потом перейдем к более сложным сценариям.