
Хабр, привет.
Как вы знаете, для обучения глубоких нейронных сетей оптимально использовать машины с GPU. Наши образовательные программы всегда имеют практический уклон, поэтому для нас было обязательно, чтобы во время обучения у каждого участника была своя виртуальная машина с GPU, на которой он мог решать задачи во время занятий, а также лабораторную работу в течение недели. О том, как мы выбирали инфраструктурного партнера для реализации наших планов и подготавливали среду для наших участников, и пойдет речь в нашем посте.
Как вы знаете, для обучения глубоких нейронных сетей оптимально использовать машины с GPU. Наши образовательные программы всегда имеют практический уклон, поэтому для нас было обязательно, чтобы во время обучения у каждого участника была своя виртуальная машина с GPU, на которой он мог решать задачи во время занятий, а также лабораторную работу в течение недели. О том, как мы выбирали инфраструктурного партнера для реализации наших планов и подготавливали среду для наших участников, и пойдет речь в нашем посте.
 Приходит ветеринар к терапевту. Терапевт: — На что жалуетесь? Ветеринар: — Нет, ну так каждый может!
Приходит ветеринар к терапевту. Терапевт: — На что жалуетесь? Ветеринар: — Нет, ну так каждый может!






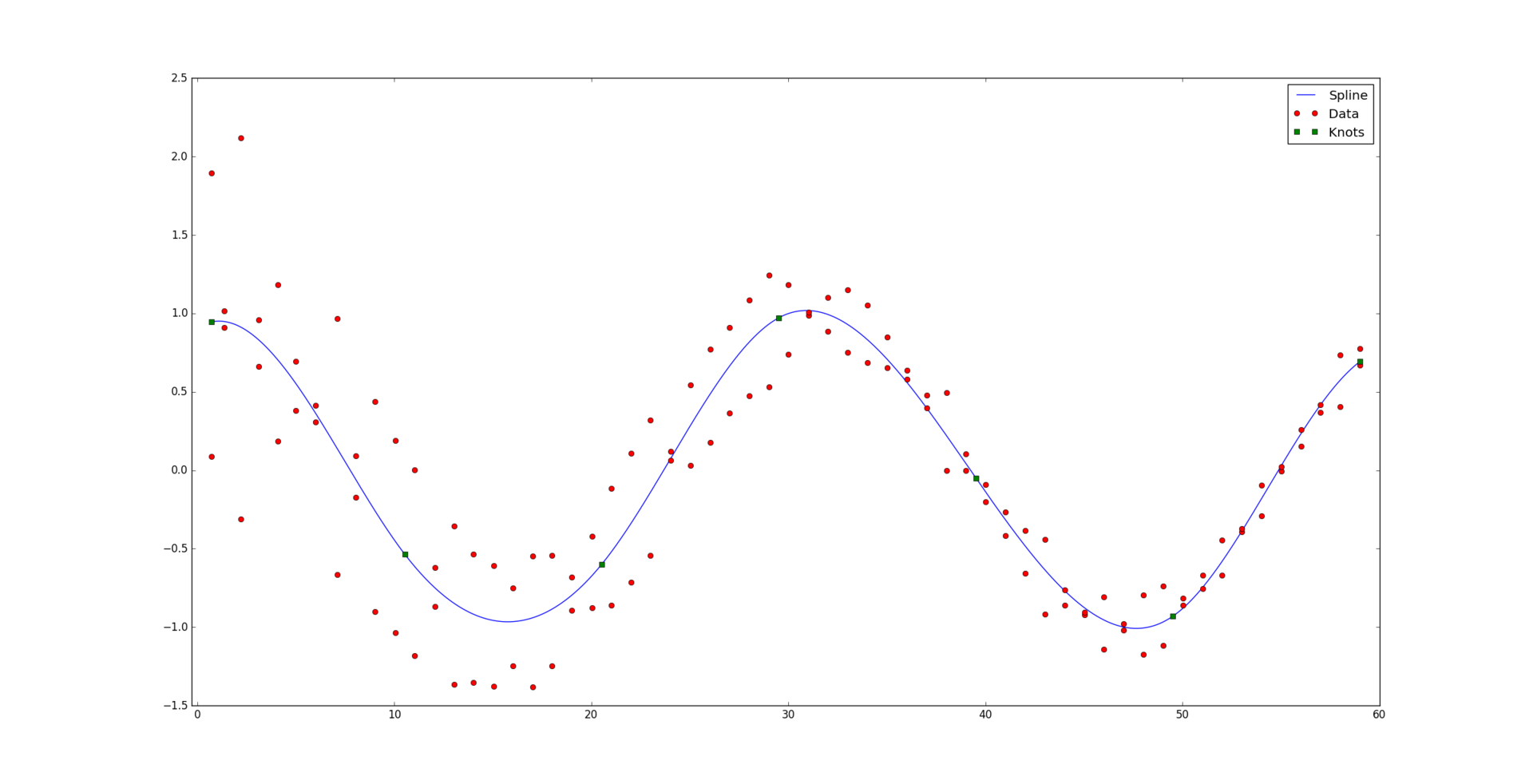
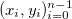 и соответствующий им набор положительных весов
и соответствующий им набор положительных весов 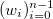 . Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные.
. Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные. 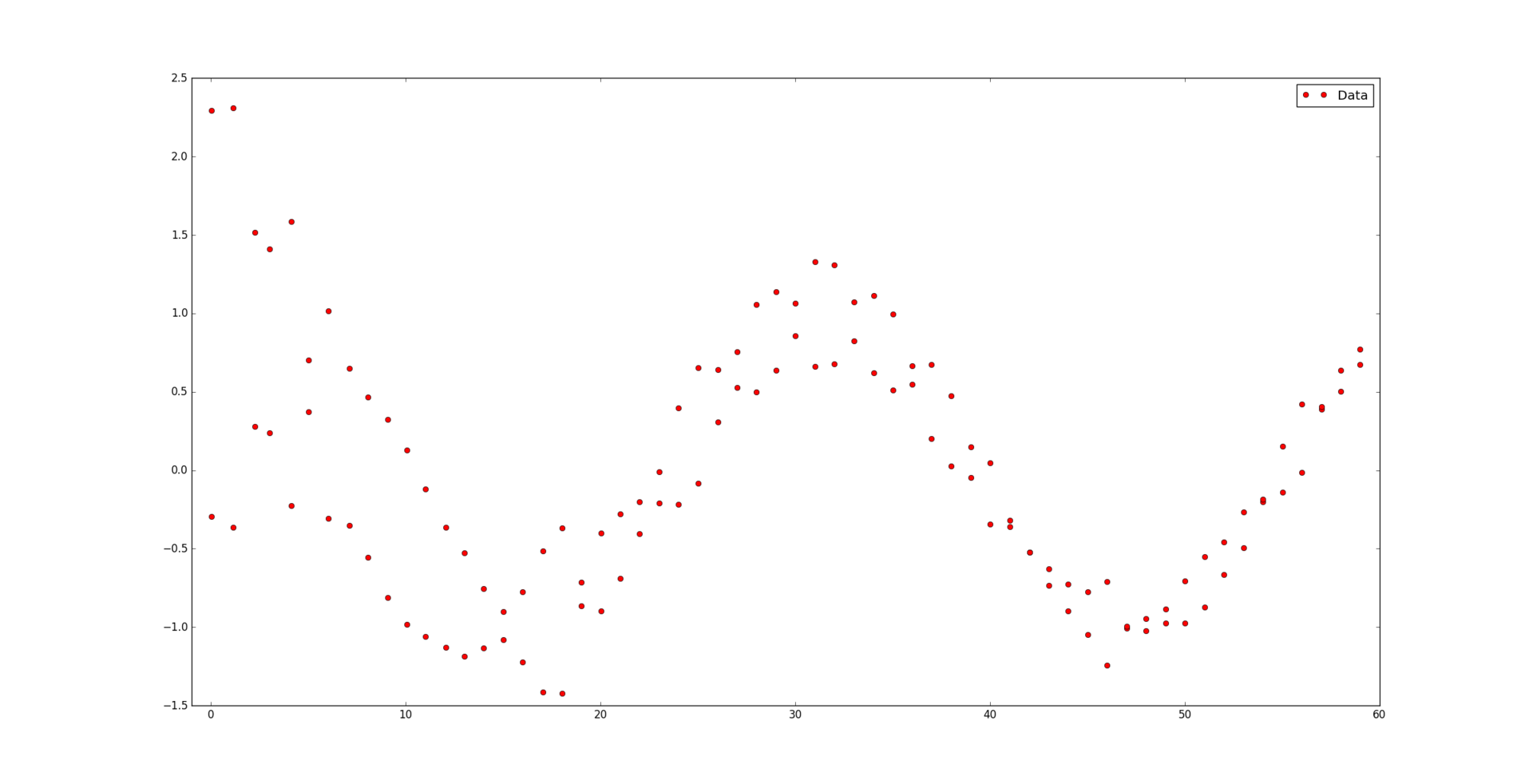


 Привет всем любителям и исследователям искусственного интеллекта! В данной статье я хотел бы рассказать об интересном проекте: модульной системе универсального искусственного интеллекта (МСУИИ) «Amiga Virtual» (AV, «Виртуальная Подружка»). Я расскажу об основных принципах её работы и опишу некоторые детали реализации, а самые любопытные смогут исследовать все исходные коды. Разработка ведётся на Delphi, но модули теоретически могут быть написаны на любом ЯП. Данная система будет интересна как конечным пользователям чат-ботов и связанных с ними систем, так и разработчикам ИИ — ведь на её основе можно разработать практически любой тип ИИ.
Привет всем любителям и исследователям искусственного интеллекта! В данной статье я хотел бы рассказать об интересном проекте: модульной системе универсального искусственного интеллекта (МСУИИ) «Amiga Virtual» (AV, «Виртуальная Подружка»). Я расскажу об основных принципах её работы и опишу некоторые детали реализации, а самые любопытные смогут исследовать все исходные коды. Разработка ведётся на Delphi, но модули теоретически могут быть написаны на любом ЯП. Данная система будет интересна как конечным пользователям чат-ботов и связанных с ними систем, так и разработчикам ИИ — ведь на её основе можно разработать практически любой тип ИИ.
