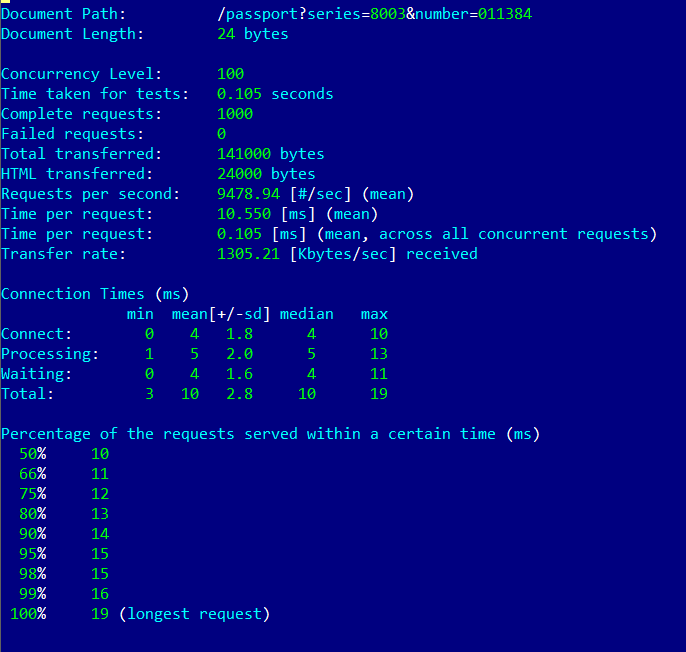
Всем привет! Я Иван, старший инженер-тестировщик в КРОК. Уже 6 лет занимаюсь тестированием ПО. Из них 3 года внедряю автоматизацию тестирования на различных проектах - люблю всё автоматизировать. На рабочей машине много разных “батников” и bash-скриптов, которые призваны упрощать жизнь.
Недавно у нас стартовал проект по модернизации и импортозамещению системы электронного документооборота (СЭД) в одной крупной организации. Система состоит из основного приложения и двух десятков микросервисов, в основном - для построения отчётов и интеграции с другими подсистемами. Сейчас в проекте уже настроено больше 100 автотестов, и они сильно помогают при частых релизах, когда времени на регресс почти нет. Весь набор автотестов выполняется примерно за 25 минут, в среднем экономим до 3,5 часов ручной работы при каждом запуске. А запускаем мы их каждый день.
Дальше будет про то, как мы выбирали технологии и инструменты, какой каркас и подход к организации автотестов в итоге получился. И почему мы в КРОК решили тиражировать этот подход в других проектах, реализация которых основана на Content Management Framework (CMF) под СЭД. На базе CMF у нас есть комплексное решение для автоматизации процессов документооборота КСЭД 3.0. Конечно, отдельные решения по автотестам можно применять под любую СЭД.
Ещё расскажу про проблемы, и как мы их решали. Пост будет интересен и полезен, если в ваших автотестах необходимо подписывать документ электронной подписью (ЭП) в докер-образе браузера, проверять содержимое pdf файла, выполнять сравнение скриншотов или интегрироваться с одной из популярных Test Management System.