
Предлагаю подумать: как технологии могут помочь бороться с пропагандой в СМИ?
27 мин

Фотограф: Аркадий Шайхет.
Вступление
Эту статью можно разделить на две логические части. В первой я рассматриваю феномен медиапропаганды: что это такое, почему она опасна и к каким жутким вещам уже приводила в истории. Я подробно рассмотрю механизмы работы современной государственной пропаганды в СМИ и попытаюсь понять, почему она так эффективна и какими характерными признаками обладает.
Вторая часть – это размышления о том, как на основе рассмотренных в первой части характерных признаков можно попытаться автоматизировать распознавание пропаганды в СМИ. Поскольку пропаганда – это воздействие текстом (помимо картинки, конечно), а я не обладаю необходимыми познаниями в области обработки естественного языка (Natural Language Processing), то мои выкладки – это именно что размышления вслух. Я буду более-менее структурированно описывать возможные функции программы, которая должна искать в материалах СМИ признаки пропаганды, но без технической конкретики.
Поэтому сразу скажу: не рассчитывайте прочитать в тексте про конкретные алгоритмы и их способы применения. Напротив – буду честен: я рассчитываю найти среди вас тех, кто разбирается как в области NLP, так и в разработке плагинов для браузеров и получить от вас обратную связь в комментариях. Если достаточное количество людей заразится моими идеями, то, возможно, нам с вами удастся вместе поработать над интересным опенсорсным решением!


 Я состою в жюри
Я состою в жюри 








 Многие знают, что ABBYY занимается обработкой и извлечением данных из разных документов. Но у наших продуктов есть и другие интересные возможности. В частности, с помощью решения ABBYY Intelligent Search можно быстро и удобно искать информацию по смыслу в электронных документах из корпоративных систем. Этим уже пользуются крупные российские компании, например, производитель ракетных двигателей
Многие знают, что ABBYY занимается обработкой и извлечением данных из разных документов. Но у наших продуктов есть и другие интересные возможности. В частности, с помощью решения ABBYY Intelligent Search можно быстро и удобно искать информацию по смыслу в электронных документах из корпоративных систем. Этим уже пользуются крупные российские компании, например, производитель ракетных двигателей 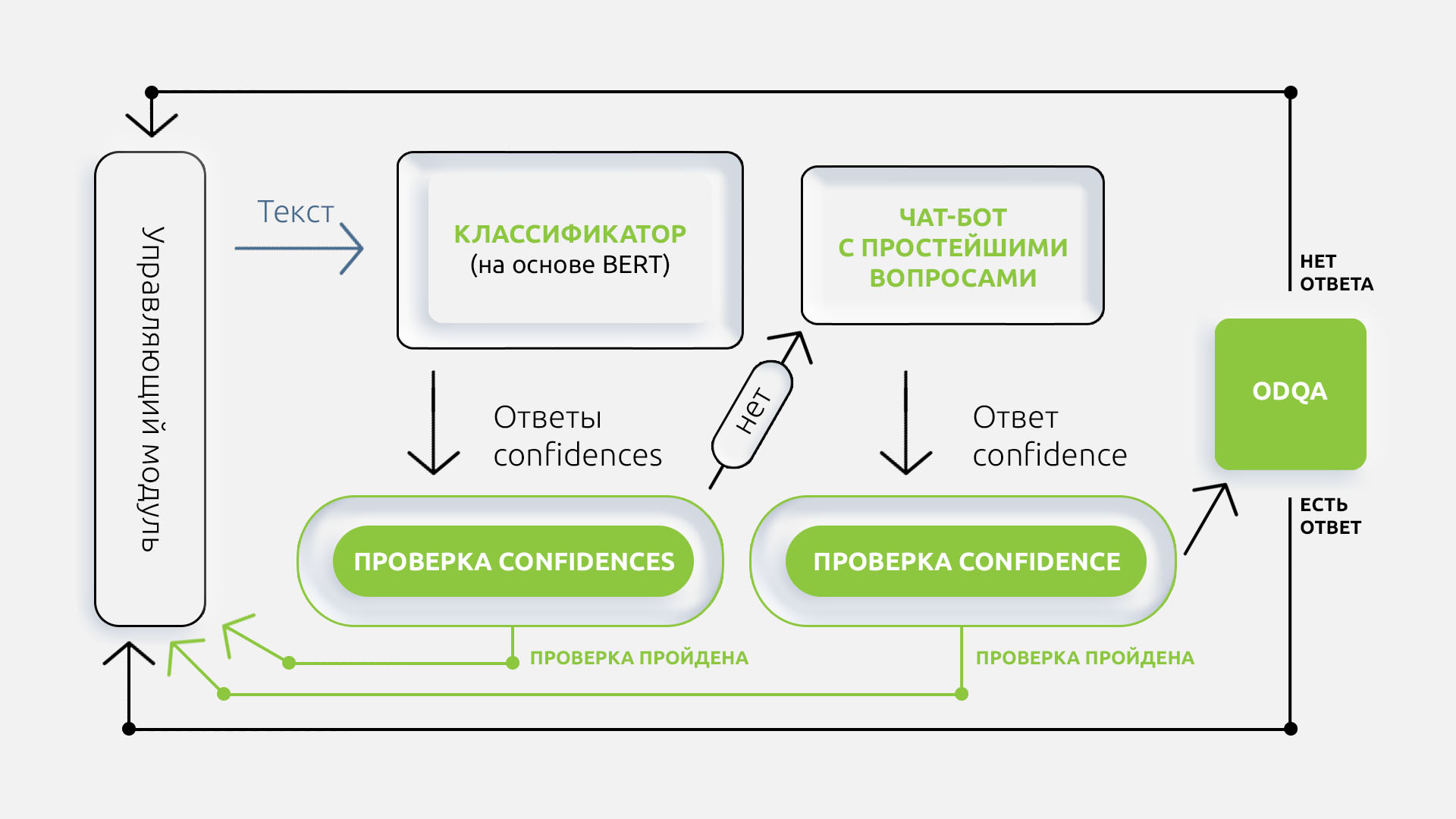
{kind=link}