
Масштабирование БД в высоконагруженных системах
9 мин
На прошлом внутреннем митапе Pyrus мы говорили о современных распределенных хранилищах, а Максим Нальский, CEO и основатель Pyrus, поделился первым впечатлением от FoundationDB. В этой статье рассказываем о технических нюансах, с которыми сталкиваешься при выборе технологии для масштабирования хранения структурированных данных.
Когда сервис недоступен пользователям какое-то время, это дико неприятно, но всё же не смертельно. А вот потерять данные клиента — абсолютно недопустимо. Поэтому любую технологию для хранения данных мы скрупулезно оцениваем по двум-трем десяткам параметров.
Когда сервис недоступен пользователям какое-то время, это дико неприятно, но всё же не смертельно. А вот потерять данные клиента — абсолютно недопустимо. Поэтому любую технологию для хранения данных мы скрупулезно оцениваем по двум-трем десяткам параметров.



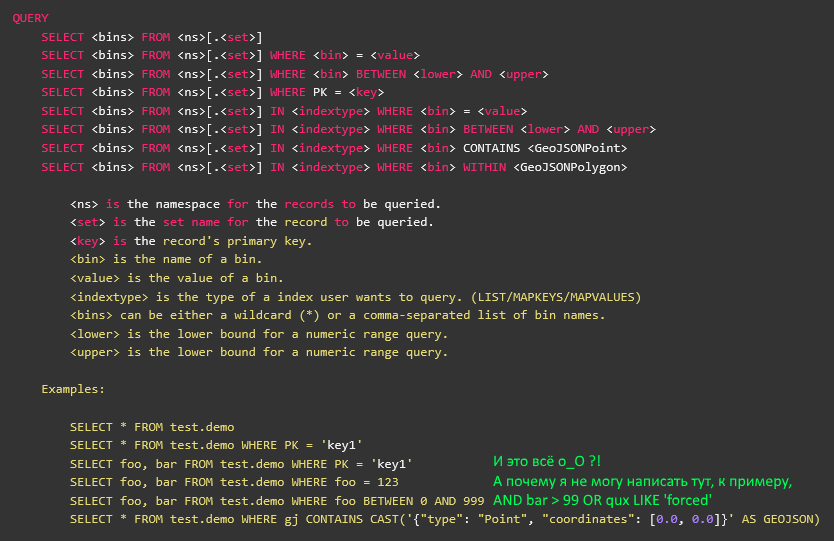



 Это будет немного напыщенная речь, но меня действительно раздражает софт, в котором люди пытаются изобрести очередной собственный язык запросов. У нас уже есть триллион различных ORM, еще триллион баз данных с собственным языком запросов каждая, и еще триллион SaaS-продуктов, для доступа к которым нужно освоить какой-нибудь очередной DSL, которые они придумали.
Это будет немного напыщенная речь, но меня действительно раздражает софт, в котором люди пытаются изобрести очередной собственный язык запросов. У нас уже есть триллион различных ORM, еще триллион баз данных с собственным языком запросов каждая, и еще триллион SaaS-продуктов, для доступа к которым нужно освоить какой-нибудь очередной DSL, которые они придумали.



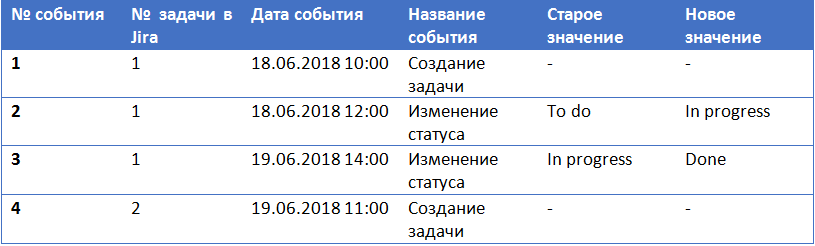

{kind=link}