
KnownReader. Читалка и словари
8 мин

Всем привет!
Уже который год идёт, а мы все ещё пишем читалку со словарями под Android. Настало время для очередной статьи о том, что у нас появилось нового.
Всем привет!
Уже который год идёт, а мы все ещё пишем читалку со словарями под Android. Настало время для очередной статьи о том, что у нас появилось нового.


В наиболее популярном случае иметь множество инсталляций GitLab — это антипаттерн. Однако обстоятельства бывают разными: специализация нашего бизнеса привела к тому, что мы администрируем десятки self-hosted GitLab-инстансов обслуживаемых клиентов. Периодически у нас возникает потребность проделать какие-то действия на всех GitLab’ах сразу, чтобы не тратить время на многократное повторение рутинных операций. Все началось с необходимости мониторинга за критическими обновлениями для GitLab. Но аппетиты росли: со временем нам уже хотелось искать по содержимому файлов во всех инсталляциях или даже создавать пользователей.
Расскажем о том, как мы решили эти задачи в рамках внутренней разработки, которую теперь публикуем как Open Source-проект под названием glaball.


В продолжение наших статей про Chaos Engineering расскажу про недавний опыт проверки на прочность приложений в кластере Kubernetes с помощью Open Source-оператора Chaos Mesh.
Использование того или иного продукта в проекте - это всегда попытка найти лучшее решение, балансируя между ограниченным бюджетом, возможностями роста практически по любому сценарию и высотой "порога входа". Существует много продуктов, которые связаны с контейнерами, что выбрать подходящий инструмент становится всё сложнее и сложенее, а community с "промытыми мозгами" и мышлением "ёжиков жрущих кактус" только добавляет сложности (хотя в противовес оным есть хейтеры, которые наоборот обгадят решение, просто потому что в своё время оно им не подошло).
В целом, чтобы выбрать нужное решение чаще всего приходится поднять лабу, которая покроет 90% задач, чтобы понять насколько решение подходящее, а это значит пройти какую-то боль, потратить время и деньги. Но ещё помогают статьи, в которых рассматриваются частные случаи внедрения и подбор инструментов, чтобы научиться на чужих ошибках через объективный взгляд со стороны. Надеюсь, эта статья о том, почему и как мы пришли к решению с werf, поможет кому-то подобрать инструмент для своих нужд.

Привет! Меня зовут Сергей, я старший разработчик в Ozon и раньше вообще не был замечен в QA.
Все мы привыкли к лёгкому написанию тестов на Python и Java — это основные языки автотестировщиков с богатым инструментарием утилит и всего, что упрощает жизнь. Что нужно для написания автотестов для HTTP-сервиса на Python или Java? Гугл, бутылочка крафта и два часа времени.
А как быть в случае с Go? Как раз на нём мы в большинстве случаев пишем микросервисы. И если тесты написаны на другом языке, разработчики не могут внести в них свой вклад или отревьюить их. Поэтому внутри Ozon активно развивается Go-сообщество QA, и этим ребятам тоже нужно тестировать HTTP-сервисы и проверять отчёты в Allure. Как настоящие сварщики мы подумали: «Если чего-то не хватает, нужно написать своё». Сказано — сделано: встречайте опенсорс-библиотеку CUTE в BDD-стиле, которая облегчает тяготы создания автотестов и упрощает переход на Go. Главные фичи: создание HTTP-тестов, возможность реализовывать проверки из коробки, Allure-отчёты и низкий порог входа. Инструкция — под катом.
В июне прошлого года вышла первая версия программы Organic Maps - бесплатных мобильных карт для Android и iOS с открытым исходным кодом. Об этом событии я опубликовал небольшую заметку на Хабре. Весь год шла интенсивная разработка, а число установок превысило 100 тысяч. Я решил взять небольшое интервью у разработчиков Organic Maps и обсудить с ними итоги года работы и планы на будущее.
Перед вами первая заметка на тему разработки игр на Go с использованием библиотеки ebiten (также известный как Ebitengine).
Сегодня мы будем разбираться, как выполняется позиционирование текста. Как центрировать его, менять межстрочный интервал и так далее. Официальная документация и примеры содержат почти всё необходимое, но чтобы свести всё воедино и понять все концепции можно потратить несколько вечеров. Я постараюсь сэкономить ваше время.

Шесть лет назад, в июне 2016-го года, вышла первая статья об инструменте, с разработкой которого я связан уже много лет. Шестилетней давности публикация дала толчок интереса к SObjectizer-у и, как я понимаю, кто-то сумел попробовать SObjectizer в деле (или собрался попробовать) именно благодаря той статье. Поскольку за прошедшее время SObjectizer несколько изменился, то я подумал, что не помешало бы выпустить обновленную версию статьи. Исправленную и дополненную. С учетом не только того, что в SObjectizer изменилось/появилось/исчезло, но и отталкиваясь от критических отзывов на предыдущие статьи про SObjectizer.
Итак, вашему вниманию предоставляется свежий взгляд на то, что же это за инструмент, для чего он создавался и почему получился именно таким.



Upd. 11.06.2022 Многие заинтересовались генерацией изображений нейросетями. Вот Colab (интерактивная среда для запуска кода) для рисования картинок в стиле pixel art по текстовому описанию. Просто запускайте, ближе к концу увидете ячейку для ввода текста. Примеры картинок из Colab'а в комментариях.
Два года назад я начал делать небольшой проект, связанный с обработкой текстов на иностранных языках. Он постепенно развивался и стал использоваться лингвистами в НКРЯ, а энтузиасты сохранения малых языков используют его для расширения своих параллельных корпусов.
Сегодня же я расскажу как при помощи него создать полноценную параллельную книгу на разных языках. Книга будет красиво сверстана в PDF, иметь содержание, обложку и две выровненные по смыслу колонки текста. Такие книги служат отличным подспорьем при изучении иностранного языка. Найти их, однако, не так просто, и скорее всего это будут книги для детей или избранная классика. Полный пример готовой книги можно посмотреть здесь. Под капотом у приложения NLP модели, поддерживаемых языков более ста.
Проект открытый и любой может в нем поучаствовать. Во многом благодаря сообществу и вашему участию он за несколько лет дошел до сегодняшнего дня. В общем штука годная, давайте уже посмотрим, что к чему.

Некоторые IDE и текстовые редакторы парсят исходный файл целиком при каждом изменении, что может тормозить на больших файлах, а некоторые делают это построчно с помощью регулярных выражений, что тоже тормозит и не даёт качественной подсветки кода, т.к. теряется контекст. Для решения этих проблем в недрах GitHub был создан tree-sitter - инкрементальный парсер, который используют всё больше и больше проектов. Давайте разбираться зачем и почему.


Команда Rust рада сообщить о новой версии языка — 1.61.0. Rust — это язык программирования, позволяющий каждому создавать надёжное и эффективное программное обеспечение.
Если у вас есть предыдущая версия Rust, установленная через rustup, то для обновления до версии 1.61.0 вам достаточно выполнить команду:
rustup update stableЕсли у вас ещё нет rustup, то можете установить его со страницы на нашем веб-сайте, а также ознакомиться с подробным описанием выпуска 1.60.0 на GitHub.
Если вы хотите помочь нам протестировать будущие выпуски, вы можете использовать beta (rustup default beta) или nightly (rustup default nightly) канал. Пожалуйста, сообщайте обо всех встреченных вами ошибках.

В этой статье мы рассмотрим новый экспериментальный режим совместной работы Open Source-утилиты werf и инструмента для непрерывной доставки Argo CD, объединяющий в себе возможности и удобства обоих проектов в рамках одного CI/CD-процесса. Сейчас идет активная разработка этих возможностей werf, но в первом приближении функционал уже доступен и готов к использованию.
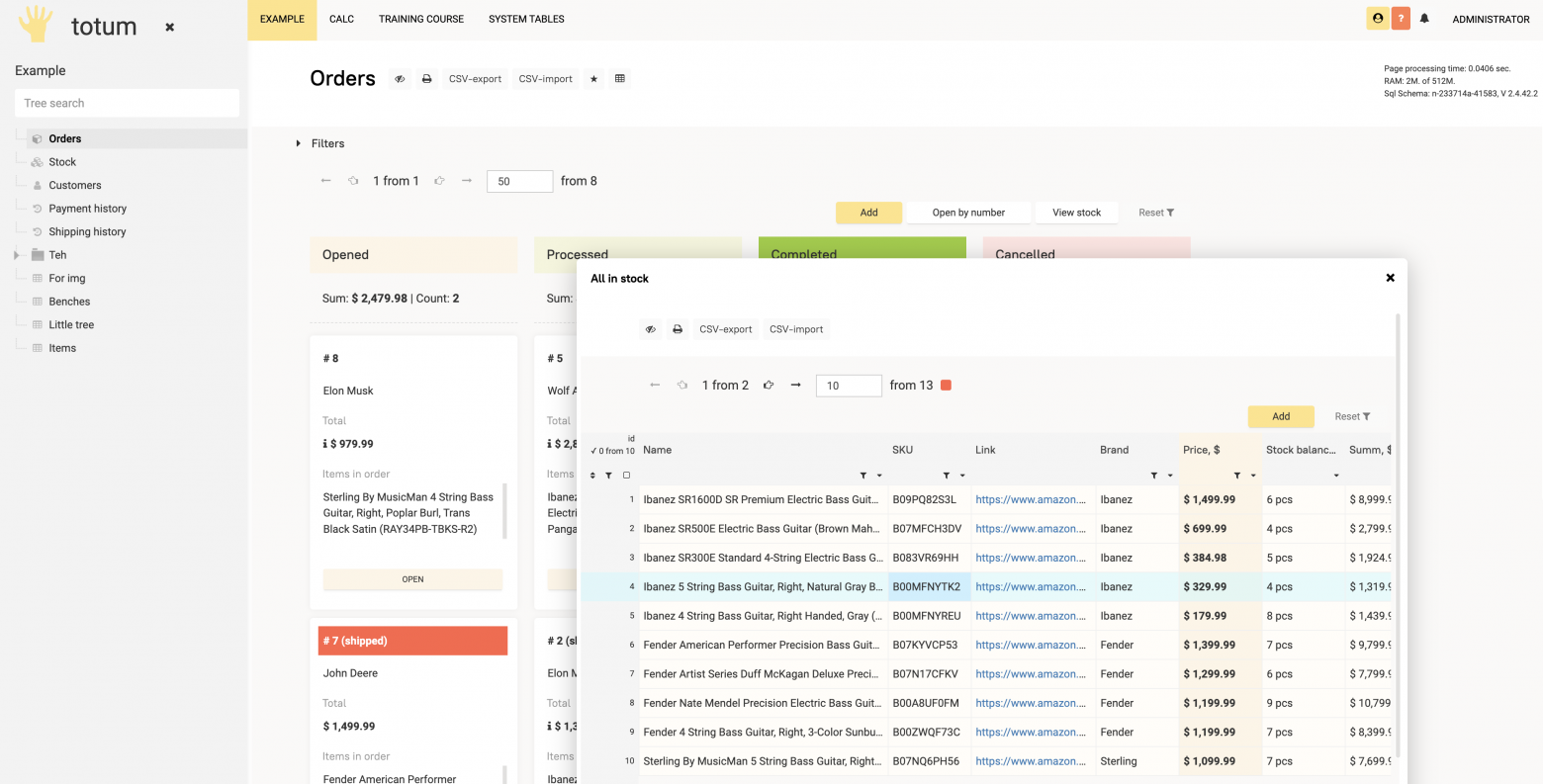
Инструмент для цифровизации бизнеса в момент, когда он вырос из XLS-таблиц
Универсальный UI, логика на основе простых кодов, автоматические действия, права доступа, логирование, API и куча всего остального ?
На вашем сервере, легко изучаемая и масштабируемая вместе с ростом бизнеса ?
Вместо целой команды проект могут вести 1-2 специалиста ✌️
Минимальные требования к стартовой квалификации специалиста — вы можете научить разрабатывать на Totum вашего сисадмина, тестировщика, продакта, проджекта, инженера, юриста или финансиста. Или научиться сами.
Лицензия: MIT (бесплатно)