


Классификация покрова земли при помощи eo-learn. Часть 1
Привет, Хабр! Представляю вашему вниманию перевод статьи "Land Cover Classification with eo-learn: Part 1" автора Matic Lubej.
Предисловие
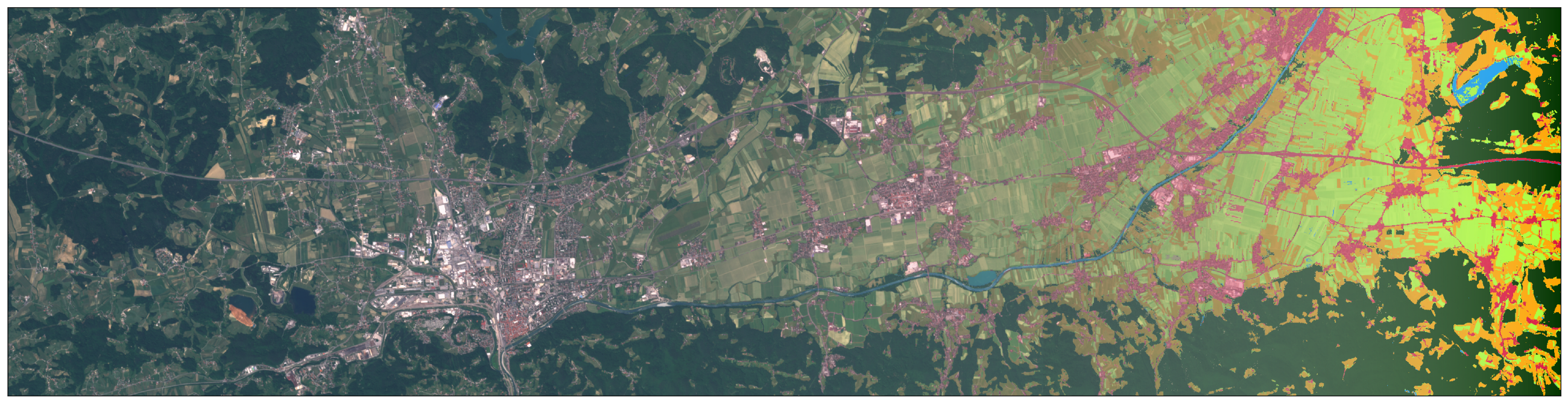
Примерно полгода назад был сделан первый коммит в репозиторий eo-learn на GitHub. Сегодня, eo-learn превратился в замечательную библиотеку с открытым исходным кодом, готовую для использования кем угодно, кто заинтересован в данных EO (Earth Observation — пр. пер.). Все в команде Sinergise ожидали момента перехода от этапа построения необходимых инструментов, к этапу их использования для машинного обучения. Пришло время представить вам серию статей, касающихся классификации покрова земли используя eo-learn
Огромный открытый датасет русской речи

Специалистам по распознаванию речи давно не хватало большого открытого корпуса устной русской речи, поэтому только крупные компании могли позволить себе заниматься этой задачей, но они не спешили делиться своими наработками.
Мы торопимся исправить это годами длящееся недоразумение.
Итак, мы предлагаем вашему вниманию набор данных из 4000 часов аннотированной устной речи, собранный из различных интернет-источников.
Подробности под катом.
Как я узнал, что моя виза не готова, сообщением в Slack
Пост актуальный для майских праздников. 6 недель назад я подал документы, чтобы получить визу в Ирландию. Вылет запланирован на 30 апреля. Существует сайт посольства, на котором публикуются списки решений по визам. Они это делают по понедельникам и четвергам. И вот я сижу в воскресенье, 28 апреля, по моей визе решения еще нет. И дальнейшие мои действия в понедельник зависят от того, будет ли мое заявление в новом отчете или нет. Если нет, то надо будет ехать в посольство и разбираться. Если есть, то дергать визовый центр. Сидеть и обновлять страничку целый день в понедельник казалось унылым времяпрепровождением, поэтому я написал скрипт на Python.

Disclaimer. Я не программист, но умею программировать. Это значит, что я не могу написать изящный и эффективный код, но я могу заставить эту шарманку делать то, что мне от нее нужно.
60 миллионов полей и 27 культур. Как мы делали карту всех полей Европы и США
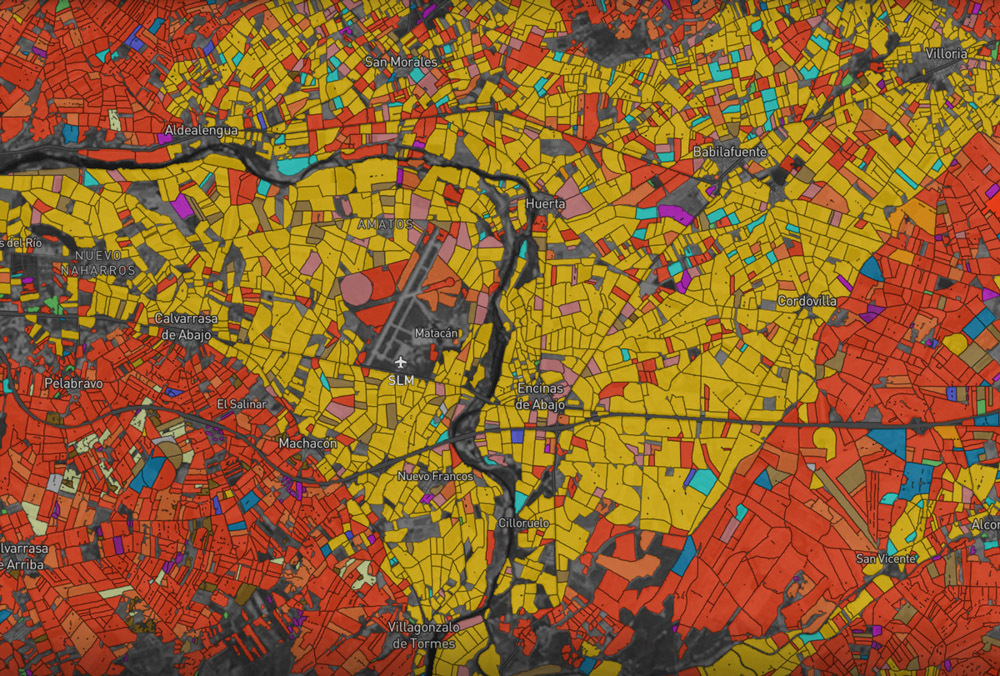
Несколько месяцев назад мы запустили первую в мире бесплатную интерактивную карту, с помощью которой можно посмотреть информацию о любом поле в США и Европе. Про карту написали десятки изданий, а на Product Hunt она собрала беспрецедентные для продукта из агросектора полторы тысячи лайков (и в итоге стала AI & Machine Learning Product of the Year 2018). Мы разрабатывали карту два месяца — вот как это было.
Собрали всем «Хабром» справочник «Кем выдан…» для паспортов. Качайте на здоровье

С пару месяцев назад мы поэкспериментировали: получится ли на «Хабре» собрать годный справочник подразделений, выдавших российские паспорта. Дело полезное: эти данные нужны много кому, канонического источника нет, а существующие — очень так себе.
И знаете, все получилось. Пригодный к использованию справочник готов, можно качать и пользоваться. А еще мы сделали подсказки, которые ускоряют ввод подразделений в электронные формы.
Джулиан Ассанж арестован полицией Великобритании

Фото телеканал НТВ
Власти Эквадора лишили основателя WikiLeaks Джулиана Ассанжа убежища в посольстве в Лондоне. Ассанж укрывался в эквадорском посольстве с 2012 года.
Эквадор принял суверенное решение отказать в дипломатическом убежище Джулиану Ассанжу за неоднократные нарушения международных конвенций— прокомментировал событие президент Эквадора Ленин Морено.
Концепция краткой энциклопедии
Информация разбита по разным источникам, дублируется и избыточна
Человечество страдает от переизбытка информации. Однако проблема заключается не только в количестве информации, но и в ее качестве. Интернет переполнен разнообразными источниками, каждый из которых дублирует часть информации из других источников. Читая новую статью приходится отсеивать то что уже известно. Сама информация зачастую представлена в крайне разбавленном виде, полна пространных размышлений автора и прочей избыточности. Почему-то считается, что чем длиннее статья или толще книга, тем они солиднее. Концентрация информации при этом не всегда учитывается.
Генератор больших графов транзакций с паттернами преступной деятельности
Доброго времени суток.

Пару лет назад перед нашей командой (compliance в швейцарском банке) встала очень интересная задача — нужно было сгенерировать большой граф транзакций между клиентами, компаниями и банкоматами, добавить в этот граф паттерны, похожие на паттерны отмывания денег и другой преступной деятельности, а также добавить минимальную информацию об узлах этого графа — имена, адреса, время, и т.д. Разумеется, все данные должны былии быть сгенерированны с нуля, без использования существующих данных клиентов.
Для решения данной задачи был написан генератор, которым мне бы хотелось с вами поделиться. Под катом вы найдете историю, объясняющую зачем нам это было нужно, и описание работы генератора. Для нетерпеливых — вот тут лежит код. Буду рад, если кому-нибудь будет полезен наш опыт.
Получаем ссылки на профили Vk из выдачи SearchFace с помощью Python (но это не точно)

Кадр из сериала Person Of Interest
Сегодня мы поговорим о лёгком распознавании лиц с помощью доступных инструментов.
Используются: Python 3.6, searchface.ru, внешний сервис для преобразования ссылок на фото в id (бот в телеграме, на текущий момент)
Итак, у нас есть сайт, который ищет по лицам.
Заглянем внутрь.
Говорит и показывает: отличается ли риторика популярных украинских политиков?
Disclaimer. Эта статья написана из интереса к теме и желания опробовать изученный материал на практике, без претензий на максимально точный и детальный анализ.
Сколько лет вашему сеньору?

Не знаю как вам, а мне кажется диким когда люди с парой лет опыта величают себя «сеньор девелопер». Конечно, отдельные гении могут писать идеальные программы ещё в школе, но на то они и гении — единицы из миллионов.
Однако в последнее время этих самых гениев что-то стало многовато. Не просто много, а достаточно чтобы оказывать влияние на рынок. Легко можно найти вакансии сеньоров/архитекторов/тимлидов с опытом от года.
Так что же происходит? В самом деле у нас урожай гениев или просто модная тема новостей? Поменялось ли что-то за последние годы? Я решил узнать. Под катом методология исследования, немного графиков и внезапные результаты.
Ближайшие события
Эксперимент: собираем справочник подразделений, выдавших паспорт
Самое утомительное поле при вводе паспорта — «Кем выдан». Вбивать в форму какое-нибудь «Отделом внутренних дел Медведевского района республики Марий Эл» муторно. Люди злятся, сокращают название как придется, ошибаются.
Было бы здо́рово подсказывать варианты по коду подразделения.
Карта ДТП
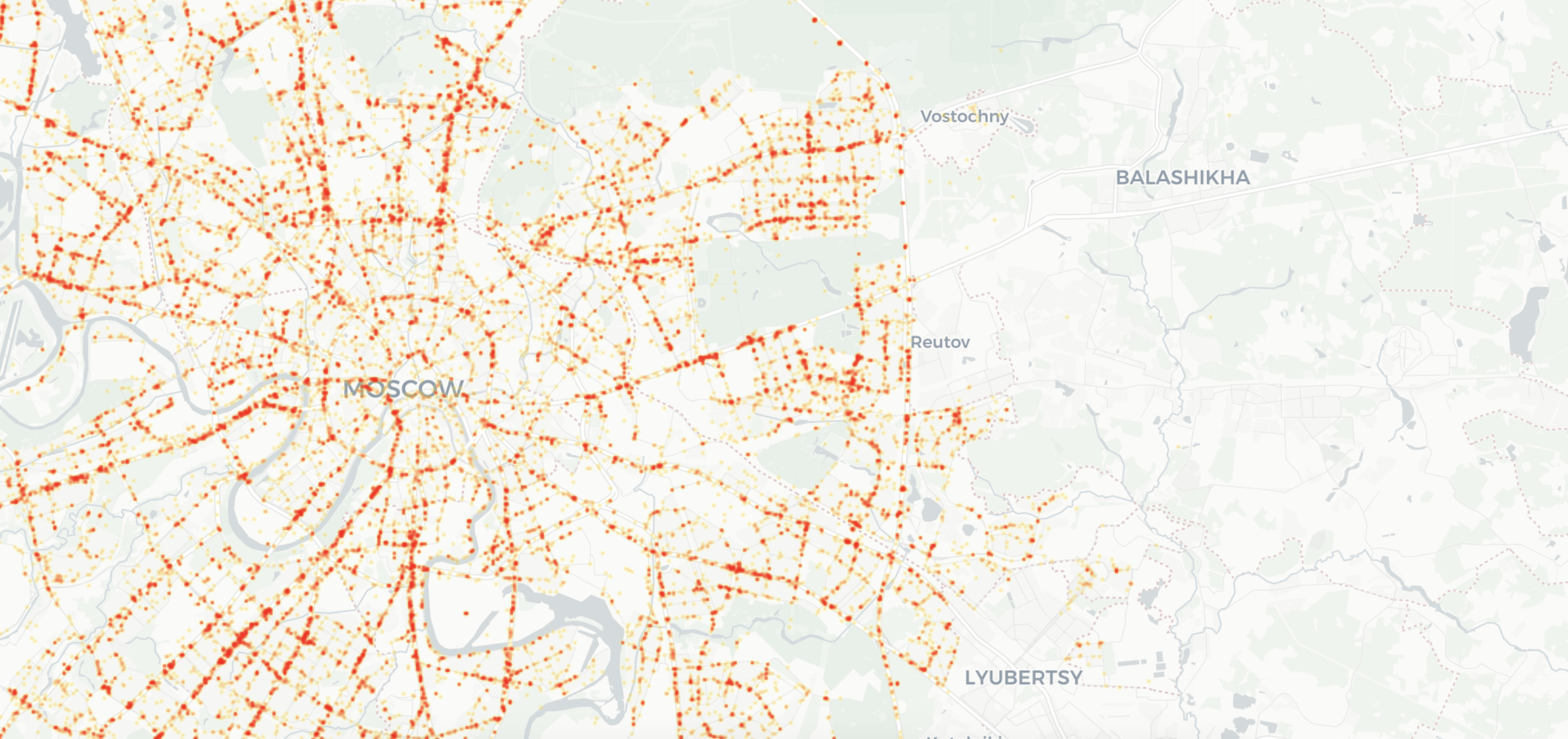
Расскажу вам о проекте “Карта ДТП” – интерактивной карте аварий в России. Карта упрощает анализ ДТП и помогает найти реальные причины происшествий. Как пришла идея, где брали данные и зачем открыли исходный код.
За 2018 год в ДТП на дорогах России погибли 19088 человек
Мой адрес не дом и не улица, мой адрес – Советский Союз?

Питер Брейгель Младший, Уплата налога, 1640 год
Прошлый заход на бреющем по объектам зашел. Продолжим разведку боем. Сегодня поговорим о тяжелом. Пусть ещё не о BIG DATA, но работать уже неудобно – достаточно большие объёмы данных. Не каждому влезет в оперативную память целиком, а некоторым не влезет даже на диск (не места мало, а хламу много). Имя нашему подопечному БД ФИАС — база данных федеральной адресной информационной системы. Архив в 5,5 ГБ. И это сжатый в архив XML. После распаковки будут полные 53 ГБ (для распаковки запасайте 110 ГБ). И как начнёшь его парсить да конвертить, то и 110 ГБ будет мало. О потребном размере ОЗУ тоже будет.
Законодательный эксперимент с внедрением цифровых инноваций
В связи с этим рассматривается механизм «регуляторной гильотины», который заключается в масштабном анализе и пересмотре действующих нормативно-правовых актов (НПА). По сути предполагается, что положения актов, содержащих обязательные требования, автоматически потеряют свою силу, если они не будут специальным образом пересмотрены, подтверждены или изменены. При этом предполагается, что необходимость сохранения существующих ограничений и требований обязательно должна быть доказана соответствующими органами. По словам Медведева, к 1 февраля 2020 года можно пересмотреть все требования к предпринимателям с учетом современных реалий.
В контексте данной идеи Минэкономразвития России разработало законопроект о регуляторных песочницах для инновационной деятельности в сфере цифровых технологий. В документе определяются цели и принципы создания таких песочниц, вводятся ограничения на их применение, и устанавливаются гарантии прав и законных интересов всех участников экспериментальных правовых режимов (ЭПР) и тех, кто с ними будет взаимодействовать. Предполагается, что такой механизм приведет к реальному сокращению времени и других издержек на внедрение инновационных продуктов цифровой экономики.
Полный текст законопроекта.

Данные бывают смешными (и вот примеры)

Мы в HFLabs перелопачиваем колоссальное количество данных: адреса, ФИО, реквизиты компаний, документы. Весь год писали о сложных и полезных штуках, но пора и честь знать. Перед праздниками — подборка смешных данных, что нам принес 2018-й.
Новогодний датасет 2018: открытая семантика русского языка

Совершеннолетняя журналистика: от России до Кремля
Анализ публикаций Lenta.ru за 18 лет (с сентября 1999 по декабрь 2017 гг.) средствами python, sklearn, scipy, XGBoost, pymorphy2, nltk, gensim, MongoDB, Keras и TensorFlow.

В исследовании использованы данные из поста «Анализируй это — Lenta.ru» пользователя ildarchegg. Автор любезно предоставил 3 гигабайта статей в удобном формате, и я решил, что это прекрасная возможность протестировать некоторые методы текстовой обработки. Заодно, если повезёт, узнать что-то новое о российской журналистике, обществе и вообще.