
На дворе почти 2018, а мы любим колбэки
9 мин
Если в первый момент идея не кажется абсурдной, она безнадёжна.
— Альберт Эйнштейн
Мы собрали для вас самые популярные темы из обсуждений Node.js на Хабре, и попросили рассказать о них признанных экспертов: некоммерческого Node-хакера Матиаса Мэдсена и автора множества книг и курсов по Node, Азата Мардана.
Вот точный список тем:
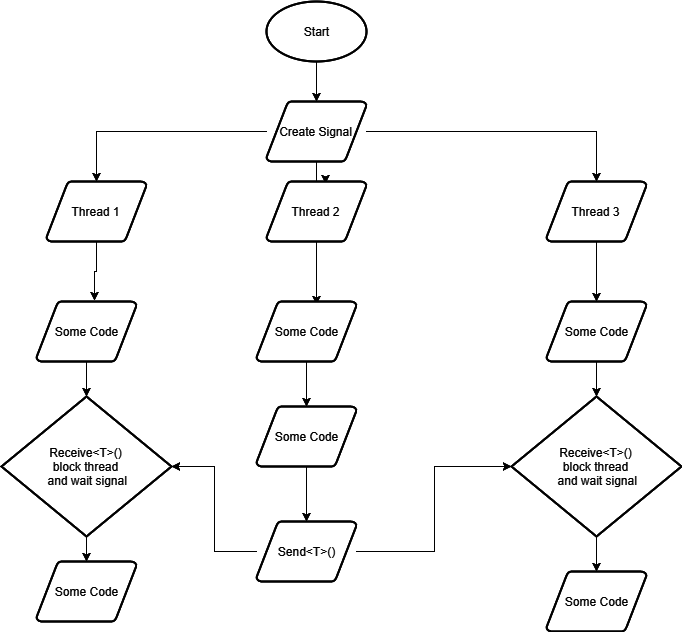
- Потоки в Node.js и способы распараллеливания вычислений;
- Асинхронность в Node.js;
- Отладка и логирование в Node.js;
- Проблемы мониторинга производительности на продакшене;
Инструменты для мониторинга нод.
 Азат Мардан (Azat Mardan) — Tech Fellow, менеджер в компании Capital One, и эксперт по JavaScript/Node.js с несколькими онлайн-курсами на Udemy и в Node University, а также автор 14 книг по той же тематике, включая «React Quickly» (Manning, 2017), «Full Stack JavaScript» (Apress, 2015), «Practical Node.js» (Apress, 2014) и «Pro Express.js» (Apress, 2014).
Азат Мардан (Azat Mardan) — Tech Fellow, менеджер в компании Capital One, и эксперт по JavaScript/Node.js с несколькими онлайн-курсами на Udemy и в Node University, а также автор 14 книг по той же тематике, включая «React Quickly» (Manning, 2017), «Full Stack JavaScript» (Apress, 2015), «Practical Node.js» (Apress, 2014) и «Pro Express.js» (Apress, 2014).














{kind=link}