
Lock-free структуры данных. Concurrent map: разминка
9 мин
Мне оказали честь — пригласили выступить на первой конференции C++ 2015 Russia 27-28 февраля. Я был насколько наглым, что запросил 2 часа на выступление вместо положенного одного и заявил тему, наиболее меня интересующую — конкурентные ассоциативные контейнеры. Это hash set/map и деревья. Организатор sermp пошел навстречу, за что ему большое спасибо.
Как подготовиться ко столь ответственному
Конечно, надо записать свои мысли, глядя на слайды. А если что-то написано, то не худо бы и опубликовать. А если публиковать, — то на хабре.
Итак, по следам C++ 2015 Russia! Авторское изложение, надеюсь, без авторского косноязычия, без купюр и с отступлениями по теме, написанное до наступления события, в нескольких частях.





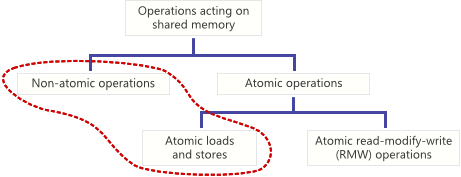

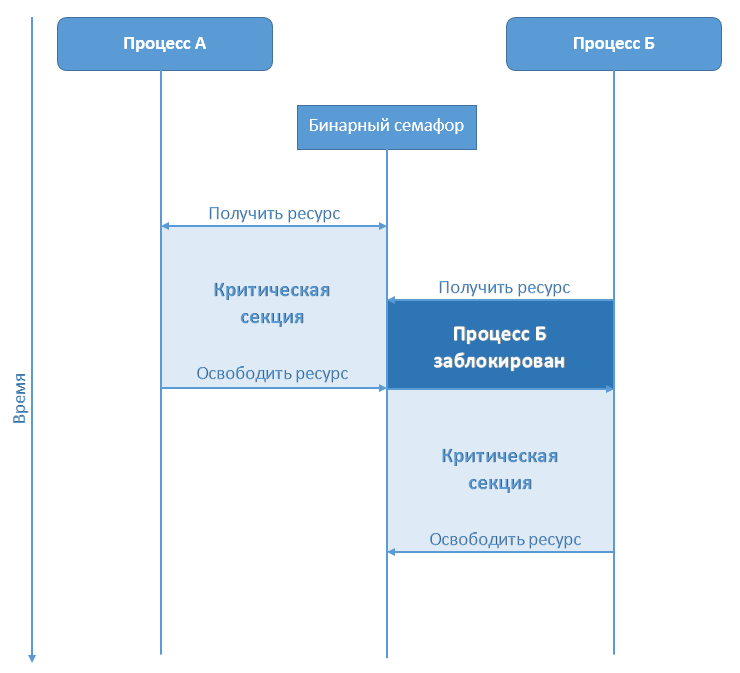
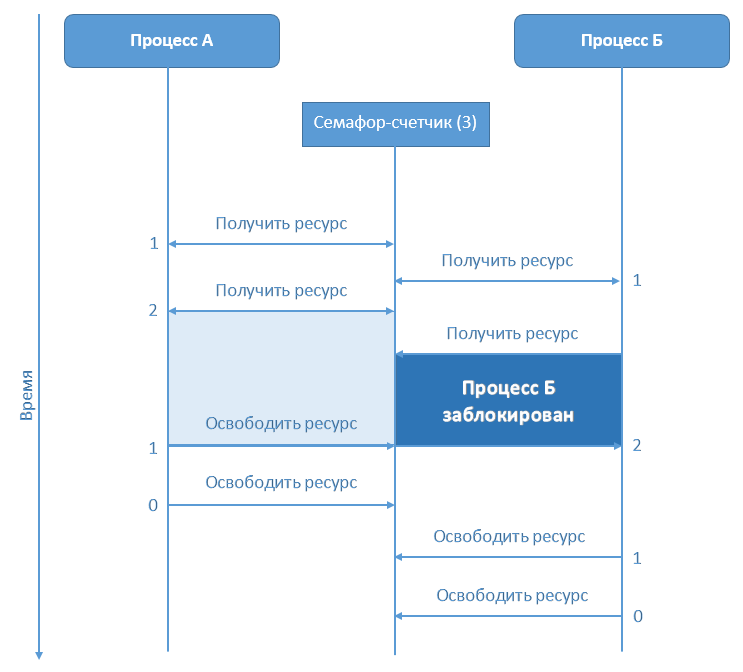

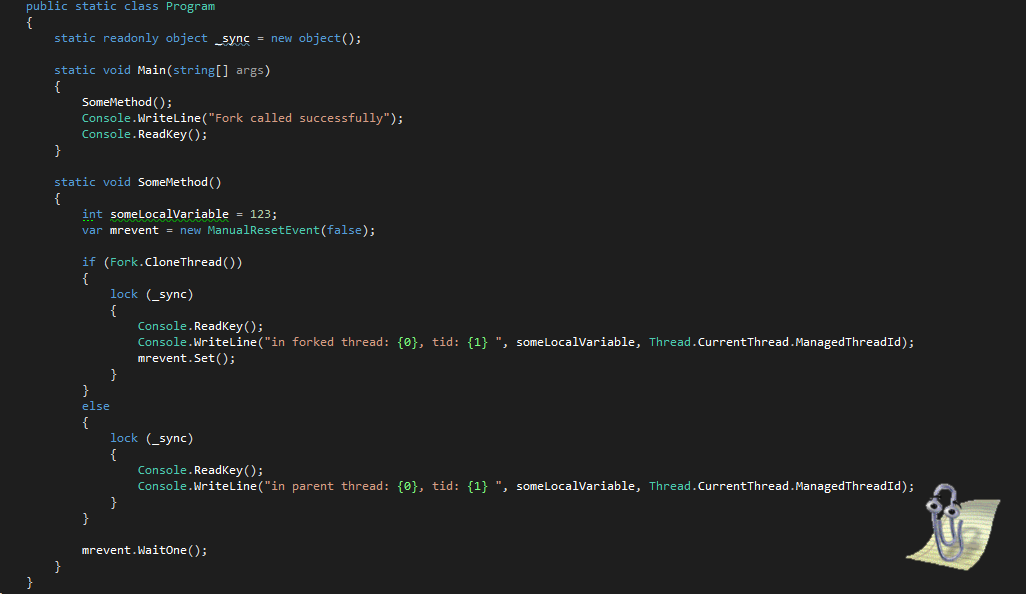

 Делаем отгружаемые сборки: взаимодействуем между доменами без маршаллинга
Делаем отгружаемые сборки: взаимодействуем между доменами без маршаллинга