Параллелизм без потоков: очевидно и вероятно
"Зацепила" крайняя статья про многопоточность [1]. Но, с другой стороны, - а что ожидал автор, предложив исходное решение без синхронизации? Получил то, что и должен был получить. На другое рассчитывать было бы достаточно наивно. Во-первых, потому, что используется весьма проблемная модель параллелизма. Во-вторых, расплывчатое представление о решаемой проблеме (по крайней мере, если судить по описанию). Но это уже мое личное мнение и хотелось бы его пояснить. И не просто так, а подкрепив решением.
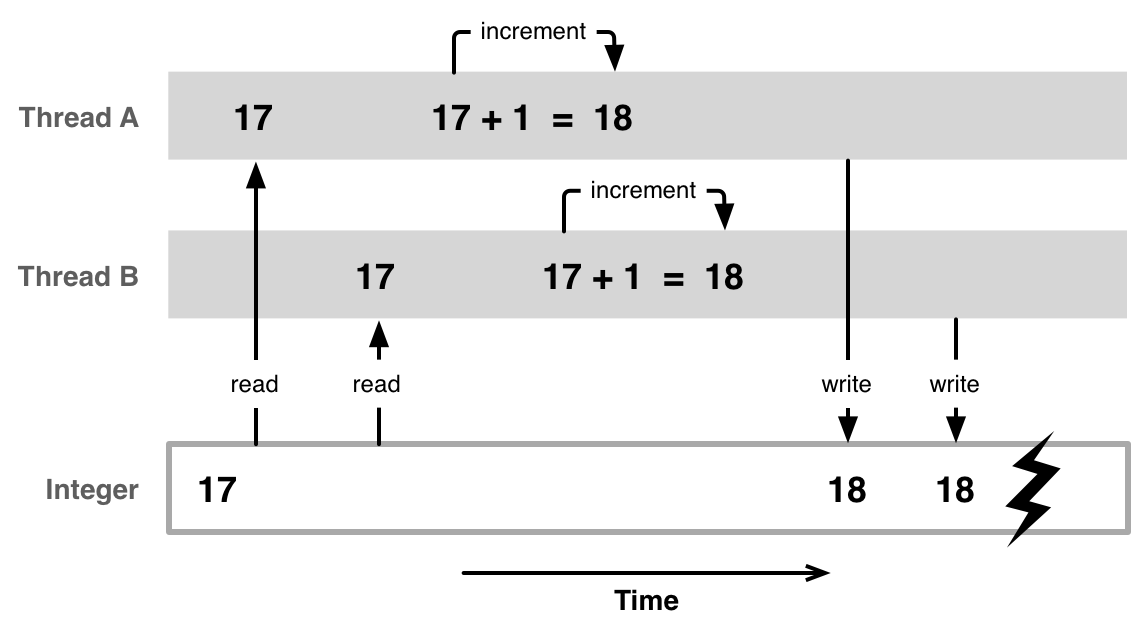
Имеем счетчик. Только это уже не просто счетчик, а общий ресурс, с которому пытаются получить доступ множество параллельных процессов. Налицо некая общая проблема, с которой приходится сталкиваться на практике. Тут можно добавить, что проблема эта давняя, рассматривалась не раз и ее решений предлагалось множество.
Но, может, автор достиг чего-то нового? Да, вроде, нет. То, что нужно синхронизировать - не новость. Нов ли предложенный механизм синхронизации? Не знаю, поскольку не специалист в Python. Надеюсь такие найдутся и ответят на этот вопрос.
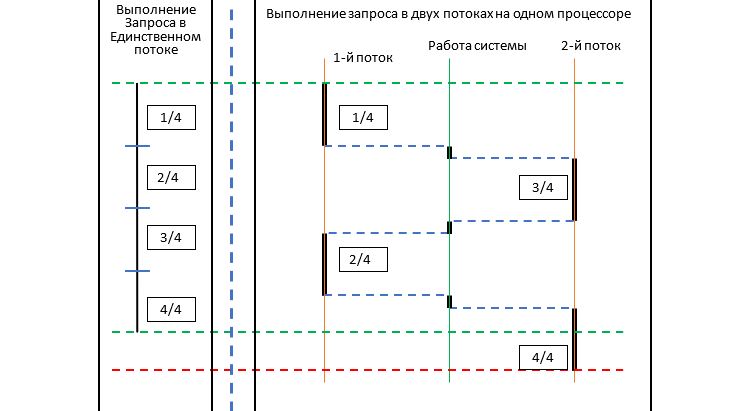
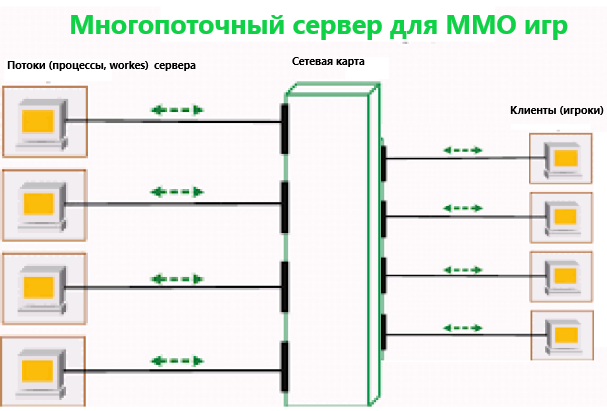
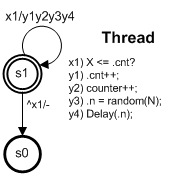
Покажу, как подобные проблемы решаю я. Причем совсем не прибегая ни к многопоточности, ни к всему тому, что нынче на волне успеха в так называемом параллельном программировании. И, как сказал автор статьи, "не спешите закрывать вкладку", а посмотрите, что будет дальше. А вдруг вам понравится?
Но для начала...
Краткая история вопроса
Использование переменной-счетчика в качестве общего ресурса - отнюдь не новость. Это элементарный и естественный подход к демонстрации проблем множества параллельных процессов. Насколько я припоминаю, впервые с подобным примером в серьезной литературе я столкнулся в книге [2].Предлагаемые там решения не вызвали восторга, а потому были задвинуты. И, кстати, об этом я не испытываю сожаления.