Сайт мониторинга ситуации по коронавирусу Соединенного Королевства - основной сервис отчетности во время пандемии COVID-19 для всей страны. Он испытывает нагрузку порядка 45–50 миллионов запросов в день и относится к национальным сервисам критической важности.
Мы работаем в соответствии с архитектурой active-active, что значит, у нас есть минимум две, часто - три экземпляра каждого сервиса, которые запущены в разных географических локациях.
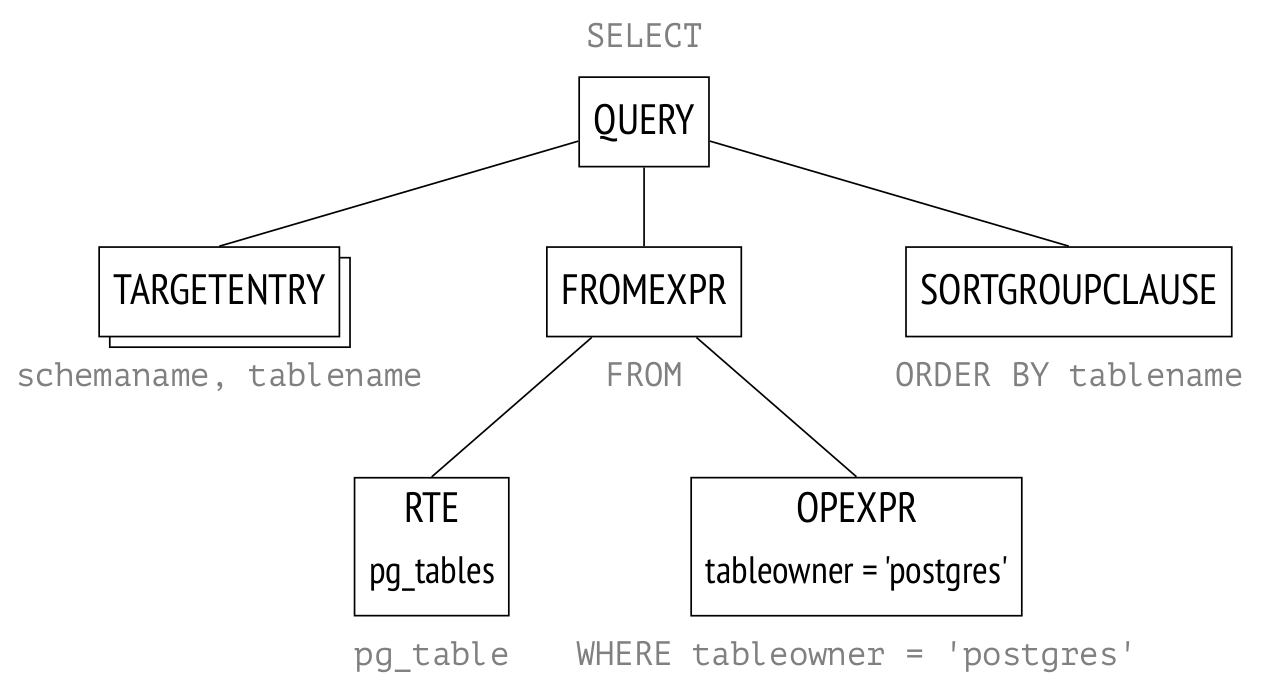
Есть только одно исключение - наша база данных. Сервис работает с использованием специальной версии PostgreSQL: Hyperscale Citus. Тот факт, что наша база данных не соответствует архитектуре active-active — это не следствие того, что мы не знаем, как делать реплики для чтения, скорее - результат логистических проблем, обсуждение которых выходит за рамки этой статьи.
Тем не менее, база данных работает в высокодоступной экосистеме, где сбойный экземпляр может быть заменен в течение пары минут.