
Как фермеру узнать состояние своих полей по NDVI?
3 мин
Туториал

В данной статье я не буду вдаваться в подробности теории, предполагаю, что вы знаете для чего нужен этот индекс. Моя задача - показать, как вам можно его получить.
В данной статье я не буду вдаваться в подробности теории, предполагаю, что вы знаете для чего нужен этот индекс. Моя задача - показать, как вам можно его получить.

Раскрашивание изображений с использованием нейронных сетей
DeOldify — это проект, основанный на глубоком обучении, для раскрашивания и восстановления изображений. Модель использует архитектуру NoGAN для обучения модели.
Мы будем использовать эту модель, чтобы преобразовать некоторые черно-белые фотографии, добавив к ним цвет.

В июне Яндекс опубликовал нейросеть YaLM 100B. Нейросеть умеет генерировать тексты. А это очень мощная вещь, можно попробовать массу всего полезного (и не очень) создать с ее помощью, от сюжетов для книг, игр и приложений, заканчивая рерайтом статей или того хуже, дорвеями.
Эта штука имеет лицензию Apache 2.0. Но чтобы запустить нужно ~ 200GB GPU видеопамяти!
И еще есть нюанс, проверить нейронку в работе, не так-то просто. Яндекс не предоставили ни демок, ни инструкций, как запустить бюджетно YaLM 100B. Пока все ждут урезанную или онлайн версию, я познакомился с ней поближе. Об этом и лонгрид.
Спойлер, дальше рассказ пойдёт о том, через что я прошёл и результаты. Исходников не будет.
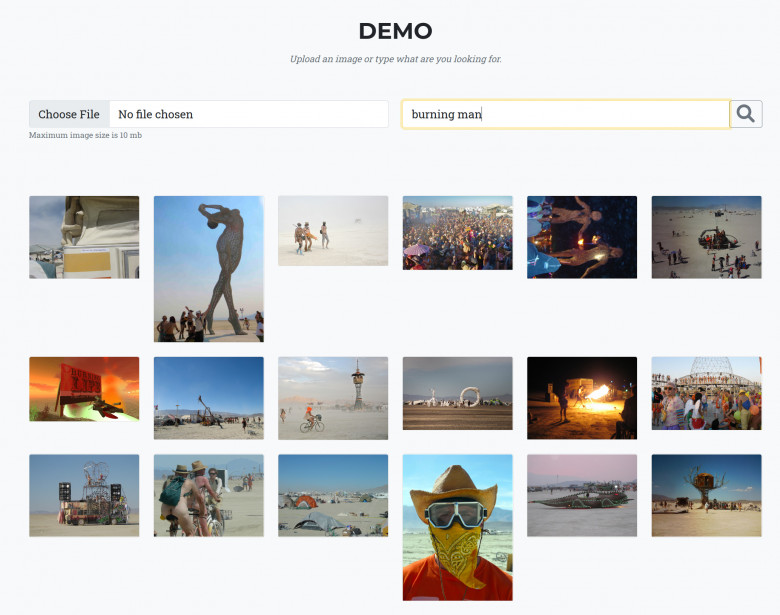
По этой ссылке приложение для поиска по датасету Open Images and Places 365 (3.5 миллиона картинок)
Загружаете свою картинку - получаете 18 похожих.

Развитие методов глубокого машинного обучения привело к росту популярности нейронных сетей в задачах распознавания образов, машинного перевода, генерации изображений и текстов и многих других. С 2009 года нейронные сети попытались применить напрямую в задачах обработки графов (к которым могут относиться системы веб-страниц, связанных ссылками, словари с определенными отношениями между словами, граф социальных связей и другие) и среди возможных задач можно определить поиск кластеров узлов, создание новых графов на основе имеющейся информации о структуре графа, расширение графа и предсказание новых связей и другие. Сейчас выделяют несколько типов нейронных сетей на основе графов - сверточные графовые сети (Convolutional Graph Network), графовые изоморные сети (Graph Isomorphism Network) и многие другие и они часто используются для анализа цитирования статей, исследования текста (представление предложения как графа с указанием типов отношений между словами), изучения взаимосвязанных структур (например, исследования белковых молекул, в частности сеть Alphafold использует модель GNN) и т.д. В статье мы рассмотрим некоторые общие вопросы создания и обучения графовых сетей на основе библиотеки Python Spektral.
 Привет, Хаброжители!
Привет, Хаброжители! 
Привет, Хабр! На связи Глеб, ML-разработчик Friflex. В предыдущих статьях мы научились работать с объектами, настраивать свет и камеры, редактировать материалы (aka. текстуры) через api. В заключительной части знакомства с Blender мы рассмотрим две темы: сборка проекта из разных файлов и запуск рендеринга через консоль. В Friflex мы используем Blender в работе над idChess (интеллектуальной платформой для распознавания и трансляции шахматных партий) и другими проектами по оцифровке спорта.

Вчера на официальном сайте был опубликован первый релиз-кандидат Python 3.11, который принесет важные оптимизации и доработки в возможности языка. Релиз планируется в октябре этого года, но уже сейчас можно поэкспериментировать с новыми возможностями и сегодня мы поговорим о группах исключений и асинхронных задач. Первые позволяют одновременно выбрасывать и обрабатывать несколько исключений, в то время как вторые позволяют объединять задачи в общий event loop и координированно управлять группами задач.

Год назад для собственных нужд я написал обертку Yandex SpeechKit на Python, она получилась настолько простая и универсальная, что грех не поделиться : )

Товарищи! PyCon Russia 2022, о необходимости которого все время говорили большевики питонисты, совершился! 30 и 31 июля в Москве состоялась самая долгожданная, уютная и душевная конференция для python-разработчиков и специалистов data science и ml. Мы выдохнули и спешим рассказать, как это было.
Не секрет, что этот год для организации IT-движух выдался трудным (как, впрочем, и предыдущие два). Кто-то уже релоцировался, кто-то в процессе, а кому-то участвовать не позволила религ обстановка в стране… Поэтому мы невозможно рады, что наш PyCon Russia состоялся! Спикеры были крутые, доклады классные, а участников оказалось ничуть не меньше, чем в более спокойные годы. Спасибо всем, кто в нас поверил, – вместе мы опять сделали тусовку незабываемой. А теперь к сути.

На данный момент Python является самым популярным языком программирования, который применяется для анализа данных или в машинном обучении. Сильными сторонами Python являются его модульность и возможность интегрироваться с другими языками программирования.
В науке о данных разведочный анализ данных (exploratory data analysis, EDA) является самым важным этапом в проекте и занимает около 70-80% времени всего проекта. Такой анализ позволяет изучить какие-то свойства данных, найти в них закономерности, аномалии, очистить их, подготовить и построить начальные модели для дальнейшей работы. На этом этапе можно определить вид распределения, оценить основные его параметры, обнаружить выбросы, построить матрицу корреляции признаков и т.д.

4х повышение разрешения изображения с использованием ESRGAN
В данной статье разобрано применение предобученной нейронной сети ESRGAN для увеличения разрешения изображения в четыре раза c использованием tensorflow hub.

Привет, Хабр! Каждый день тысячи программистов трудятся не покладая рук. Они пишут код, контактируют между собой и, как и любой человек, совершают ошибки. Проблемы в коде могут повысить уровень рисков и стать критическими для компании. И с целью выявления таких ошибок специалисты проводят анализ кода.

В Python, с каждым релизом, добавляют новые модули, появляются новые и улучшенные способы решения различных задач. Все мы привыкли пользоваться старыми добрыми Python-библиотеками, привыкли к определённым способам работы. Но пришло время обновиться, время воспользоваться новыми и улучшенными модулями и их возможностями.

Данный туториал является переводом статьи, написанной Stephen Grupetta. Все изображения и коды скопированы без изменений. В конце вы найдете примечания относительно данной информации, а также ссылку на github с работающим кодом. Если код, приведенный автором не запускается, переходите в примечания и, возможно, сможете найти решение вашей ошибки.

Узнал я о линейной регрессии после того, как встретил деревья, нейронные сети. Когда мы с другом повторно изобретали велосипед, обучая с нуля word2vec и использовали логистическую регрессию с векторами из обученной модели для задачи NER – я активно кричал о том, что линейная регрессия – прошлый век, никому она уже совсем не нужна.
Да, проблема была в том, что я совсем не разобрался в вопросе и полез в бой. Но практику в универе нужно было как-то закрывать.
После семестра мат. статистики ко мне пришло прозрение.

Цель статьи — описать алгоритм действий поиска открытого API сайта.
Целевая аудитория статьи — программисты, которым интересен парсинг и анализ уязвимостей сайтов.
В статье рассмотрим пример поиска API сайта edadeal.ru, познакомимся с протоколом google protobuf и сравним скорость различных подходов парсинга
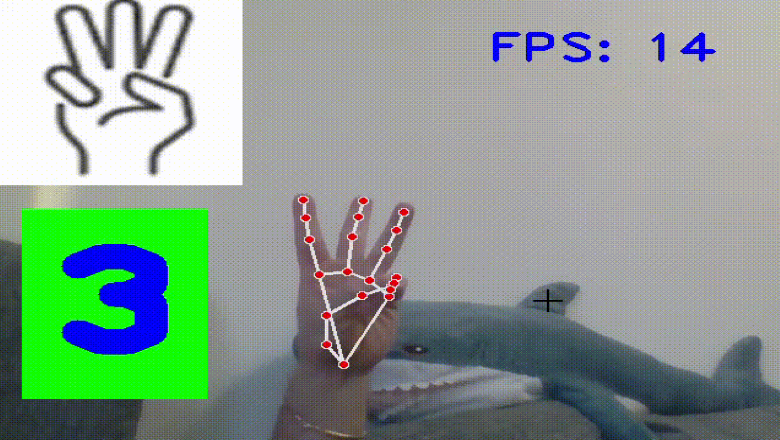
В данной статье хочу рассмотреть банальный и не сложный проект, а именно подсчет количества поднятых пальцев.
Все исходники можно найти на моем Github.
Код будем рассматривать с самого начала, но лучше всего ознакомиться с моими предыдущими статьями.
Подготавливаем среду и устанавливаем следующие библиотеки:

__subclasshook__ — один из моих любимых элементов Python. Абстрактные базовые классы (ABC — Abstract Base Class) с помощью __subclasshook__ могут указывать, что считается подклассом ABC, даже если целевой класс не знает об ABC: