19 способов сделать сокет-сервер на Python. Эволюционный подход. Часть 1. Введение
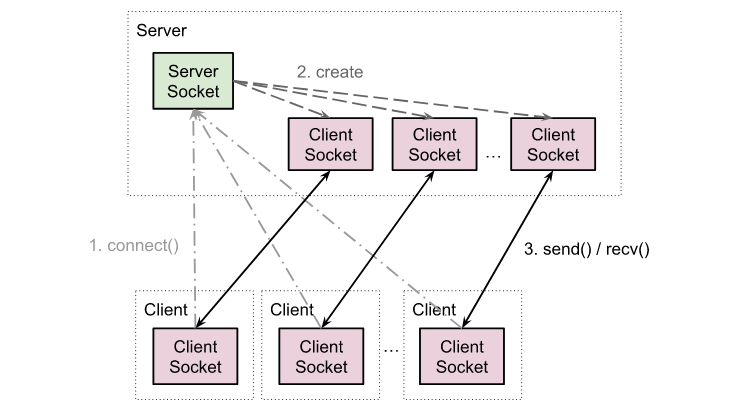
Дабы исчерпать до дна тему сокетов в Python я решил изучить все возможные способы их использования в данном языке. Чтобы всех их можно было испытать и попробовать на зуб, были созданы 19 версий простого эхо-сервера: от примитивного использования класса socket до asyncio. Блокирующие и неблокирующие сокеты, процессы и потоки, select'ы и selector'ы, коллбеки и сопрограммы — все эти темы расположены в эволюционном порядке, чтобы один пример плавно перетекал в другой.
Отдельно разобрано появление асинхронности в Python. На примерах детально показано, как и зачем появились итераторы, из них — генераторы, сопрограммы. Ближе к концу построен учебный макет библиотеки asyncio с минимально необходимым кодом, чтобы любой (даже такой, как я) смог разобраться, как на самом деле устроена асинхронность, как там все внутри работает.
Пишу подробно, чтобы случайно чего не пропустить. Поэтому понятно должно быть всем.