Призрак локомотива или биржевой рынок через призму корреляций
12 мин
Recovery Mode
В этой статье будет продемонстрирована техника обработки информации по биржевым котировкам с помощью пакета pandas (python), а также изучены некоторые «мифы и легенды» биржевой торговли посредством применения методов математической статистики. Попутно кратко рассмотрим особенности использования библиотеки plotly.
Одной из легенд трейдеров является понятие «локомотива». Описать ее можно следующим образом: есть бумаги «ведущие» и есть бумаги «ведомые». Если поверить в существование подобной закономерности, то можно «предсказывать» будущие движения финансового инструмента по движению «локомотивов» («ведущих» бумаг). Так ли это? Есть ли под этим основания?

Одной из легенд трейдеров является понятие «локомотива». Описать ее можно следующим образом: есть бумаги «ведущие» и есть бумаги «ведомые». Если поверить в существование подобной закономерности, то можно «предсказывать» будущие движения финансового инструмента по движению «локомотивов» («ведущих» бумаг). Так ли это? Есть ли под этим основания?
 В предыдущей
В предыдущей 

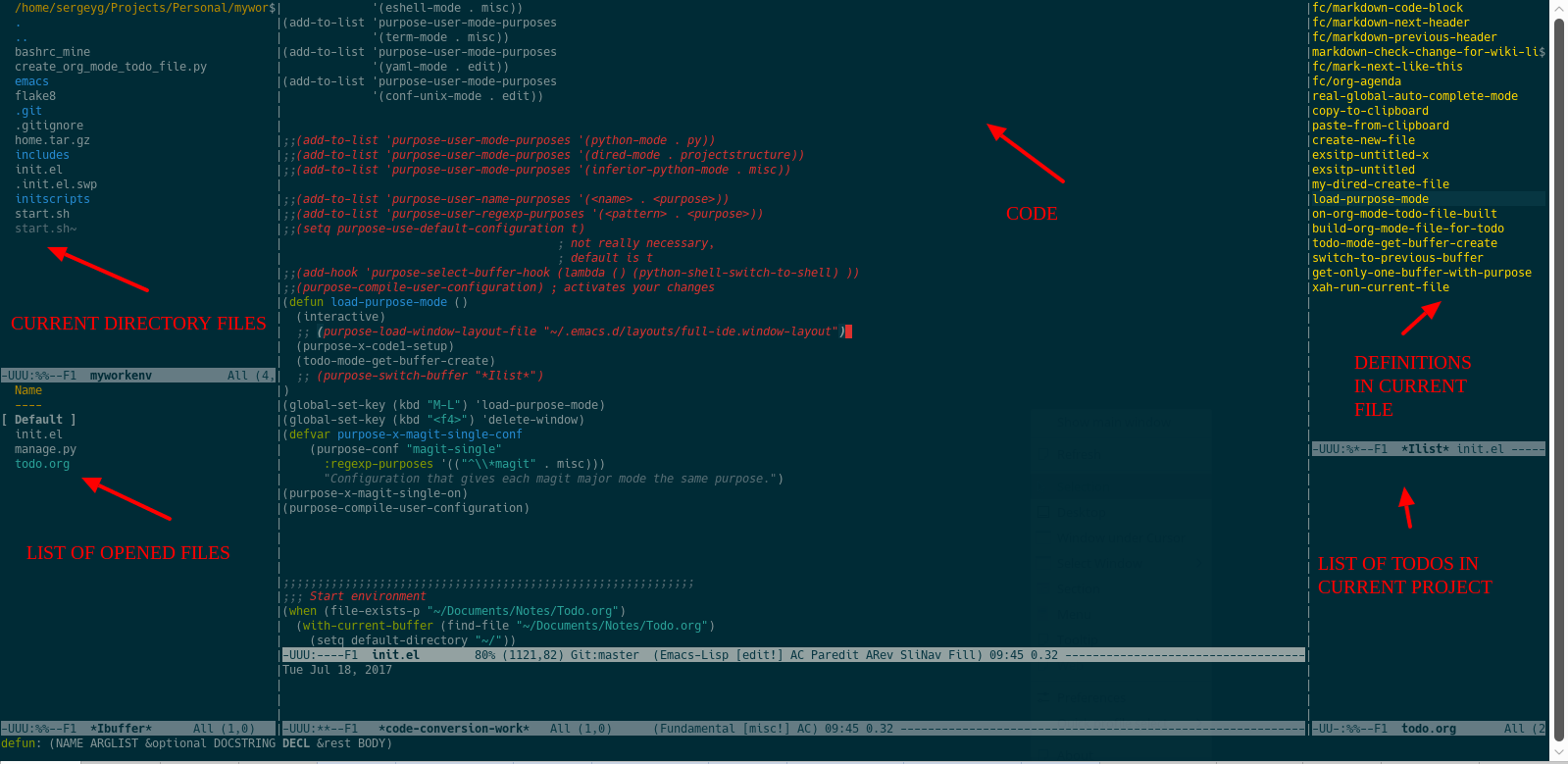





 Всем привет! Это уже тринадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python.
Всем привет! Это уже тринадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python.