Наверняка, каждый, кто хоть раз писал что-то на Python, задумывался о том, как распространять свою программу (или, пусть даже, простой скрипт) без лишней головной боли: без необходимости устанавливать сам интерпретатор, различные зависимости, кроссплатформенно, чтобы одним файлом-exe'шником (на крайний случай, архивом) и минимально возможного размера.
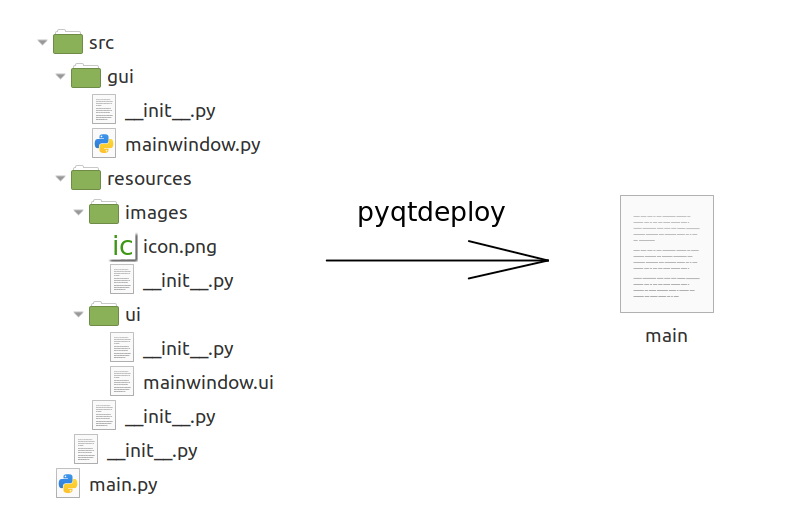
Для этой цели существует немало инструментов: PyInstaller, cx_Freeze, py2exe, py2app, Nuitka и многие другие… Но что, если вы используете в своей программе PyQt? Несмотря на то, что многие (если не все) из выше перечисленных инструментов умеют упаковывать программы, использующие PyQt, существует другой инструмент от разработчиков самого PyQt под названием pyqtdeploy. К моему несчастью, я не смог найти ни одного вменяемого гайда по симу чуду, ни на русском, ни на английском. На хабре и вовсе, если верить поиску, есть всего одно упоминание, и то — в комментариях (из него я и узнал про эту утилиту). К сожалению, официальная документация написана довольно поверхностно: не указан ряд опций, которые можно использовать во время сборки, для выяснения которых мне пришлось лезть в исходники, не описан ряд тонкостей, с которыми мне пришлось столкнуться.
Данная статья не претендует на всеобъемлющее описание pyqtdeploy и работы с ним, но, в конце концов, всегда приятно иметь все в одном месте, не так ли?