
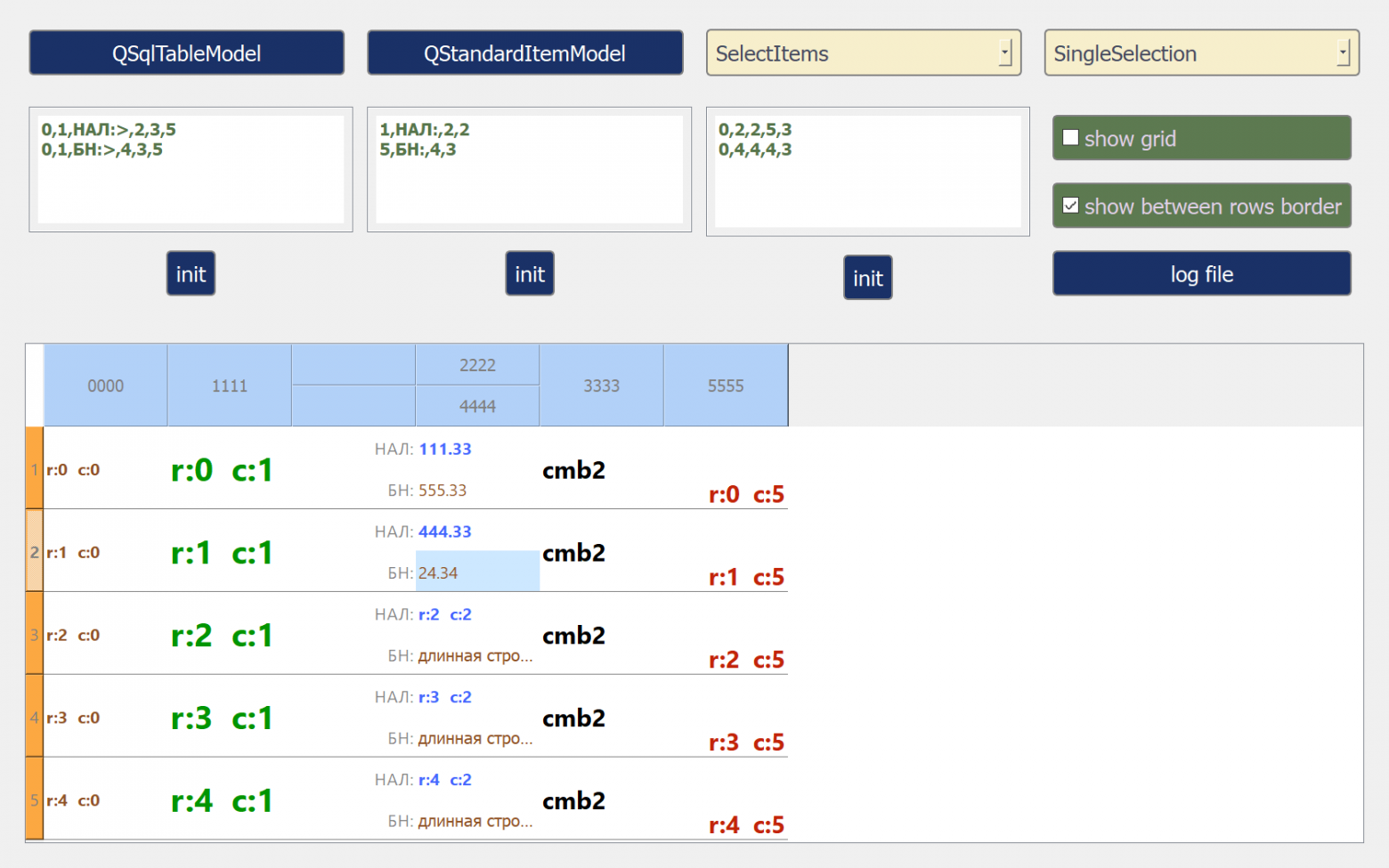
Создаем свой кастомный стиль для QTableView без css стилей и переопределения ролей модели данных. Занимаемся отрисовкой напрямую.
Создаем свой кастомный стиль для QTableView без css стилей и переопределения ролей модели данных. Занимаемся отрисовкой напрямую.

Привет, меня зовут Артём Коршунов, я программист в ЮMoney. В нашей команде много разработчиков, и все они пишут огромное количество кода. Его нужно проверять, но встроенных валидаций для проверки не всегда хватает, из-за чего могут возникать проблемы. Рассказываю, с какими сталкивались мы, пока не попробовали DacFx с объектной моделью и не автоматизировали валидацию.
Привет!
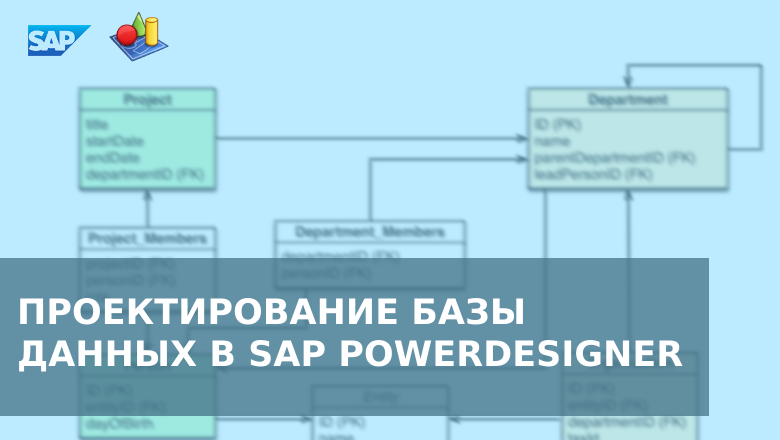
Проектирование базы данных - это один из важнейших этапов создания информационной системы. Оно включает в себя определение сущностей, их атрибутов и связей между ними, а также выбор наиболее подходящих типов данных и ограничений целостности.
В данной статье мы рассмотрим процесс проектирования базы данных с нуля (в качестве примера возьмем только один слой БД - витринный, он же Data Mart) с использованием ПО SAP PowerDesigner. В качестве СУБД мы будем использовать Oracle 19c, но вы можете выбрать любую другую, по вашим потребностям (как - об этом чуть ниже).
Рассмотренный в статье инструмент будет интересен системным аналитикам, архитекторам, разработчикам БД и даже бизнес-аналитикам, поскольку помимо создания физических и логических моделей в нем можно рисовать ER-диаграммы, BPMN-модели и многое другое.

Чем вызваны тормоза в PDM, PDM, ERP?
Вообще тормоза в большинстве современных систем мало связаны с тем, что программа может быть еще в разработке или что там может быть что-то не совсем оптимально сделано, хотя и не без этого.
Тут сам по себе важен принцип баз, на которых построены эти программы.
Большинство современных систем построено на MSSQL и его аналогах; впрочем некоторые из них в какой-то мере могут работать лучше, а в чем-то могут быть и хуже, да и развитие самой MSSQL не стоит на месте: что-то улучшается, что-то «оптимизируется». Некоторые пользователи уже давно считают, что имеет место заговор IT-гигантов с производителями электроники, и некоторые «оптимизации» сделаны специально для замедления работы. Впрочем, такие заговоры уже не раз вскрывались, и никто с этим так ничего и не сделал, а все подобные дела просто спускались на тормозах.
Рассмотрим принцип работы баз на основе PDM.
В данной статье хочу поднять тему, которая представляет собой одну большую боль для администраторов, разработчиков и тестировщиков высоконагруженных (и не очень) систем под управлением PostgreSQL. Даже не «боль», а «БОЛЬ»!
Удивительно, что за почти 30 лет существования PostgreSQL не появилось нормальных инструментов для получения вменяемых счетчиков и трассировок. Все, кто работают с MS SQL Server используют профайлер. Это обязательный и привычный инструмент, который позволяет вылавливать запросы, интересные нам в рамках исследования. Вылавливать как все запросы без разбора, так и какие-то единичные запросы, которые удовлетворяют правилам отбора. Кроме того, можно настроить не одну трассу, а столько сколько нужно, с разными фильтрами. Эти трассы содержат очень богатый набор измерений для анализа: – Reads физические и логические; Writes; SPID, Процессорное время; план запроса (хэш плана), количество строк и т.д.
Многие компании стали всерьез рассматривать СУБД PostgreSQL как замену MSSQL и сталкиваются с тем, что возможностей для ее мониторинга просто нет – она как черный ящик, в котором наощупь вылавливаешь какую-ту информацию и пытаешься систематизировать ее хоть как-то.

Привет, Хабр! Меня зовут Александр Сушков, я аналитик данных, эксперт по SQL, автор, преподаватель и наставник курсов «SQL для работы с данными и аналитики» и «Аналитик данных».
Один из самых распространённых операторов в SQL — это JOIN. В статье расскажу об особенностях этого оператора: как использовать другие операторы в JOIN после ON, кроме «равно», и зачем это может быть нужно.

Как ЮMoney работает с данными в DWH на Microsoft SQL Server — ежегодный митап High SQL
ИТ-специалисты, вы тут? Начинаем наши митапы, и первый на очереди — High SQL.
Встречаемся 27 апреля в 18:00 по Москве.

Эта статья о том, как аналитик изучает основы SQL, какие допускает ошибки и как старается их исправить. В статье будет то, что помогает погрузиться в SQL впервые: схемы и примеры кода, понятия и определения, проблемы и решения. Статья рассчитана на аналитиков-новичков.
Предыстория: аналитик создает отчёты в BI для директора компании «ABC». Аналитик не умеет программировать и подключается к данным по инструкции. Директор требует срочно добавить в отчёт данные из 3 источников: SAP – объем выручки от продаж; HRLink – затраты на персонал; Битрикс – время обработки заявок.
Аналитик ставит задачу data инженеру на добавление новых данных в BI. Data инженер – единственный специалист по работе с данными в офисе из 400 человек. Он критически оценивает сроки выполнения задачи и объявляет: «Минимум – 2 недели». Такой срок директора не устраивает. Инженер предлагает аналитику альтернативное решение...

Привет, Хабр! Меня зовут Федор Тюрин, я руководитель команды продуктовой аналитики в Учи.ру. Мы проводим очень много А/Б-тестов (десятки запусков в неделю и сотни в течение года). В таких условиях очень важна автоматизация процесса анализа и подведения итогов теста.
Всем привет! Я занимаюсь NLP в сфере Data Science и хочу поделиться результатами разработки Telegram-бота, у которого под капотом уже 15 нейросетей. Речь идёт о TurboText_bot. Он будет полезен всем, кто причастен к созданию контента. К таким можно отнести блогеров, журналистов, копирайтеров и многих других специалистов.. Даже бабушек у подъезда, ведь бот способен генерировать и обрабатывать новости.
Что удалось реализовать?
Одно я могу сказать точно: миграция данных между двумя БД - это одна из, если не самая сложная часть при смене СУБД или схемы базы данных. И что-то мне подсказывает, что Вы не фанат громоздких, чрезвычайно трудно отлаживаемых, SQL конструкций.
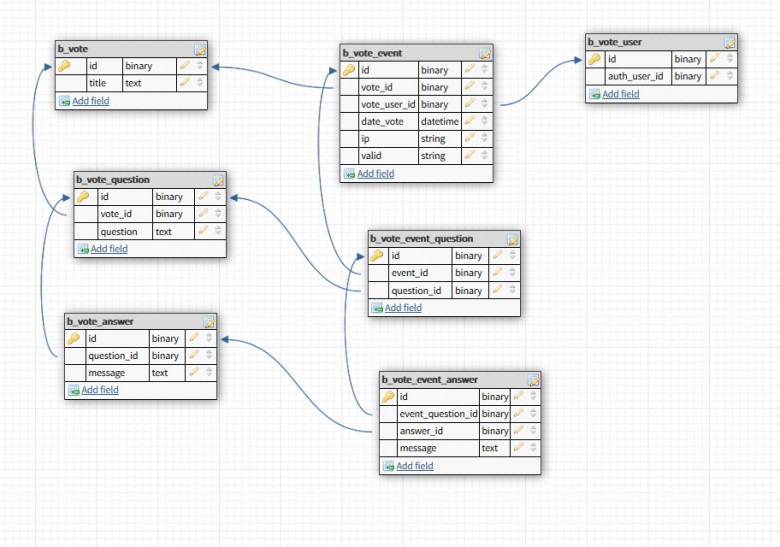
Статья направлена на решение проблемы "зависания" выгрузки результатов опросов при использовании модуля Vote 1С-Битрикс в случае, если в опросе много вопросов или ответов. Так-же в статье реализована выгрузка в Excel SQL-запроса при заранее неизвестном количестве полей, т.е. каждое поле формируется динамически.

Привет, Хабр!
Меня зовут Марк Порошин, я занимаюсь DataScience в DV Group. Недавно я уже рассказывал про то, как начать трансформировать данные с помощью dbt. Сегодня я решил поделиться, как мы в DV Group поженили dbt, Greenplum и DataVault, собрали все грабли, что могли; немного поконтрибьютили в open-source, но по итогу остались очень довольны результатом.
Расскажу сначала пару слов о том, что такое DataVault. DataVault - методология построения хранилища, предполагающая высокую нормализацию данных (3ая нормальная форма). Основными ее компонентами являются:

Геймификация — это процесс использования игровых элементов в неигровом контексте. Он имеет много преимуществ по сравнению с традиционными подходами к обучению, в том числе:

В процессе обучения аналитике данных у человека неизбежно возникает вопрос о миграции данных из одной среды в другую. Поскольку одним из необходимых навыков для аналитика данных является знание SQL, а одной из наиболее популярных СУБД является PostgreSQL, предлагаю рассмотреть импорт и экспорт данных на примере этой СУБД.
В своё время, столкнувшись с импортом и экспортом данных, обнаружилось, что какой-то более-менее структурированной инфы мало: этот момент обходят на всяких там курсах по аналитике, подразумевая, что это очень простые моменты, которым не следует уделять внимание.
В данной статье приведены примеры импорта в PostgreSQL непосредственно самой базы данных в формате sql, а также импорта и экспорта данных в наиболее простом и распространенном формате .csv, в котором в настоящее время хранятся множество существующих датасетов. Формат .json хоть и является также очень распространенным, рассмотрен не будет, поскольку, по моему скромному мнению, с ним все-таки лучше работать на Python, чем в SQL.

X5 Tech приглашает студентов и выпускников вузов пройти бесплатное обучение по профессии Data Analyst. Уже через три месяца обучения можно будет пройти оплачиваемую стажировку в Х5 Group.

Недавно мне пришлось объяснять это нашим братьям меньшим на работе, и я решил написать текст, который может пригодиться. В конце вы найдете ссылку на полезный скрипт для MSSQL, а также Postgres и MySQL.
В идеальном мире, если в таблице миллион записей, а разных значений например всего 100K, то на каждое значение приходится по 10 записей. Но что делать, если в список ваших значений затесалось особое значение, например, NULL, пробел или 'n/a'? Для SQL optimizier это головная боль. Для вас тоже.
Картинка иллюстрирует людей со значением 'n/a' в поле SSN
Всем привет.
Я разрабатываю библиотеку для работы с Entity Attribute Value (репозиторий), сокращенно EAV (модель базы данных для хранения произвольных данных). В конце прошлой статьи я спросил у вас о чём мне ещё надо написать, вы попросили показать пример использования и сделать замеры быстродействия.
Что для нас важно при работе с данными ? Скорость записи (добавления или обновления) и скорость чтения (конкретно - фильтрации по моделям одной сущности). При чём скорость поиска в приоритете, потому что записываем мы один раз в цать дней, а читаем каждую минуту/секунду и даже не один раз, а может быть и не одну сотню раз.
Фишка библиотеки в том что бы работать не с представлением построенном на базовых таблицах EAV, а работать с небольшой частью этих данных записанных в отдельное материализованное представление или в отдельную таблицу.
В Новогодние каникулы я сделал замеры производительности и хочу с вами поделиться результатами
Что будем измерять ?
Чтение:
Время вычитывания всех позиций категории
Время формирования параметров фильтрации
Время фильтрации
Запись:
Время добавления новой характеристики (атрибута)
Время добавления новой товарной позиции (модели)
Время обновления товарной позиции

За время работы автору довелось использовать многие инструменты анализа, включая Excel, R и Python. Попробовав PostgreSQL и TimescaleDB, автор поняла, насколько простыми могут быть задачи очистки. Делимся подробностями сравнения PostgreSQL и Python из блога TimescaleDB, пока у нас начинается курс по аналитике данных.

Oracle Apex – компонент для разработки конечных приложений, входящий в состав поставки СУБД Oracle, позволяющий быстро «доставать» данные из базы и доставлять их через веб-интерфейс конечному пользователю. Как правило, данные для просмотра и редактирования выдаются в табличном виде и Apex предоставляет богатые возможности для настраивания отчета: можно накладывать фильтры, делать сортировку и группировку, скрывать имеющиеся столбцы и добавлять расчетные новые, делать сводные отчеты, выгружать данные в формате csv, pdf и даже Excel. Каждый пользователь может сохранить предпочитаемые им настройки каждого отчета как индивидуально, так и для совместного использования. В таком формате Apex функционирует у большинства наших заказчиков.
Однако мало кто использует довольно широкие возможности Apex’а для построения графиков. Эта тема, на наш взгляд, довольно интересна и мало освещена в интернете.
В этой статье будем предполагать, что читатель имеет представление о разработке приложений с помощью Oracle Apex.