
Полнотекстовый поиск FTS3, FTS4 и FTS5 в Android
10 мин
Полнотекстовый поиск необходим в приложениях для того, чтобы быстро находить совпадения в большом объеме данных. Такая возможность удобна, например, для поиска товаров, фильмов, рецептов, научных статей, а также фрагментов текста в электронных книгах. Хотя зачастую поиск реализуют на сервере, иногда бывает необходимо работать в оффлайне, повысить отзывчивость мобильного приложения, избежав задержек при взаимодействии с сервером. В таких случаях используют полнотекстовый поиск — Full-Text Search.
В этой статье рассмотрим особенности полнотекстового поиска в Android с использованием FTS3, FTS4 и FTS5. Статья будет наиболее полезна для читателей, знакомых с Android и SQLite.

В этой статье рассмотрим особенности полнотекстового поиска в Android с использованием FTS3, FTS4 и FTS5. Статья будет наиболее полезна для читателей, знакомых с Android и SQLite.
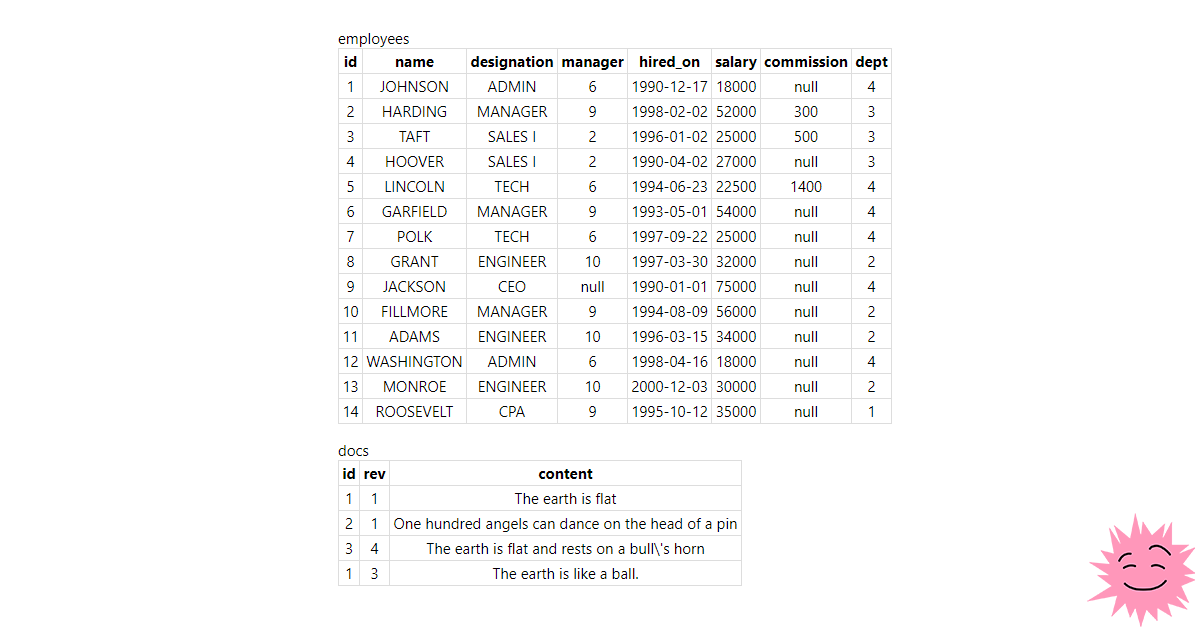







 Так получилось, что я очень люблю использовать SQLite СУБД.
Так получилось, что я очень люблю использовать SQLite СУБД. 

