Генеративные диалоговые модели: как мы разговорили виртуальных ассистентов Салют
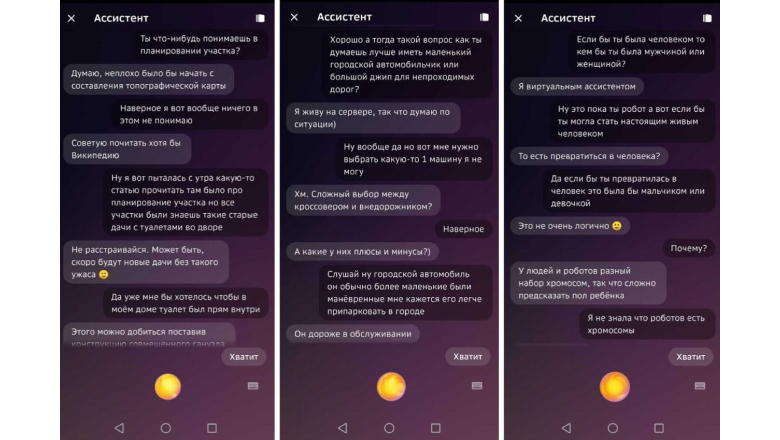
Порой люди обращаются к искусственному интеллекту не для того, чтобы заказать еду, найти подходящий фильм или решить какую-то ещё свою задачу, а для того, чтобы просто поболтать. Например, потому что грустно, а рядом нет тех, с кем было бы удобно про это поговорить. И пусть виртуальные помощники пока не заменяют настоящих друзей или близких людей (они и не должны), но всё же они могут поднять настроение, помочь снизить уровень напряжения. Чтобы такое общение было живым и действительно интересным, мы разработали и применяем мощные разговорные модели на русском языке для виртуальных ассистентов Салют в режиме «Собеседник». Так, за Сбера с пользователем общается SBERT (retrieval-модель), за Джой — ruGPT-3 (генеративная модель), а за Афину — обе сразу. Поговорим сегодня о генеративной части.
Передаю слово моему коллеге, руководителю RnD NLP SberDevices Валерию Терновскому.