Привет, меня зовут Ярослав Иссинский, я руководитель Технической платформы в группе «М.Видео-Эльдорадо». Сегодня я хочу рассказать про переход в публичное облако на примере крупной ритейл-компании.
Техническая платформа – это два крупных продукта, которые предоставляют полную экосистему для разработчиков.
Переход в публичное облако

Прежде всего, мы предоставляем среды. В облаке крутятся IaaS, PaaS и Managed Services. При этом мы используем как cloud-managed вещи типа Kubernetes и Database as a service от облачного провайдера, так и self-managed сервисы от нашей команды, например, стек Observability или хранилище артефактов типа Nexus и Harbor.
Также мы предлагаем командам экосистему для разработки – Jira для таск-трекинга, Git для хранения кода, шаблоны CI/CD пайплайнов и собираем для всего этого процессные метрики, например, лид-тайм и частоту релизов.
В моей истории будет два блока – теоретический и практический. Я расскажу про антипаттерны и про то, что с позиции моего текущего опыта считается правильным.
Зачем переходить в облако
Самые популярные заблуждения гласят, что ресурсы в облачной среде обходятся дешевле, что облако надежнее и что больше вам не нужна экспертиза, потому что у облачного провайдера собрались самые крутые специалисты на рынке. Это не так. На самом деле по сравнению с железным сервером за стенкой ресурсы в облаке стоят гораздо больше. Зато в облаке вы сможете избежать тендеров и выиграть полгода времени, если вам на месяц или два для какой-то гипотезы нужен десяток тысяч CPU. С надежностью во многом всё будет зависеть от вас. И во многом это будет определено экспертизой ваших команд.

И, да, за счет автоматизации в облаке вы сможете построить удобные процессы. При этом стоит быть готовым к необходимости наращивать дополнительную экспертизу в каждой команде.

Антипаттерном будет отдать облака на откуп текущей команде инфраструктуры, которая раньше не работала с облаками. Они принесут с собой старые неповоротливые процессы и весьма вероятно, что у них не будет необходимой экспертизы. Точно так же будет неправильно отдавать всё на откуп привлеченным подрядчикам. Подрядчики приходят и уходят, а без экспертизы в облаке работать невозможно. Поэтому должна появиться команда, отвечающая за трансформацию в облака.

Ещё одним антипаттерном является lift and shift подход, когда в облако переносится абсолютно все, как есть, включая legacy. Миграция – это удобный момент для оценки всех систем и пропуска в облака только сервисов с cloud native архитектурой. А остальные сервисы либо остаются там, где они были, либо ждут рефакторинга.
Что говорит теорвер
Когда я устраивался в компанию, на последнем туре собеседования я спросил нашего ИТ директора: «Какую одну самую важную вещь внутри компании я должен сделать, чтобы ты был счастлив?» И он ответил: «Мы живем с облаком уже полгода. Сделай так, чтобы оно больше не падало!»
С одной стороны, это звучало парадоксально, поскольку непонятно, как я изнутри ритейла могу повлиять на облачного провайдера. А с другой стороны, это очень понятное требования бизнеса.
Давайте посмотрим, что можно сделать и как можно ухудшить или улучшить доступность систем в облаке. Представим для простоты, что все компоненты в облаке имеют доступность 99,95%. Если система состоит из одного компонента, то ее доступность будет 99,95%.

Теперь возьмем систему, состоящую из трех компонентов. Если отказ любого приведет к отказу всей системы, то доступность системы из трех компонентов будет на уровне 99,85%. Как мы видим, доступность стала хуже.

Теперь рассмотрим систему, которая спроектирована таким образом, что ее работоспособность сохраняется пока работает хотя бы один компонент. В этом случае вероятность отказа перемножается, и мы получаем доступность лучше 99,999%. При этом, заметьте, мы ничего не поменяли на стороне облачного провайдера.

Примерно такими задачами придется оперировать в первые год-два, пока все сервисы не переедут в облако.
Если надежности одного облака недостаточно, есть два варианта: либо нужно еще одно облако, либо как-то обеспечить независимость отказов в одном облаке.

Следующий шаг, где можно совершить ошибку, это не использовать подход Infrastructure as Code. Накликивание ресурсов в облаке мышкой или создание их руками инженеров service desk – чистое зло.
В Техплатформе мы создали шаблоны инфраструктурного кода для сервисов в облаке. Появляется новый продукт, ему в Git создается новый репозиторий инфраструктурного кода и из шаблонов создается код, из которого создаются ресурсы. В результате мы получаем всю историю изменений, можем отслеживать авторство этих изменений и получаем актуальную документированную инфраструктуру. Для IaaS и PaaS – Terraform, для микросервисов – Kubernetes и Helm чарты.
Техрадар или анархия
Самый демократичный и гибкий подход – это You build it, you run it и потом you pay for it. Хорошо работает, когда вы одна команда или стартап, другое дело – много команд в большой компании. В самом начале у вас будут как совсем зрелые команды, так и совсем не зрелые. И тут важно незрелые команды подтянуть к зрелости.

В нашей компании уровень зрелости достаточно высокий. Но подход You build it, you run it все равно неприменим, поскольку если одна команда для интеграции с Kubernetes будет использовать GitLab agent, вторая ArgoCD, а третья села и пишет что-то свое, «потому что мы так еще не делали», ваши команды зря тратят время и ресурсы компании.
Мы зафиксировали наш toolstack и techstack в техрадаре. Техрадар – это диаграмма, на которой визуализированы ИТ-технологии и инструменты с разбивкой по сегментам и кольцам. И провели границы «диктата» и «демократии» на уровне бизнес-доменов. Так был достигнут баланс между гибкостью и унификацией.
Разделите проекты, продукты и процессы
У нас происходят совершенно разные по своей природе активности. Предоставление ресурсов и инцидент менеджмент – это процессы. Разработка и улучшение сервисов – это спринты. Стратегии, roadmap, приоритеты – это продуктовый подход. И все они имеют совершенно разные принципы управления. К тому же, если возложить все задачи на одну команду, вы создадите огромную когнитивную нагрузку на людей.

Постарайтесь не потерять фокус, команды хотят законченный готовый продукт. Никому не нужен голый Kubernetes без логов. Разработчик не сможет дебажить без трейсов. SRE не сможет работать без метрик. Поэтому мы предоставляем целостную платформу, как для Kubernetes, так и для всех остальных сервисов.
Культура SRE
За каких-то десять с небольшим лет произошел стремительный переход от штучных железных серверов сначала к десяткам виртуалок, затем – к сотням микросервисов и managed services. Отслеживать их, сидя перед монитором с графиками, стало невозможно. А учитывая, что вы не имеете доступа к гипервизорам или виртуалкам с менеджед сервисами, задача только усложняется. Требуется создать процессы и инструменты, которые будут измерять и улучшать доступность.

Агрегация метрик
После внедрения SRE подходов, мы получили по дашборду для каждого нашего продукта и сервиса. Если на этом остановиться, то я получу для ста продуктов сто индивидуальных дашбордов, а общая картина мне будет не видна.

Здесь нам понадобился слой абстрагирования, который отделил бы специфичные метрики и содержал только информацию о текущем состоянии и доступности за отчетный период.
Приходит инцидент или вопрос «а посмотрите, что там с системой N», SRE инженер заходит на одну страницу и видит все сервисы, которые есть и их статус.
Постоянное улучшение
Ничего нельзя сделать сразу и хорошо. Мы всегда начинали с простых метрик и индикаторов. Система отвечает 200 ОК – отлично. Дальше берем эту систему и прогоняем по ней краш-тесты: отключаем виртуалки, отламываем ей ножки. Получаем индикаторы. Для первого релиза этого обычно достаточно.

Когда случится инцидент, и SRE-инженер сядет писать postmortem, он посмотрит, а было ли видно недоступность на этих графиках. Если да, с observability у вас все хорошо, если нет, это триггер, чтобы её улучшить.
При анализе причины каждой поломки необходимо либо зафиксировать, что это допустимый простой, либо отразить необходимые организационные и технические изменения.
Кто все это делает
Очень важно, чтобы SRE и DevOps были частью продуктовой команды. Есть продуктовая команда – должны быть свои DevOps и SRE. Иначе вы получите три разрозненные команды, которые будут перебрасываться друг с другом разными задачами.

У нас критерий очень простой: эти люди должны ходить на ретро и планирование своего продукта.
Кто за это платит
В 2021 году у нас в компании произошла продуктовая трансформация. И вместе с ней у каждого продукта появился свой бюджет. Бизнес стал понимать, как по продуктам распределяются деньги, которые раньше назывались «На IT».
А у продуктовых команд появилась заинтересованность в экономии своих ресурсов, потому что это их собственный бюджет. Мы оказались в нужное время в нужном месте, так что сейчас каждый product owner может посмотреть не только затраты на свой продукт с самого начала времен и до сегодняшнего дня, но и прогноз на следующий год.

Без чего все это не взлетит
Открытость! Знания сами по себе не распространяются. Мы целый год активно занимались евангелизмом, чтобы у нас появилось достаточно коммуникаций.
К нам на демо приходит примерно столько же людей, сколько человек в команде. И, кстати, эта метрика за которой мы следим и стараемся поддерживать. Еженедельно происходят кросс-командные синки с участием DevOps и SRE. У нас есть открытый технологический микрофон по пятницам, где коллеги делятся какими-то идеями и находками, которые потом могут превратиться в бизнес-сервисы.
Есть более редкие, но глобальные явления. Для актуализации техрадара есть архкомы. А синки бизнес-доменов друг с другом происходят примерно раз в квартал на уровне СТО и СРО.
Практика
На картинке вы видите два варианта как можно выкатить микросервис в Kubernetes.
Слева напрашивающийся вариант: делаем региональный кластер с воркерами в трех зонах доступности. Над ними стоит балансировщик, который равномерно разливает трафик по трем зонам.
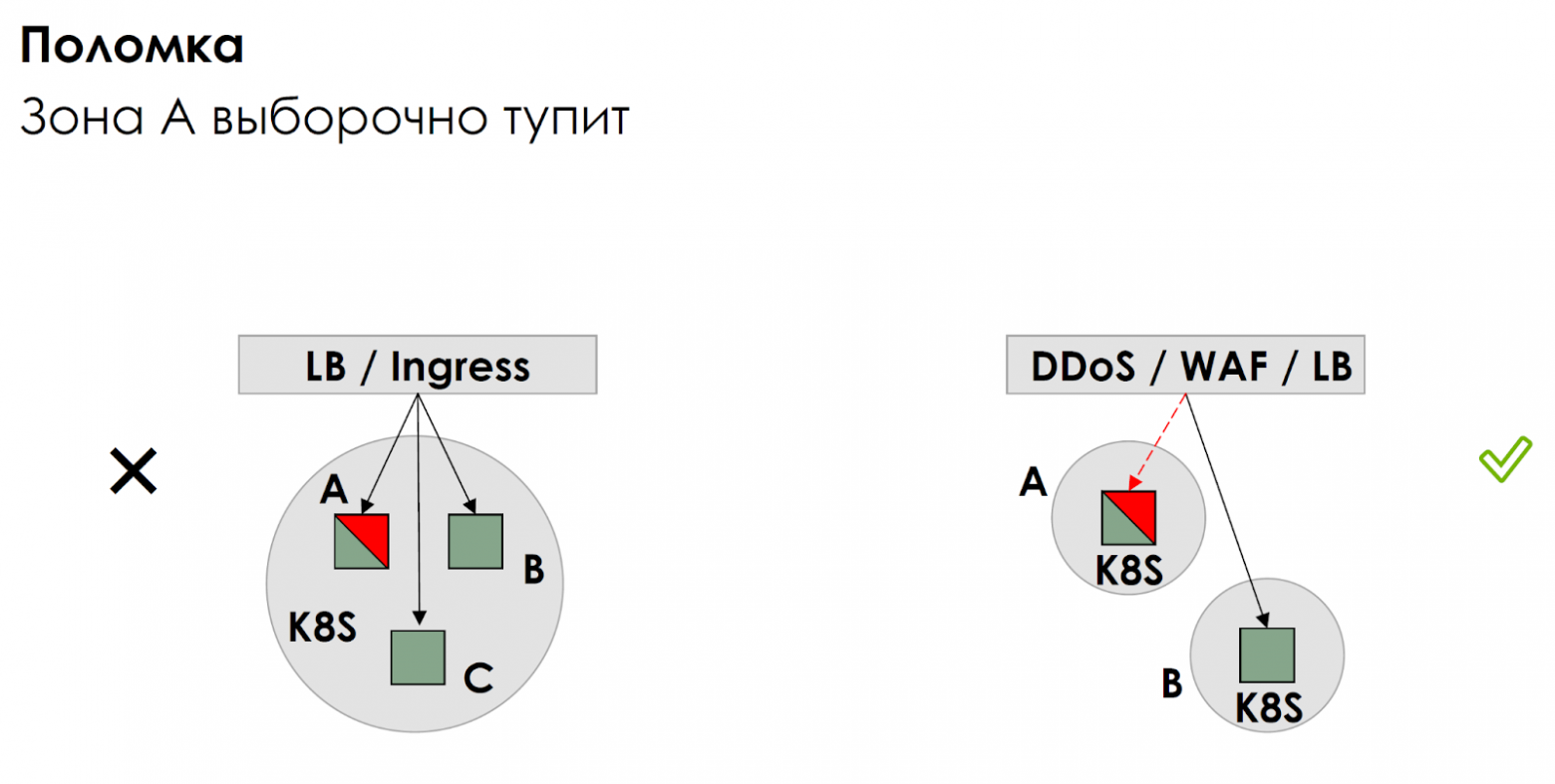
Обычно считается, что когда сломается зона, трафик польется в другие две и приложение будет работать. Проблема приходит, когда сеть в одной зоне начинает тупить или когда в неё выборочно приходят сетевые ножницы, а с software defined networks так бывает. С точки зрения кубера все хелсчеки проходят. А с точки зрения клиентов для трети обращений вы нарушите SLA.
Сначала у нас были Яндекс Облако и AWS, и мы переключали трафик в случае аварий. Это было дорого, но работало. Потом мы сделали по окружению в зоне А и зоне B, а логику балансировки и переключения перенесли на сервис защиты от DDoS на WAF.
В результате мы получили управляемую историю, к тому же значительно сократили сетевые задержки, потому что трафик попадал в одну зону и оставался в ней безо всяких Istio, даже если разработчики допустили паттерн «клубок шерсти».

На картинке дашборд Jira, как пример работы с метриками. Данные по времени ответа я беру с балансировщика, но каждые 15 секунд в нее собирается куча обращений пользователей. Какое значение мне брать – среднее, максимальное? Правильный ответ – брать несколько перцентилей.
У каждого свои представления «о прекрасном». Мы берем у себя 99-й и 90-й перцентили. Команда сайта берет 99-й перцентиль, и он должен укладываться в 0.5 секунды. Если он не укладывается – это инцидент. Тут важно обратить внимание, что доступность должна быть абсолютно однозначной логической функцией.
Еще один, классический, подход – наблюдать Rate, Errors и Duration.
На первом графике мы видим число обращений в секунду сейчас и вчера, на втором – число ошибок, далее общее время обращений и привычный уже перцентиль.

По этим графикам вычислить доступность сложно, это скорее графики на понимание отзывчивости системы, поэтому мы дополнительно проверяем систему через встроенный Healthcheck API. А снизу мы видим достаточно интересные продуктовые метрики – сколько у нас пользователей, сколько каналов и сколько сообщений за день.

Еще один пример Managed Kafka от облачного провайдера, но мы к ней применили точно такой же подход, как к нашим сервисам. Мы считаем число живых хостов, мы проверяем метрику is alive. Если произойдет сбой, то, во-первых, ко мне прилетит алерт, а во-вторых, я увижу на дашборде, как начинает сгорать бюджет на ошибку. Так примерно выглядит подход ко всем нашим сервисам.

А вот так выглядит кусочек нашего SRE-status-page. Это страницы, где отмечены все сервисы и их статус. Каждый квадратик – это статус в определенный момент времени. Так мы видим как себя чувствуют абсолютно все инсталляции и мне не нужна машина времени, чтобы узнать, как он себя чувствовал два часа назад.

Так выглядит фрагмент для сети. Поскольку сеть – это всегда самая спорная зона ответственности, мы особенно тщательно ее обозреваем. Сверху вы видите доступность каждой зоны, которые мы взаимно проверяем «пинговалкой». Но «пинговалка» раз в 15 секунд может что-то пропустить, зато обрыв BGP-сессии обнулит session lifetime, а это мы точно увидим на нижнем графике.

Так выглядит абстракция Sloth для Jira. Мы ушли от деталей и видим целевую доступность, фактическую доступность и остаток бюджета на ошибку. Самое главное, что у Grafana есть REST API, что позволяет нам раз в сутки забирать данные по всем сервисам и откладывать их в Clickhouse, а оттуда уже бизнес смотрит сводные графики в Tableau.
Получилось ли решить поставленную задачу «чтобы облако больше не падало»? Я бы сказал, что да. Мы сразу видим проблемы, раньше команд и облачного провайдера. Мы видим их природу, что значительно уменьшает время на восстановление. Мы достоверно знаем причину, а значит можем системно улучшать каждый сервис, если он того требует. Так что за год последовательных улучшений мы снизили число инцидентов по инфраструктурной причине почти до нуля.
Если есть какие-то вопросы и уточнения, смело делитесь ими в комментариях.
Перечень вдохновляющей литературы:
Книги Google по SRE: https://sre.google/
Книга Team Topologies: https://teamtopologies.com/
Материалы по FinOps: https://finops.org/

