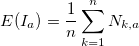Дисковые массивы Storwize компании IBM хорошо известны на рынке, а вот с удобным средством просмотра их конфигурации (тем более, не имея доступа к самому массиву), за исключением программного продукта Total Productivity Center от IBM, уже ничего и нет (perl скрипты svcmon более не поддерживаются). А у сотрудников и, или партнеров, анализирующих конфигурации данных массивов, часто возникает такая потребность. Поэтому, я предлагаю свое решение по просмотру xml файлов конфигурации данных массивов.
В этой статье я опишу, как можно прочитать xml информацию, представить её в виде таблиц, сводную информация на дэшбордах, и все это в виде web-приложения. Как следует из названия статьи – реализовано это на R, с пакетом (фреймворком) для web-приложений к R – Shiny dashboard.

В этой статье я опишу, как можно прочитать xml информацию, представить её в виде таблиц, сводную информация на дэшбордах, и все это в виде web-приложения. Как следует из названия статьи – реализовано это на R, с пакетом (фреймворком) для web-приложений к R – Shiny dashboard.
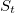 . Рассчитаем логарифмические отношения:
. Рассчитаем логарифмические отношения: 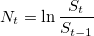
 на
на 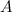 смежных периодов длиной
смежных периодов длиной 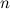 . Отметим каждый период как
. Отметим каждый период как 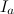 , где
, где 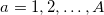 . Определим для каждого
. Определим для каждого