
Захотелось более детально разобраться и попробовать самостоятельно написать Transformer на PyTorch, а результатом поделиться здесь. Надеюсь, так же как и мне, это поможет ответить на какие-то вопросы в данной архитектуре.

Software Engineer
Захотелось более детально разобраться и попробовать самостоятельно написать Transformer на PyTorch, а результатом поделиться здесь. Надеюсь, так же как и мне, это поможет ответить на какие-то вопросы в данной архитектуре.

Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?

Привет, Хабр!
Гиперпараметры — это параметры, которые не учатся в процессе обучения модели. Они задаются заранее. От выбора гиперпараметров напрямую зависит качество и эффективность модели, а их оптимизация может улучшить результаты предсказаний.
Традиционный подход к оптимизации гиперпараметров включает в себя grid search и random search, иногда они могут быть неэффективными и времязатратными, особенно когда пространство гиперпараметров велико.
Когда я впервые столкнулся с необходимостью настроить сотни параметров в своей нейросети, задача показалась мне Сизифовым трудом. Каждый параметр мог значительно изменить результат, и пространство поиска казалось бесконечным. И немного просидев на стековерфлой я нашел либу Optuna, которая позоволила оптимизировать этот процесс.
Optuna решает проблему оптимизации гиперпараметров, предоставляя легковесный фреймворк для автоматизации поиска оптимальных гиперпараметров. Она использует алгоритмы, такие как TPE, CMA-ES, и даже поддерживает пользовательские алгоритмы.
Optuna полностью написана на Python и имеет мало зависимостей. В этой статье рассмотрим её основной функционал.

H3 отмечает, что Express.js - старый и малоразвивающийся фреймворк, являющийся не оптимальным выбором для новых проектов из-за потенциальных проблем безопасности и утечек памяти, что, к слову, касается и Koa.
В нашей статье мы сделаем акцент на фреймворках, поддерживающих запуск service workers на серверной стороне и современный стандарт Fetch API, поскольку это позволяет им работать в бессерверных и Edge-окружениях, таких как Cloudflare Workers. Это, к слову, и причина, почему Fastify не будет рассматриваться в нашей статье, несмотря на эксперимент fastify-edge, который продолжался два года (кстати, была написана интересная статья о переходе от Node к средам рабочих процессов, с которой я рекомендую ознакомиться).
Worker Runtimes воплощают первоначальное обещание NodeJS: использование одного языка и возможность обмена кодом между клиентом и сервером. Однако на практике это не осуществилось, и API Node и браузеров пошли по разным путям. Worker Runtimes вновь объединяют эти возможности. Больше информации здесь.
Hono, H3, HatTip и Elysia - это современные фреймворки HTTP-серверов, также известные как промежуточные программы веб-сервера нового поколения. Они работают везде, на любом JS-рантайме, включая бессерверные и Edge-среды выполнения. Это означает, что они могут быть использованы не только на серверах Node.js. Кроме того, все они поддерживают TypeScript.
Далее мы поговорим о каждом их них по отдельности и сравним некоторые различия.
Все они поддерживают Web Fetch API (объекты Request/Response), но здесь я покажу их API, наиболее похожие на Express, чтобы было проще ориентироваться.
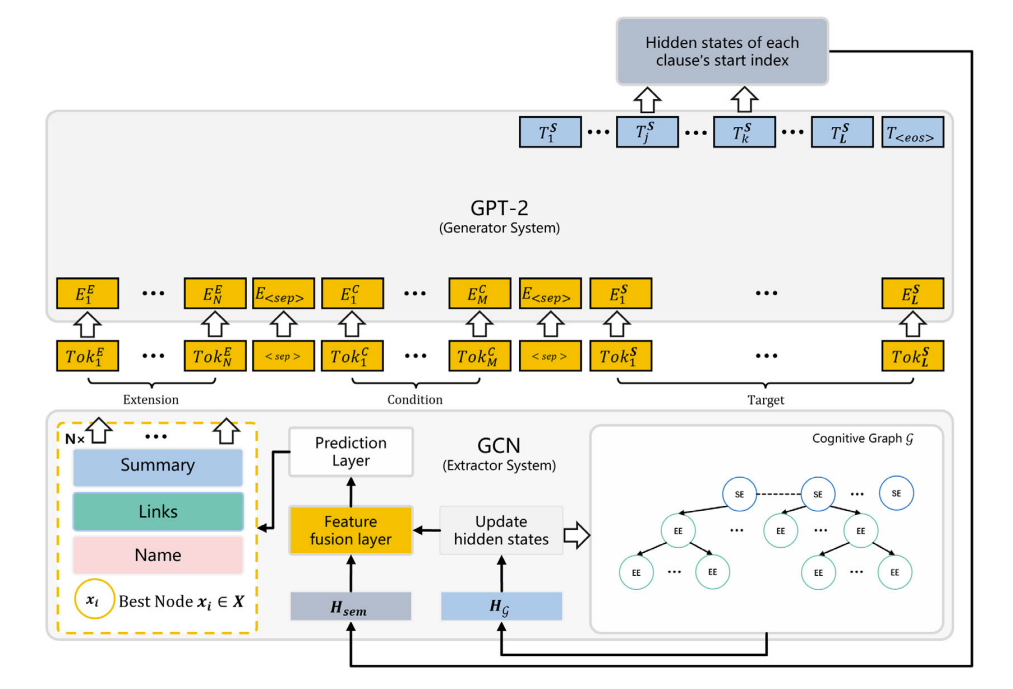
Предобученные языковые модели генерируют качественный текст, сравнимый по качеству с человеческим (иногда даже превосходящий его). Но некоторые проблемы остаются даже у лучших LLM — сеть не понимает, что говорит. Может получаться хоть и виртуозный с точки зрения грамматики и лексики, но всё-таки неверный по смыслу результат.

На сегодняшний день градиентный бустинг (gradient boosting machine) является одним из основных production-решений при работе с табличными, неоднородными данными, поскольку обладает высокой производительностью и точностью, а если быть точнее, то его модификации, речь о которых пойдёт чуть позже.
В данной статье представлена не только реализация градиентного бустинга GBM с нуля на Python, но а также довольно подробно описаны ключевые особенности его наиболее популярных модификаций.
Есть много локальных аналогов ChatGPT, но им не хватает качества, даже 65B модели не могут конкурировать хотя бы с ChatGPT-3.5. И здесь я хочу рассказать про 2 открытые модели, которые всё-таки могут составить такую конкуренцию.
Речь пойдет о OpenChat 7B и DeepSeek Coder. Обе модели за счет размера быстры, можно запускать на CPU, можно запускать локально, можно частично ускорять на GPU (перенося часть слоев на GPU, на сколько хватит видеопамяти) и для такого типа моделей есть графический удобный интерфейс.
И бонусом затронем новую модель для качественного подробного описания фото.
UPD: Добавлена информация для запуска на Windows с ускорением на AMD.
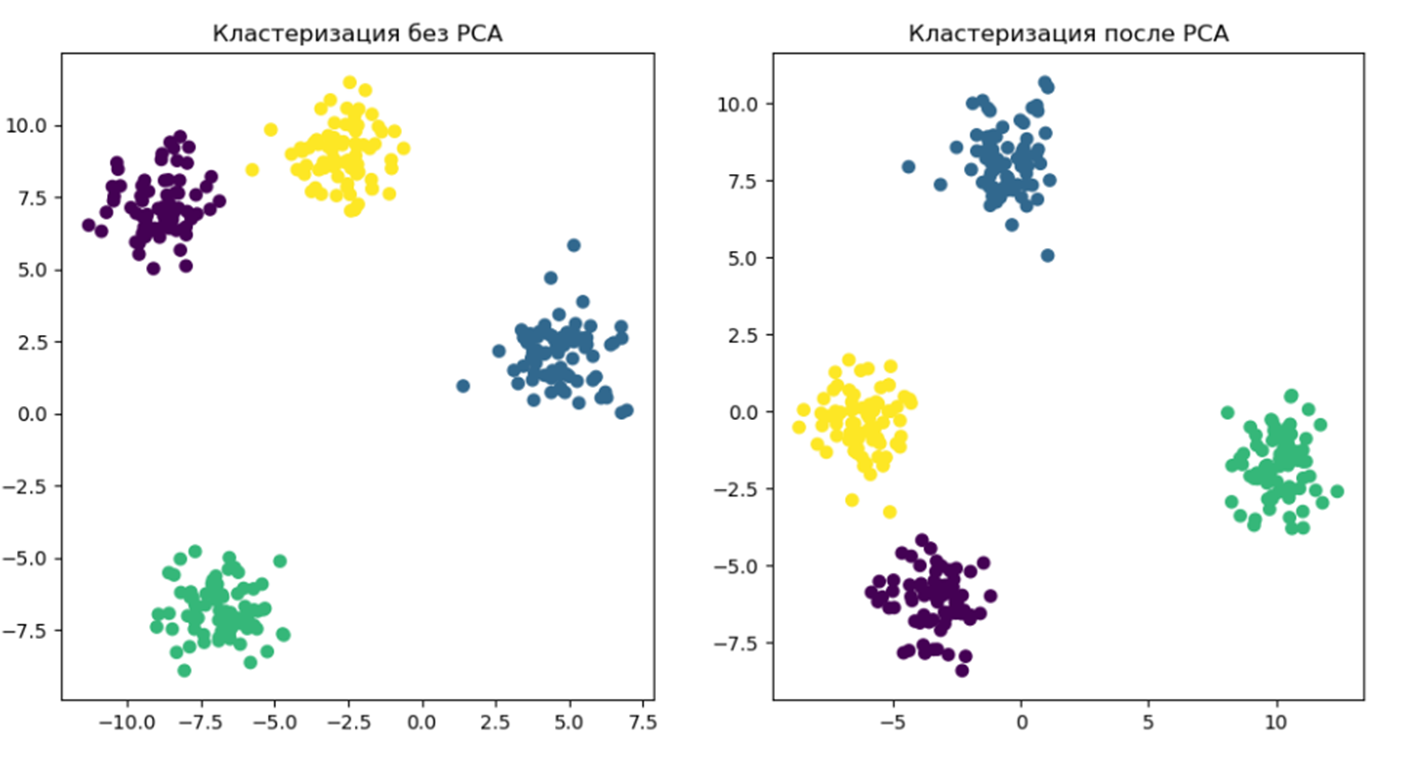
Одной из ключевых задач при работе с данными является уменьшение размерности данных, чтобы улучшить их интерпретируемость, ускорить алгоритмы обучения машин и, в конечном итоге, повысить качество решений. Сегодня мы поговорим о методе, который считается одним из наиболее мощных инструментов в арсенале данных разработчиков — методе главных компонент, или PCA (Principal Component Analysis).
Привет! Меня зовут Олег Драпеза, я работаю техлидом в Тинькофф в команде Coretech Frontend. Мой основной проект — SSR мета-фреймворк tramvai, на котором работают несколько десятков фронтовых приложений Тинькофф.
Сегодня хочется поговорить про масштабирование SSR-приложений. С SSR есть две проблемы: React и Node.js. Они же — сильные стороны подхода, потому что предоставляют отличный DX, общий код и хорошие возможности для поддержки frontend-разработчиками. Разберемся, с какими сложностями мы можем столкнуться при использовании React и Node.js и как с ними быть.

Статья для тех, кто хочет познакомиться с устройством технологии WebSocket или языком программирования Go.
Или узнать с какой простотой Go стал одним из самых популярных языков программирования для написания сетевых приложений.
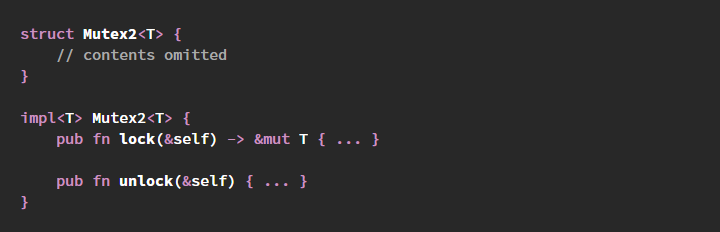
unlock, потому что им кажется, что это более явное действие.Mutex<()> и разные хитрости, чтобы его имитировать.Mutex неразрывно связаны друг с другом, а также с гарантиями безопасности Rust в целом — изменение одного из них или обоих откроет возможности для возникновения незаметных багов и повреждений из-за гонок данных.lock и unlock было бы опрометчивым в Rust, потому что это позволяет безопасному коду легко вносить ошибки, нарушающие безопасность памяти и вызывающие гонки данных.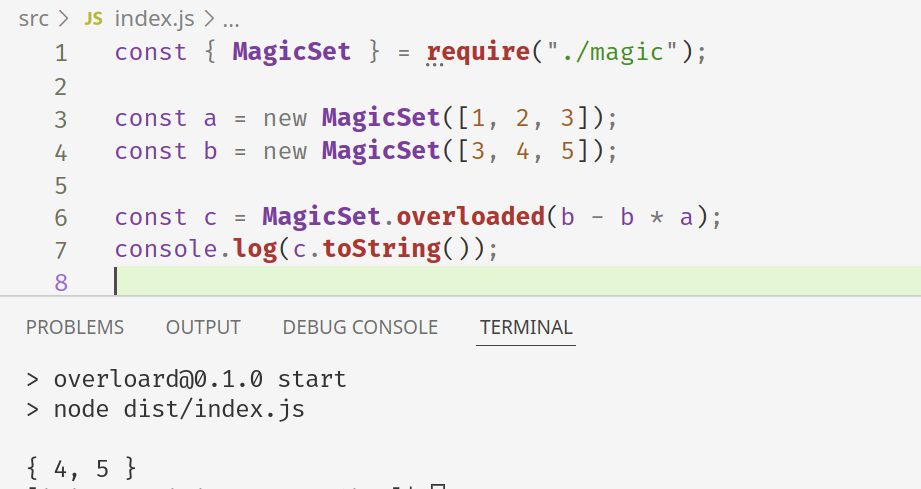
Одна из активно реквестируемых фич в JavaScript и TypeScript — перегрузка операторов. Без инфиксной записи, к примеру, получаются очень громоздкими вычисления с векторами или множествами. Тем не менее, используя сильное колдунство некоторые знания о том, как сейчас работают операторы в JavaScript, мы можем реализовать все самостоятельно.


 Еще я создала канал в Telegram: GameDEVils, буду делиться там клевыми материалами (про геймдизайн, разработку и историю игр).
Еще я создала канал в Telegram: GameDEVils, буду делиться там клевыми материалами (про геймдизайн, разработку и историю игр). Еще я веду канал в Telegram: GameDEVils, делюсь там клевыми материалами (про геймдизайн, разработку и историю игр).
Еще я веду канал в Telegram: GameDEVils, делюсь там клевыми материалами (про геймдизайн, разработку и историю игр).


Привет! Я хочу рассказать вам о рекомендательных алгоритмах. Мы в Prequel создаем фильтры и эффекты для редактирования фото и видео. Создаем давно, и постепенно этих эффектов стало очень много. А с ними и пользовательского контента. Мы захотели помочь с выбором из этого многообразия, для чего нам и понадобилась система рекомендаций. Если масштабы вашей системы такие, что пользователям сложно в ней ориентироваться, возможно, что рекомендации могут помочь и вам.
Задуманный систем оказался слишком объемным для одной статьи, поэтому мы разбили его на две части. Перед вами первая, она посвящена постановке задачи и базовым методам решения. В этой части мы разберем коллаборативные модели от матричного разложения (на примере ALS) до neural collaborative filtering. Кроме того, будет небольшой обзор метрик и техник борьбы с проблемой холодного старта.
{kind=link}