
Много слов сказано о том, как правильно писать юнит-тесты, и вообще о пользе TDD. Потом ещё и какое-то BDD замаячило на горизонте. Приходится разбираться, что из них лучше и между ними какая разница. Может, это и есть причина, почему большинство разработчиков решили не заморачиваться и до сих пор не используют ни того, ни другого?
Коротко: BDD — это дальнейшее развитие идей TDD, стало быть, его и надо использовать. А разницу между TDD и BDD я попробую объяснить на простом примере.
Рассмотрим 3 ревизии одного юнит-теста, который я нашёл в одном реальном проекте.
Первая версия этого юнит-теста была такой:
Коротко: BDD — это дальнейшее развитие идей TDD, стало быть, его и надо использовать. А разницу между TDD и BDD я попробую объяснить на простом примере.
Рассмотрим 3 ревизии одного юнит-теста, который я нашёл в одном реальном проекте.
Попытка номер №1
Первая версия этого юнит-теста была такой:
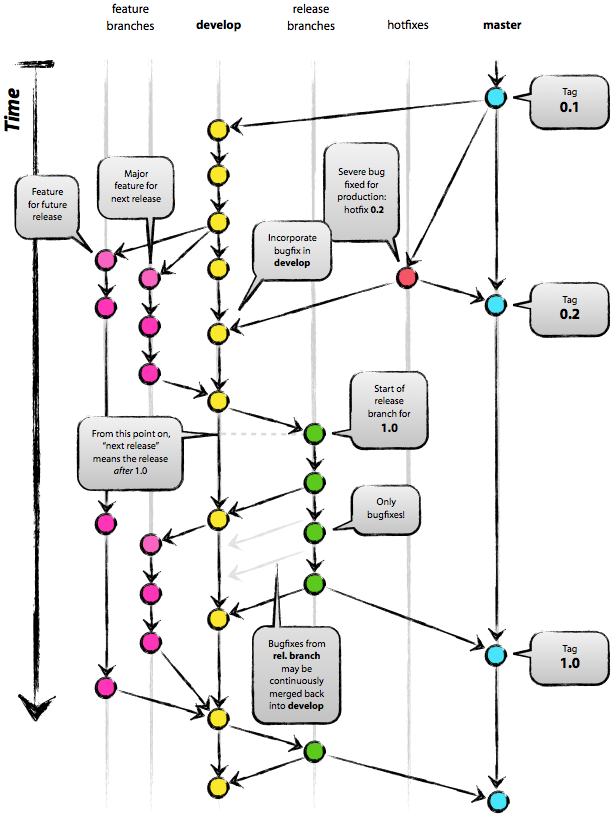
 В этой заметке расскажу о своем опыте юнит-тестирования JS-кода, опыте использования среды выполнения тестов js-test-driver, ее возможности code coverage и скручивании ежа с ужом, а именно данных о code coverage от js-test-driver и генератора отчетов о покрытии PHP_CodeCоverage. Расскажу и покажу как получить
В этой заметке расскажу о своем опыте юнит-тестирования JS-кода, опыте использования среды выполнения тестов js-test-driver, ее возможности code coverage и скручивании ежа с ужом, а именно данных о code coverage от js-test-driver и генератора отчетов о покрытии PHP_CodeCоverage. Расскажу и покажу как получить 
 Предлагаю вашему вниманию перевод вчерашнего поста
Предлагаю вашему вниманию перевод вчерашнего поста  Довольно часто во многих статьях я вижу, как люди захватывают контекст this для использования в анонимной функции и удивляюсь — то, что уже стало стандартом — просто ужасная практика, которая противоречит всем канонам программирования. Вам знакома такая запись?
Довольно часто во многих статьях я вижу, как люди захватывают контекст this для использования в анонимной функции и удивляюсь — то, что уже стало стандартом — просто ужасная практика, которая противоречит всем канонам программирования. Вам знакома такая запись?
 Доброго времени суток, хабравчане! В этой статье я подробно расскажу вам о трансформации и вращении в javascripte. Матрица трансформаций, на первый взгляд, штука непонятная и многие ею пользуются даже не осознавая, что она делает на самом деле, используя готовые значения из интернета. На
Доброго времени суток, хабравчане! В этой статье я подробно расскажу вам о трансформации и вращении в javascripte. Матрица трансформаций, на первый взгляд, штука непонятная и многие ею пользуются даже не осознавая, что она делает на самом деле, используя готовые значения из интернета. На