OpenVAS (Open Vulnerability Assessment System, Открытая Система Оценки Уязвимости, первоначальное название GNessUs) фреймворк состоящий из нескольких сервисов и утилит, позволяющий производить сканирование узлов сети на наличие уязвимостей и управление уязвимостями.
OPSEC LEA (Log Export API) – интерфейс, позволяющий получать логи с сервера управления (Checkpoint SmartCenter).
В основе OPSEC LEA лежит клиент-серверная архитектура. В качестве сервера выступает Checkpoint SmartCenter, который слушает входящие соединения на порт 18184 ТСР (по-умолчанию). Клиент OPSEC LEA подключается к Серверу на вышеуказанный порт и получает логи.
Fw1-loggrabber – программное обеспечение, поддерживающее OPSEC LEA, и предназначенное для получения логов с серверов управления (Checkpoint SmartCenter – далее SC). Fw1-loggrabber может выводить полученные логи на экран, перенаправлять в файл или в syslog.
Существуют версии данного ПО как под Linux, так и под Windows (под windows не поддерживается вывод в syslog).
Дано:
Сервер управления Checkpoint. Версия ПО Checkpoint – R77.30 (sc.local);
Сервер с CentOS 6.6 (loggraber.local);
Syslog сервер (syslog.local).
Задача:
получить логи c SC и передать их по протоколу syslog на внешний syslog сервер.
Всем доброго времени суток, сегодня не будет VulnHub'a. Сегодня рассмотрим его альтернативу hack.me. На котором содержится не мало интересных площадок для взлома, на различные темы. В этой статье рассмотрим BeachResort. Как пишет автор, это не типичный CTF,
Эти приемы были описаны во внутреннем проекте компании Google «Testing on the Toilet» (Тестируем в туалете — распространение листовок в туалетах, что бы напоминать разработчикам о тестах).
В данной статье они были пересмотрены и дополнены.
Об авторе. Арчи Рассел (Archie Russell) — инженер бэкенда во Flickr
Одна из самых затратных статей в работе сервиса вроде Flickr — это хранение. За последние годы мы описывали различные техники для снижения стоимости: использование COS, динамическое изменение размера на GPU и перцептивное сжатие. Эти проекты были очень успешны, но мы продолжали терять много денег на хранении данных.
В начале 2016 года мы поставили перед собой задачу выйти на новый уровень — продержаться целый год вообще не закупая новые носители информации. Используя различные техники, нам это удалось.
История затрат
Небольшие арифметические расчёты на салфетке показывают, что затраты на хранение представляют собой предмет реального беспокойства. В день с высокой посещаемостью пользователи Flickr загружают до 25 млн фотографий. Каждая из них требует в среднем 3,25 МБ, что в сумме составляет 80 ТБ. Наивно размещая их на облачном хостинге вроде S3 фотографии одного дня потянут на $30 тыс. в год и продолжат генерировать затраты каждый последующий год.
В данной статье я постарался раскрыть назначение VMware Virtual SAN, принципы её работы, требования, возможности и ограничения данной системы, основные рекомендации по её проектированию.
Концепция Virtual SAN
VMware Virtual SAN (далее vSAN) представляет собой распределенную программную СХД (SDS) для организации гипер-конвергентной инфраструктуры (HCI) на базе vSphere. vSAN встроен в гипервизор ESXi и не требует развертывание дополнительных сервисов и служебных ВМ. vSAN позволяет объединить локальные носители хостов в единый пул хранения, обеспечивающий заданный уровень отказоустойчивости и предоставляющий свое пространство для всех хостов и ВМ кластера. Таким образом, мы получаем централизованное хранилище, необходимое для раскрытия всех возможностей виртуализации (технологии vSphere), без необходимости внедрения и сопровождения выделенной (традиционной) СХД.
Как новички изучают css-свойства? Они читают про все свойства, которые только есть, что-то запоминают, в основном только width, height и background, а потом постоянно рыщут по своим конспектам и гуглу, пытаются вспомнить какое свойство за что отвечает, как оно пишется и какие у него есть значения.
И тут мне пришла в голову идея. А что если сделать такую штуку, которая наглядно показывает как пишутся и работают все css-свойства? Причем, все это на одной странице.
На первый взгляд может показаться, что компания Google поступила безответственно и нарушила IT-этикет, не дав Microsoft времени на исправление бага. Специалисты Google Threat Analysis Group опубликовали факт наличия опасной уязвимости в Windows всего через 10 дней после того, как сообщили о ней в Microsoft. У редмондской компании просто физически не было времени, чтобы проверить баг, протестировать его на всех конфигурациях, подготовить патч, протестировать его на всех конфигурациях — и выкатить обновление в Windows Update. Уязвимость до сих пор не закрыта.
Мы в Одноклассниках занимаемся поиском узких мест в инфраструктуре, состоящей более чем из 10 тысяч серверов. Когда мы слегка задолбались мониторить 5000 серверов вручную, нам понадобилось автоматизированное решение.
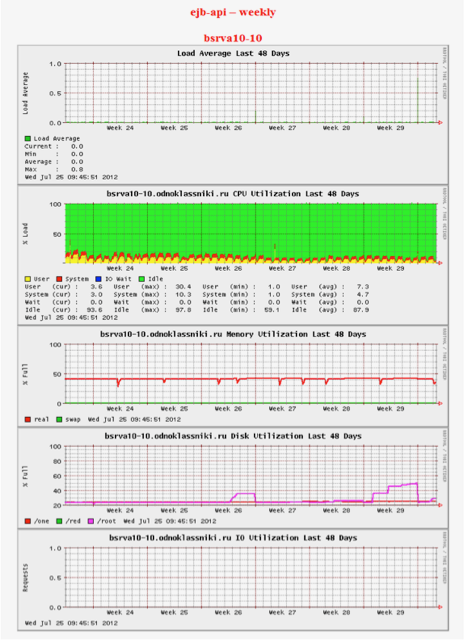
Точнее, не так. Когда в седой древности появился примерно 20-й сервер, стали использовать Big Brother — простейший мониторинг, который просто собирает статистику и показывает её в виде мелких картинок. Всё очень, очень просто. Ни приблизить, ни как-то ввести диапазоны допустимых изменений нельзя. Только смотреть картинки. Вот такие:
Два инженера тратили по одному рабочему дню в неделю, просто отсматривая их и ставя тикеты там, где график показался «не таким». Понимаю, звучит реально странно, но началось это с нескольких машин, и потом как-то неожиданно доросло до 5000 инстансов.
Поэтому мы сделали новую систему мониторинга — и сейчас на работу с 10 тысячами серверов тратим по 1-2 часа в неделю на обработку алертов. Расскажу, как это устроено.
Wi-Fi в офисах Mail.Ru Group за последние десять лет пережил несколько смен оборудования, подходов к построению сети, схем авторизации, администраторов и ответственных за его работу. Начиналась беспроводная сеть, наверное, как и во всех компаниях — с нескольких домашних роутеров, которые вещали какой-то SSID со статичным паролем. Долгое время этого было достаточно, но количество пользователей, площади и количество точек доступа стало расти, домашние D-Linkʼи постепенно заменили на Zyxel NWA-3160. Это уже было относительно продвинутым решением: одна из точек могла выступать в качестве контроллера для остальных и давала единый интерфейс для менеджмента всей сети. Какой-то более глубокой логики и автоматизации софт NWA-3160 не давал, только возможность настройки подключенных к контроллеру точек, пользовательский трафик обрабатывался каждым устройством независимо. Следующей сменой оборудования стал переход на контроллер Cisco AIR-WLC2006-K9 + несколько точек доступа Aironet 1030. Уже совсем взрослое решение, с безмозглыми точками доступа и обработкой всего трафика контроллером беспроводной сети. После еще была миграция на пару AIR-WLC4402-K9, сеть уже выросла до сотни точек Cisco Aironet 1242AG, 1130AG, 1140AG.
Мой доклад предназначен для тех людей, которые знают слово «репликация», даже знают, что в MySQL она есть, и, возможно, один раз ее настроили, 15 минут потратили и забыли. Больше про нее они не знают ничего.
Мы немного пройдемся по теории, попытаемся объяснить, как это все работает внутри, а после этого вы с утроенными силами сможете сами нырнуть в документацию.
Что такое репликация, в принципе? Это копирование изменений. У нас есть одна копия БД, мы хотим с какой-то целью еще одну копию.
Репликация бывает разных видов. Разные оси сравнения:
степень синхронизации изменений (sync, async, semisync);
количество серверов записи (M/S, M/M);
формат изменений (statement-based (SBR), row-based (RBR), mixed);
теоретически, модель передачи изменений (push, pull).
Windows Server 2012 R2 вышел 18 октября 2013 года. С тех пор на эту серверную операционную систему Microsoft выпущено несколько сотен обновлений исправляющих уязвимости и дефекты продукта, а так же улучшающие функционал.
Огромное количество обновлений — источник головной боли. Наиболее актуальный дистрибутив сервера, так называемый «Update2», в который интегрированы обновления по ноябрь 2014 года, безнадежно устарел. Установив с него операционную систему, вы получите вдогонку еще 200+ обновлений, которые будут устанавливаться 2-4 часа.
В этой короткой инструкции мы освежим ноябрьский дистрибутив, интегрировав в него все кумулятивные пакеты обновлений и обновления безопасности.
Помимо дистрибутива мы освежим и память администратора, вспомнив как обновляется носитель для установки, зачем выполняется каждый шаг, и какие нас может ожидать подвохи на разных этапах.
Делать будем по максимуму просто, используя штатные инструменты.
На днях мне нужно было реализовать расшифровку базы данных KeePass. Меня поразило то, что нет ни одного документа и ни одной статьи с исчерпывающей информацией об алгоритме расшифровки файлов .kdb и .kdbx с учетом всех нюансов. Это и побудило меня написать данную статью.
На данный момент существует 2 версии KeePass:
KeePass 1.x (генерирует файлы .kdb);
KeePass 2.x (генерирует файлы .kdbx).
Структура файла с базой данных KeePass (.kdb, .kdbx) состоит из 3 частей:
Подпись (не зашифрована);
Заголовок (не зашифрован);
Данные (зашифрованы).
Далее я подробно расскажу о том, как дешифровать базу данных KeePass 1.x и KeePass 2.x.
В сети любого Интернет-провайдера можно встретить такой обязательный элемент, как кэширующий DNS сервис. А поскольку работа сети Интернет без службы DNS невозможно, серверов таких будет минимум два, с обязательным резервированием и балансировкой. В заметке я постараюсь описать один из вариантов балансировки нагрузки между несколькими кэширующими серверами на основе Cisco IP SLA.
Всвязи с увеличением количества серверов возникла необходимость в их мониторинге с возможностью оповещения при возникновении проблем. Выбор пал на Nagios, так как пару лет назад, работая в компании телеком-оператора работал с ним.
Одним из условий была возможность оповещения посредством SMS сообщений.
Итак, что имеем и как все это заставить работать вместе:
— Linux (Debian 5) сервер с установленным Nagios (процесс первоначальной установки и настройки самого Nagios не буду описывать в данной статье)
— Мобильный телефон (в данном случае Nokia 3110), подключаемый посредством USB кабеля
— Желание все это дело заставить работать вместе :)
Несколькими постами раньше уже были темы об использовании SMS уведомлений в Nagios. Сегодня я расскажу ещё об одном способе уведомлений. Нижеописанный способ несколько надёжнее описанных ранее, но и требует некоторых денежных вложений. Он полезен в том случае, когда какие-то из уведомлений являются критически важными (как, например, выход кондиционера из строя или увеличение влажности).
Способ заключается использовании мобильного телефона с корпоративным тарифом (дабы деньги на телефоне не кончились неожиданно).
Физически подключается к серверу по bluetooth, com или usb. На уровне ПО мы будем использовать два скрипта: один из них умеет отправлять sms, второй проверяет статус мобильной сети. Если мобильная сеть недоступна, то nagios отправляет сообщение на email.
Оба скрипта написаны на python и используют библиотеку gammu для подключения к телефону.
Специалисты по безопасности из компании Foxglove Security сумели объединить несколько уязвимостей операционных систем от Microsoft, самой старой из которых уже 15 лет. Систему из трёх уязвимостей, собранных в одну, назвали «Hot Potato». Эта система позволяет за разумное время поднять привилегии процесса с самого нижнего до системного, и получить тем самым контроль над ОС.
Среди используемых уязвимостей — NTLM relay, атака на протокол аутентификации NT LAN Manager (конкретно HTTP->SMB relay). Другая уязвимость — «NBNS spoofing», позволяющая атакующему настроить поддельные прокси в Web Proxy Auto-Discovery Protocol. Все уязвимости работают в Windows 7, 8, 10, Server 2008 и Server 2012.
Как утилита работает в Windows 7
Используемые уязвимости не новы. Более того, все они хорошо известны внутри компании Microsoft. Проблема лишь в том, что исправление этих уязвимостей невозможно без нарушения обратной совместимости разных версий операционных систем. Поэтому разного рода хакеры эксплуатируют их по сию пору.
Исследователи взяли за основу своей системы метод 2014 года от Google Project Zero, а затем расширили и дополнили его. Новинкой является метод комбинирования известных уязвимостей между собой.
Я максимально постараюсь писать без «воды». Минимум лишней отвлекающей информации и разглагольствований. Максимум полезной информации и рабочего кода. Я не буду поднимать вопрос зачем кому-то собственный торрент-поисковик на базе RuTracker. И я не считаю себя гуру программирования. Мы просто сделаем этот сайт вместе. Будем использовать Apache+PHP, MySQL и Sphinx. Сразу предупрежу, что на минимальном виртуальном хостинге сайт будет работать совсем не быстро.
Продолжаем начатый в прошлом посте разговор о безопасности UEFI, об угрозах и имеющихся защитах от них.
В этот раз речь пойдет об SMM, о том, как он устроен и работает, и почему является желанной целью для атаки.
Пропустившим нулевую и первую части сего опуса — рекомендую прочесть сначала их, остальных покорно прошу под кат.


 Об авторе. Арчи Рассел (Archie Russell) — инженер бэкенда во Flickr
Об авторе. Арчи Рассел (Archie Russell) — инженер бэкенда во Flickr



 Windows Server 2012 R2 вышел 18 октября 2013 года. С тех пор на эту серверную операционную систему Microsoft выпущено несколько сотен обновлений исправляющих уязвимости и дефекты продукта, а так же улучшающие функционал.
Windows Server 2012 R2 вышел 18 октября 2013 года. С тех пор на эту серверную операционную систему Microsoft выпущено несколько сотен обновлений исправляющих уязвимости и дефекты продукта, а так же улучшающие функционал.

 Специалисты по безопасности из компании Foxglove Security
Специалисты по безопасности из компании Foxglove Security 
 Продолжаем начатый в прошлом посте разговор о безопасности UEFI, об угрозах и имеющихся защитах от них.
Продолжаем начатый в прошлом посте разговор о безопасности UEFI, об угрозах и имеющихся защитах от них.