Полный курс на русском языке можно найти по этой ссылке.
Оригинальный курс на английском доступен по этой ссылке. Выход новых лекций запланирован каждые 2-3 дня.
Недавно, постигая азы Машинного Обучения и изучая классификацию, я наткнулся на precision и recall. Диаграммки, которые часто вставляют, объясняя эти концепции, мне не помогли понять отличия между ними. Но чудо, я придумал объяснение, которое понятно мне, и я надеюсь, что оно поможет кому-нибудь из вас на пути изучения ML (возможно это объяснение кто-то придумал до меня) .
Перед тем как начинать, давайте представим горку песка, но в этом песке ещё есть песчаные камни, они ведь тоже являются песком, так? Также в этом песке есть некоторый мусор. Наша задача - просеять песок...
Всем привет, меня зовут Маруся, я аналитик данных и на досуге веду телеграм-канал про аналитику.
Так как я сама изучала аналитику данных по бесплатным курсам, параллельно стажируясь, а потом уже и полноценно работая в компаниях, у меня накопилось много классных бесплатных курсов, которыми с вами тут и поделюсь.
Сейчас предлагают много платных программ, но если у вас есть интерес и вы можете себя организовать на учебу самостоятельно - то обучение по бесплатным курсам вам подойдет. Тем более что это обучение от лучших компаний и университетов мира - Harvard, IBM, Google, Stanford и других.
Открытые данные как явление существует давно, а вот вопросов по ним возникает большое множество и, для того чтобы снять хотя бы часть из них, мы организовали школу открытых данных которая проходит в форме лекций, семинаров и мастер-классов.
Это бесплатный просветительский проект в котором мы рассказываем об открытых данных всё что знаем и что может пригодиться другим.
При том что наша цель — это выйти на формат вебинаров, в первом шаге мы стали проводить мероприятия с записью их на видео и с открытой публикацией онлайн.
Лекции ведут российские и зарубежные преподаватели и практики и все они, по возможности, настолько приближены к практике насколько это возможно.
Сейчас у нас накопилось 7 таких занятий и нам очень важно получить обратную связь по тому что было рассказано и что хотелось бы услышать.
При изучении Data Science, я решил составить для себя конспект по основным приемам, используемым в анализе данных. В нем отражены названия методов, кратко описана суть и приведен код на Python для быстрого применения. Готовил конспект для себя, но подумал, что кому-то это также может быть полезно, например, перед собеседованием, в соревновании или при запуске нового проекта. Рассчитано на аудиторию, которая в целом знакома со всеми этими методами, но имеет необходимость освежить их в памяти. Статья под катом.
Введение: Привет, Хабр! Сегодня мы исследуем мир менее известных, но чрезвычайно полезных библиотек Python, которые могут значительно обогатить ваш аналитический инструментарий.
? Подписывайтесь на мой телеграмм-канал DataTechCommunity для получения ежедневных обновлений о Python и аналитике данных!
Содержание:
Рассматриваем 5 малоизвестных, но полезных библиотек для аналитиков данных. Они помогут вам в машинном обучении, обработке больших данных и визуализации.
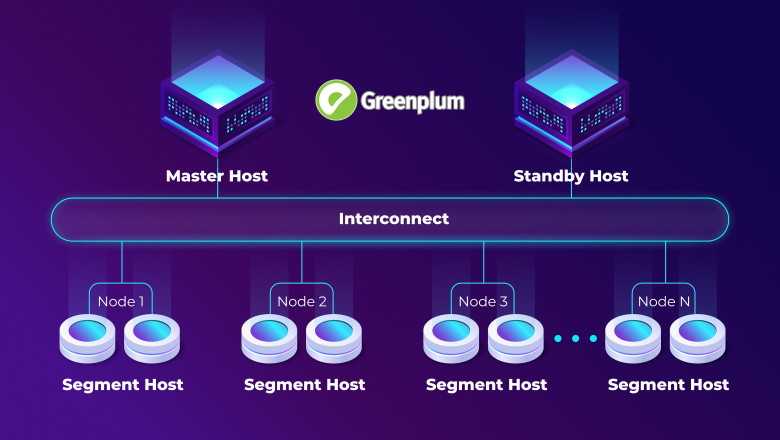
В мире современной аналитики данных, где информация – это ключевой актив организации, база данных должна быть не только масштабируемой, но и высокоэффективной. В этом контексте Greenplum, мощная и распределенная система управления базами данных, стоит в центре внимания. Greenplum предоставляет подходящие возможности для хранения и анализа огромных объемов данных, но, чтобы добиться максимальной производительности и оптимальной управляемости, необходимо грамотно оптимизировать хранение данных.
Данная статья в первую очередь для тех, кто только начинает знакомство с оптимизацией в Greenplum и хочет разобраться на что стоит обратить внимание в первую очередь. Будут рассмотрены три ключевых аспекта: компрессию данных, распределение и партиционирование. Узнаем – как правильно применять эти стратегии, чтобы улучшить производительность запросов, снизить потребление ресурсов и повысить эффективность работы базы данных.