Идеи и встречи о том, какие ещё процессы можно автоматизировать, возникают в бизнесе разного масштаба ежедневно. Но помимо того, что много времени может уходить на создание модели, нужно потратить его на её оценку и проверку того, что получаемый результат не является случайным. После внедрения любую модель необходимо поставить на мониторинг и периодически проверять.
И это всё этапы, которые нужно пройти в любой компании, не зависимо от её размера. Если мы говорим о масштабе и legacy Сбербанка, количество тонких настроек возрастает в разы. К концу 2019 года в Сбере использовалось уже более 2000 моделей. Недостаточно просто разработать модель, необходимо интегрироваться с промышленными системами, разработать витрины данных для построения моделей, обеспечить контроль её работы на кластере.
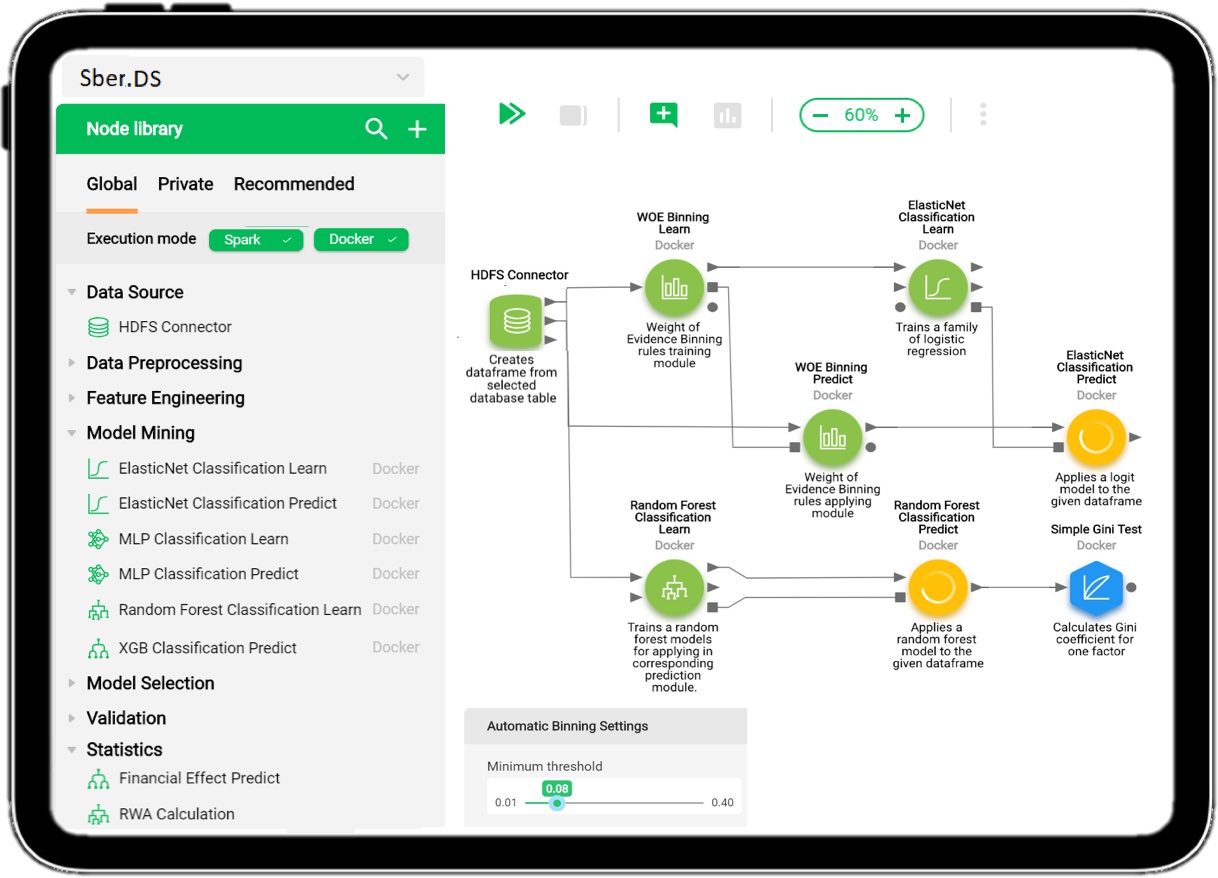
Наша команда разрабатывает платформу Sber.DS. Она позволяет решать задачи машинного обучения, ускоряет процесс проверки гипотез, в принципе упрощает процесс разработки и валидации моделей, а также контролирует результат работы модели в ПРОМ.
Чтобы не обмануть ваших ожиданий, хочу заранее сказать, что этот пост — вводный, и под катом для начала рассказано о том, что в принципе под капотом платформы Sber.DS. Историю о жизненном цикле модели от создания до внедрения мы расскажем отдельно.





{kind=link}