Для большинства людей, знакомых с криптовалютами, майнинг остается все еще слишком сложным и дорогим видом деятельности. И даже возможность пассивно зарабатывать после первоначального вложения в простенькую ферму останавливает большинство потенциальных майнеров. Сомнения, стоит ли заниматься майнингом, имеют вполне реальную почву: тут и риски сжечь оборудование до выхода на самоокупаемость, и общая нестабильность рынка. Но наибольшую проблему составляют следующие два фактора: высокий порог вхождения в сферу (в плане технической грамотности) и высокая конкуренция в сфере.
Казалось бы, майнинговые пулы — это решение, которое снимает вышеозначенные проблемы, снижает порог входа и повышает заработок на майнинге. Но так происходит только на первый взгляд, потому что если копнуть чуть глубже, чем на «пол лопаты», то вскрывается, что пулы — это просто разрозненные группы майнеров, в которых одеяло каждый тянет сам на себя. Да, доходность от такого майнинга выше, чем при попытках добывать криптовалюты полностью автономно и эта модель подходит для небольших игроков, но она далеко не идеальна.

Собственно, поэтому и возник Whalesburg
Фактически, сегодня весь сегмент занимается бесконечным самообманом, когда позиционирует пул как коллективный инструмент майнинга. Общности и взаимодействия лишь чуть больше, чем при добыче напрямую. Единственное, чем помогает пул — это увеличивает доходность за счет объединения мощностей с последующей «дележкой» добытого. При этом майнер сам решает, куда направить мощь своей фермы и что «копать». Подобный индивидуализм очень хорошо вписывается в парадигму современной рыночной культуры, но при этом, на длинной дистанции, снижает общую доходность майнинга. Выигрывают лишь сами владельцы пула и по-настоящему промышленные майнеры, когда как рядовому «копателю» остается лишь метаться между блокчейнами и до красных глаз мониторить курсы криптовалют.
Вместе порознь
Казалось бы, майнинговые пулы — это решение, которое снимает вышеозначенные проблемы, снижает порог входа и повышает заработок на майнинге. Но так происходит только на первый взгляд, потому что если копнуть чуть глубже, чем на «пол лопаты», то вскрывается, что пулы — это просто разрозненные группы майнеров, в которых одеяло каждый тянет сам на себя. Да, доходность от такого майнинга выше, чем при попытках добывать криптовалюты полностью автономно и эта модель подходит для небольших игроков, но она далеко не идеальна.
Собственно, поэтому и возник Whalesburg
Фактически, сегодня весь сегмент занимается бесконечным самообманом, когда позиционирует пул как коллективный инструмент майнинга. Общности и взаимодействия лишь чуть больше, чем при добыче напрямую. Единственное, чем помогает пул — это увеличивает доходность за счет объединения мощностей с последующей «дележкой» добытого. При этом майнер сам решает, куда направить мощь своей фермы и что «копать». Подобный индивидуализм очень хорошо вписывается в парадигму современной рыночной культуры, но при этом, на длинной дистанции, снижает общую доходность майнинга. Выигрывают лишь сами владельцы пула и по-настоящему промышленные майнеры, когда как рядовому «копателю» остается лишь метаться между блокчейнами и до красных глаз мониторить курсы криптовалют.
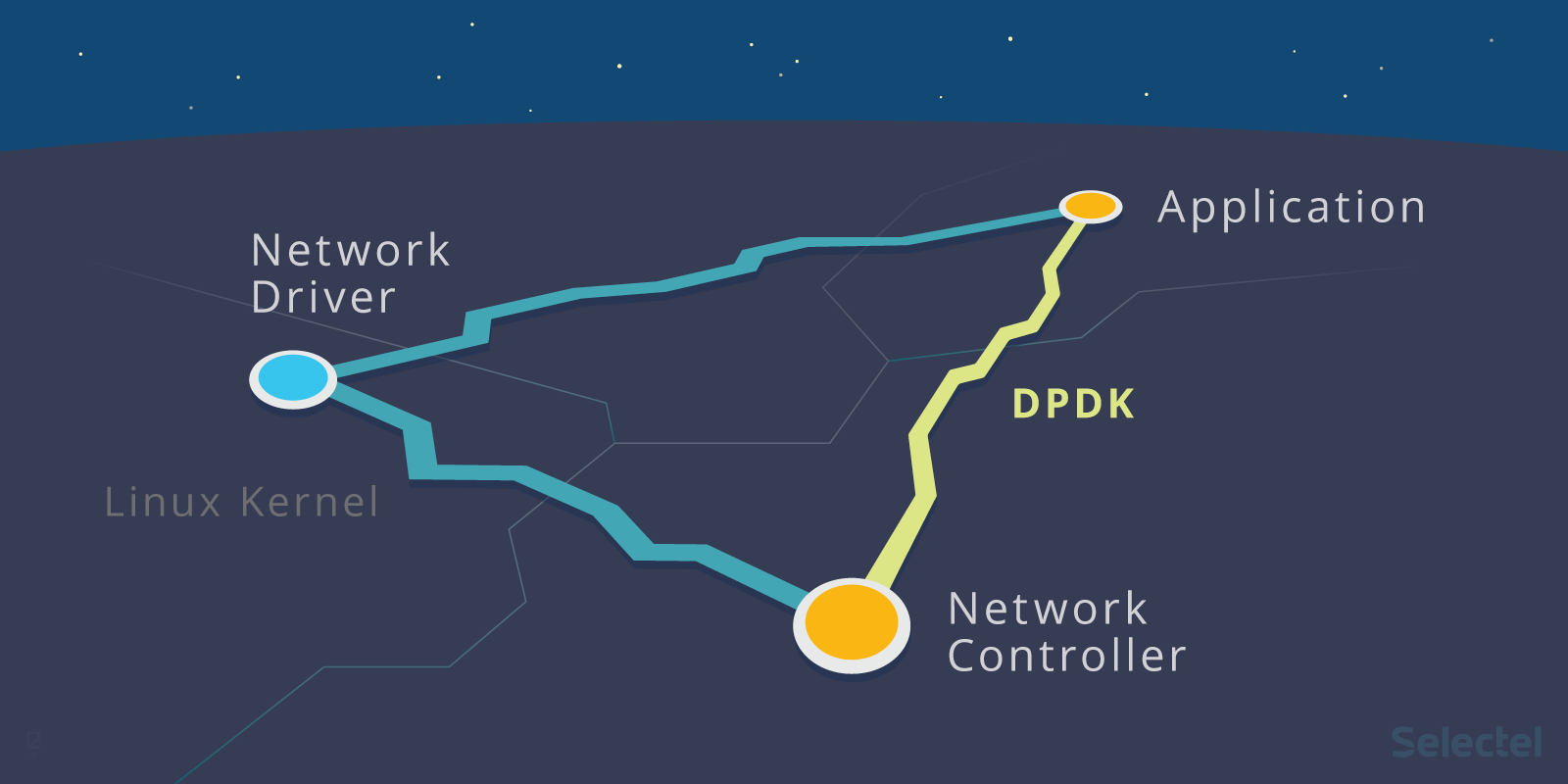
 Для быстрой обработки пакетов требуется обнаруживать битовые шаблоны и быстро (со скоростью работы канала) принимать решения о нужных действиях на основе наличных битовых шаблонов. Эти битовые шаблоны могут принадлежать одному из нескольких заголовков, присутствующих в пакете, которые, в свою очередь, могут находиться на одном из нескольких уровней, например Ethernet, VLAN, IP, MPLS или TCP/UDP. Действия, определяемые по битовым шаблонам, могут различаться — от простого перенаправления пакетов в другой порт до сложных операций перезаписи, для которых требуется сопоставление заголовка пакета из одного набора протоколов с другими. К этому следует добавить функции управления трафика и политик трафика, брандмауэры, виртуальные частные сети и т. п., вследствие чего сложность операций, которые необходимо выполнять с каждым пакетом, многократно возрастает.
Для быстрой обработки пакетов требуется обнаруживать битовые шаблоны и быстро (со скоростью работы канала) принимать решения о нужных действиях на основе наличных битовых шаблонов. Эти битовые шаблоны могут принадлежать одному из нескольких заголовков, присутствующих в пакете, которые, в свою очередь, могут находиться на одном из нескольких уровней, например Ethernet, VLAN, IP, MPLS или TCP/UDP. Действия, определяемые по битовым шаблонам, могут различаться — от простого перенаправления пакетов в другой порт до сложных операций перезаписи, для которых требуется сопоставление заголовка пакета из одного набора протоколов с другими. К этому следует добавить функции управления трафика и политик трафика, брандмауэры, виртуальные частные сети и т. п., вследствие чего сложность операций, которые необходимо выполнять с каждым пакетом, многократно возрастает.