
Давайте каждый попробует ответить на вопрос: как установить apache на сервер? Этот вопрос порождает ещё десяток: какая ОС стоит на сервере, какую версию ставить, где лежат конфиги по-умолчанию и т.д. и т.п.
А теперь давайте попробуем ответить на вопрос: как установить apache на 1000 серверов? Тут, при стандартном подходе, вопросов возникнет ровно в 1000 раз больше. Часть из вас наверняка подумали, что можно написать скрипт на shell/perl/python/ruby, который будет обходить все сервера и устанавливать apache, другая часть подумала о distributed shell'ах (
PDsh,
dsh, etc), кто-то же подумал монтировать rootfs серверов по NFS.
В ряде случаев выше предложенные варианты решений удовлетворительны, но на практике я нигде не видел полностью гомогенных систем (зачастую, внутри компании можно встретить не только разные версии ОС, но и различные дистрибутивы. Также в
России/СНГ очень распространена каша из FreeBSD/Linux в ядре проектов), так что вряд ли за адекватное время будет возможно написать скрипт, который установит и настроит apache на зоопарке в 1000 машин под CentOS, Debian, Ubuntu, FreeBSD всевозможных версий.
По моим наблюдениям, очень мало IT подразделений, даже очень крупных компаниий, используют в своей работе
SCM (Software Configuration Management). В этом посте я постараюсь описать все преимущества использования Chef в IT инфраструктуре на простых примерах и больших масштабах.
Если же, после столь короткого вступления, вы не прониклись идеей Chef, да и времени читать длинный технический пост у вас нет, то рекомендую вам пролистать до конца и посмотреть как используем Chef мы, Engine Yard, 37signals и подумать, можете ли вы переложить на него часть своей работы.

 Привет. Сегодня понедельник, поэтому я решил, что стоит начать свой рабочий день с разогрева пальцев и мозга. Для тех кто не в курсе: мое олимпиадное хобби состоит в решении олимпиадных задач по программированию, которые я беру с сайта
Привет. Сегодня понедельник, поэтому я решил, что стоит начать свой рабочий день с разогрева пальцев и мозга. Для тех кто не в курсе: мое олимпиадное хобби состоит в решении олимпиадных задач по программированию, которые я беру с сайта 

 Доброго времени суток, хабр! Сегодня я бы хотел рассказать про жадные алгоритмы.
Доброго времени суток, хабр! Сегодня я бы хотел рассказать про жадные алгоритмы.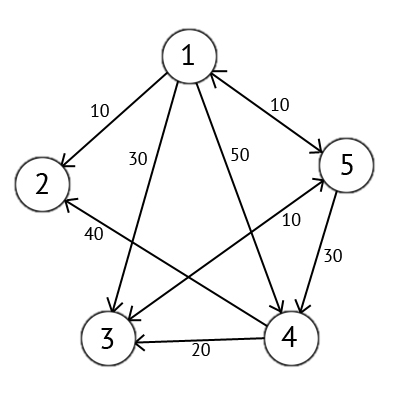
 В апреле-мае 2011 года компания Яндекс проводила очередной тур конкурса
В апреле-мае 2011 года компания Яндекс проводила очередной тур конкурса 