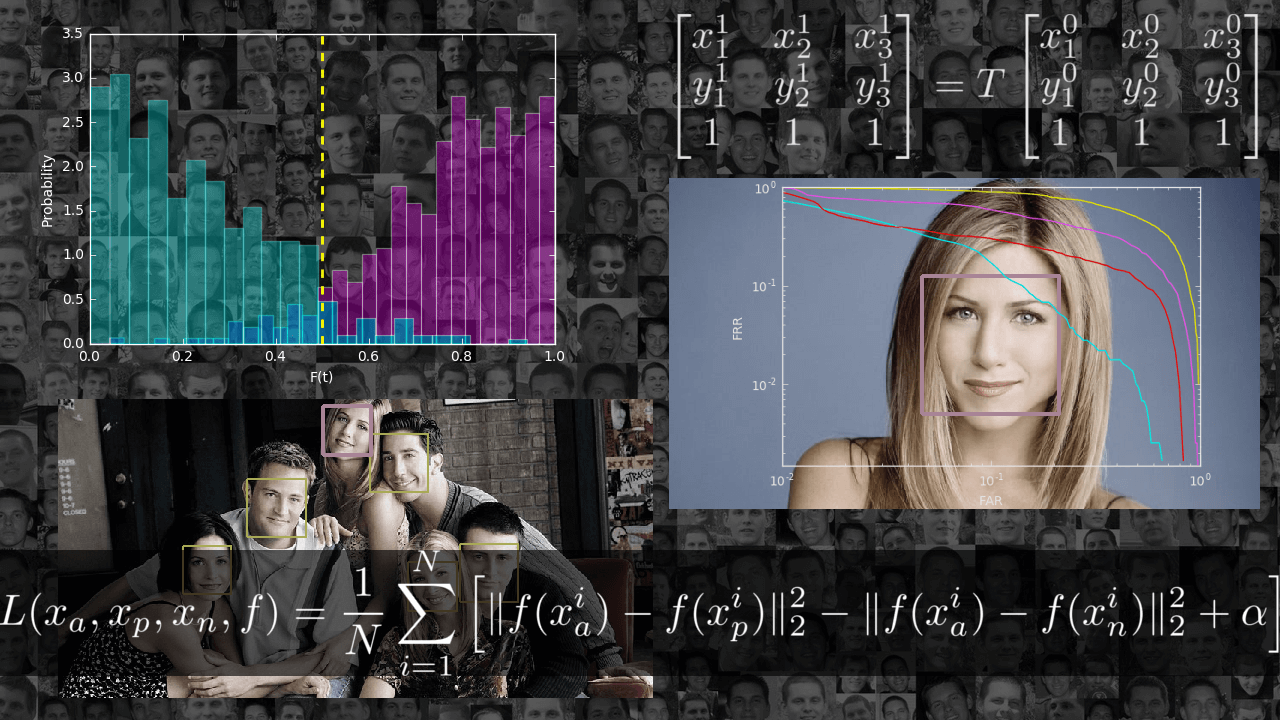Знакома ли вам ситуация, когда на выбор фильма вы тратите гигантское количество времени, сопоставимое со временем самого просмотра? Для пользователей онлайн-кинотеатров это частая проблема, а для самих кинотеатров — упущенная прибыль.
К счастью, у нас есть Rekko — система персональных рекомендаций, которая уже год успешно помогает пользователям Okko выбирать фильмы и сериалы из более чем десяти тысяч единиц контента. В статье я расскажу вам как она устроена с алгоритмической и технической точек зрения, как мы подходим к её разработке и как оцениваем результаты. Ну и про сами результаты годового A/B теста тоже расскажу.
Сегодня мы запускаем Rekko Challenge 2019 — соревнование по машинному обучению от онлайн-кинотеатра Okko.
Мы предлагаем вам построить рекомендательную систему на реальных данных одного из крупнейших российских онлайн-кинотеатров. Уверены, что эта задача будет интересна и новичкам, и опытным специалистам. Мы постарались сохранить максимальный простор для творчества, при этом не перегружая вас гигабайтными датасетами с сотнями предварительно посчитанных признаков.
Подробнее про Okko, задачу, данные, призы и правила — ниже.
Мы в отделе аналитики онлайн-кинотеатра Okko любим как можно сильнее автоматизировать подсчёты сборов фильмов Александра Невского, а в освободившееся время учиться новому и реализовывать классные штуки, которые почему-то обычно выливаются в ботов для Телеграма. К примеру, перед началом чемпионата мира по футболу 2018 мы выкатили в рабочий чат бота, который собирал ставки на распределение итоговых мест, а после финала подсчитал результаты по заранее придуманной метрике и определил победителей. Хорватию в четвёрку не поставил никто.
Недавнее же свободное от составления ТОП-10 российских комедий время мы посвятили созданию бота, который находит знаменитость, на которую пользователь больше всего похож лицом. В рабочем чате идею все настолько оценили, что мы решили сделать бота общедоступным. В этой статье мы кратко вспомним теорию, расскажем о создании нашего бота и о том, как сделать такого самому.
PyTorch — современная библиотека глубокого обучения, развивающаяся под крылом Facebook. Она не похожа на другие популярные библиотеки, такие как Caffe, Theano и TensorFlow. Она позволяет исследователям воплощать в жизнь свои самые смелые фантазии, а инженерам с лёгкостью эти фантазии имплементировать.
Данная статья представляет собой лаконичное введение в PyTorch и предназначена для быстрого ознакомления с библиотекой и формирования понимания её основных особенностей и её местоположения среди остальных библиотек глубокого обучения.
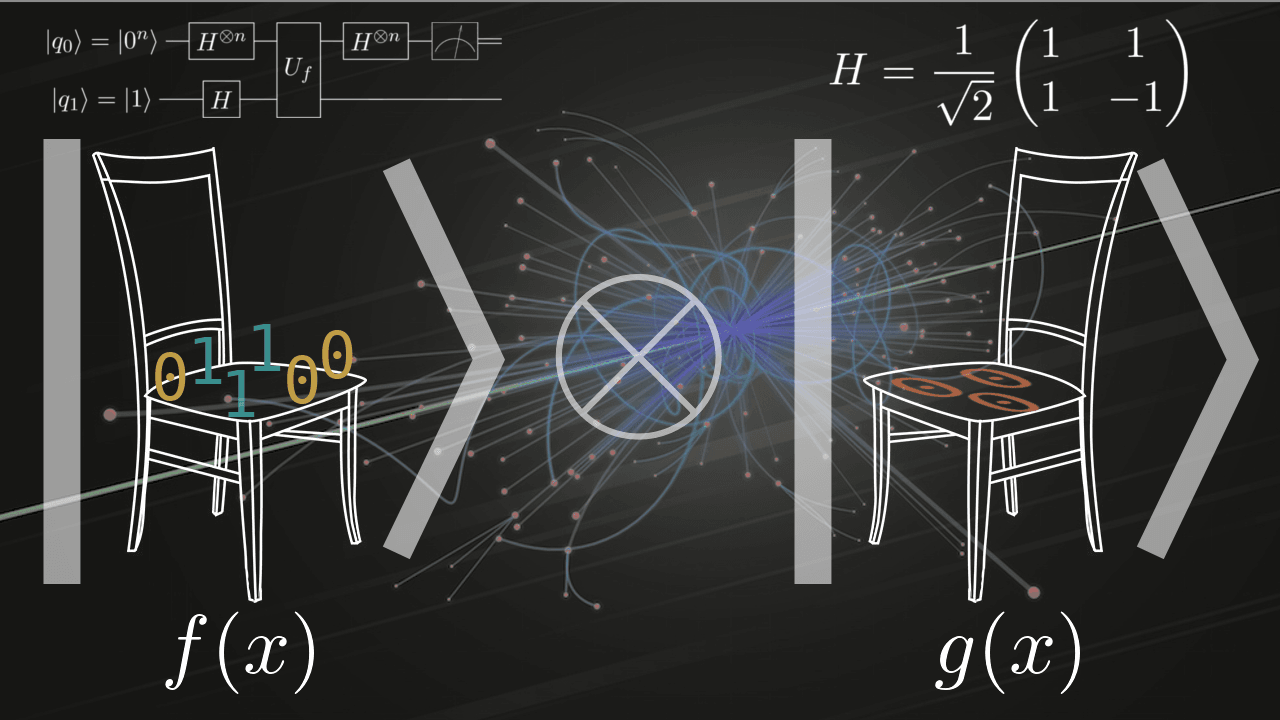
Есть две булевы функции аргументов, одна — константная, другая — сбалансированная. На какую сам сядешь, на какую фронтендера посадишь? Вот только функции неизвестны, а вызвать их разрешается лишь один раз.
Если не знаешь, как решить подобную задачу, добро пожаловать под кат. Там я расскажу про квантовые алгоритмы и покажу как их эмулировать на самом народном языке — на Python.
В статье я хочу познакомить читателя с задачей идентификации: пройтись от основных определений до реализации одной из недавних статей в данной области. Итогом должно стать приложение, способное искать одинаковых людей на фотографиях и, что самое главное, понимание того, как оно работает.