
От переводчика: В статье есть несколько JavaScript нюансов, которые могут быть интересны и тем, кто далек от CoffeeScript
Как и все программисты, я осторожен в отношение CoffeeScript. Как может, немного синтаксического сахара, оправдать дополнительный шаг компиляции?
Но, после того как я поиграл с CoffeeScript, всего несколько дней, я понял, я никогда не вернусь назад. Синтаксический сахар — это только начало. Я стал писать код быстрее, и с меньшим количеством ошибок, потому что он, стал намного чище. CoffeeScript помогает придерживаться хорошего стиля в написание кода. Ниже я приведу несколько примеров на Javascript и опишу их более изящное решение с помощью CoffeeScript.
Как и все программисты, я осторожен в отношение CoffeeScript. Как может, немного синтаксического сахара, оправдать дополнительный шаг компиляции?
Но, после того как я поиграл с CoffeeScript, всего несколько дней, я понял, я никогда не вернусь назад. Синтаксический сахар — это только начало. Я стал писать код быстрее, и с меньшим количеством ошибок, потому что он, стал намного чище. CoffeeScript помогает придерживаться хорошего стиля в написание кода. Ниже я приведу несколько примеров на Javascript и опишу их более изящное решение с помощью CoffeeScript.

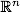 . Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue).
. Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue).