
Эффективное использование Github
13 мин

Github — важная часть жизни современного разработчика: он стал стандартом для размещения opensource-проектов. В «2ГИС» мы используем гитхаб для разработки проектов web-отдела и хостинга проектов с открытым кодом.
Хотя большинство из нас пользуются сервисом практически каждый день, не все знают, что у него есть много фишек, помогающих облегчить работу или рутинные операции. Например, получение публичного ключа из URL; отслеживание того, с каких сайтов пользователи приходят в репозиторий; правильный шаринг ссылок на файлы, которые живут в репозиториях гитхаба; горячие клавиши и тому подобное. Цель этой статьи — рассказать о неочевидных вещах и вообще о том, что сделает вашу работу с гитхабом продуктивнее и веселее (я не буду рассматривать здесь работу с API гитхаба, так как эта тема заслуживает отдельной статьи).
Содержание
- Трюки с URL
- Горячие клавиши
- Тикеты и пулл-реквесты
- Github markdown
- Аккаунт
- Работа с репозиториями
- Поиск кода
- Командная строка и Github
- User scripts
- Github-вандализм
- Дополнительные Github-ресурсы
- Полезные ссылки



 Это пятая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре в переводе
Это пятая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре в переводе 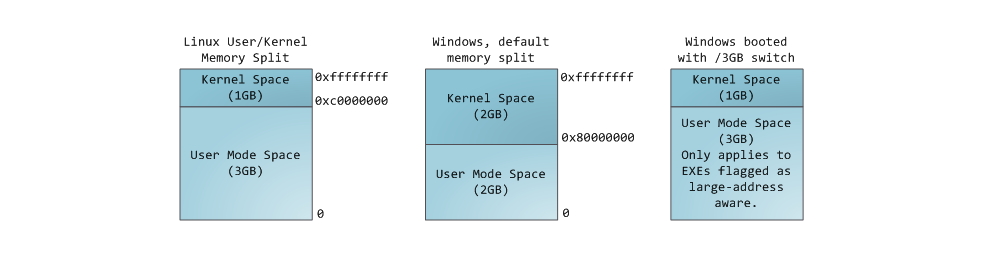


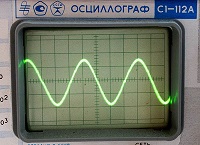 Недавно я увидел проект генератора сигналов на микроконтроллере AVR. Принцип генерации —
Недавно я увидел проект генератора сигналов на микроконтроллере AVR. Принцип генерации — 