Если пройтись по коллегам и спросить сколько у них сотовых телефонов, то окажется, что в среднем их около 2.5, но при этом у подавляющего большинства их не больше одного. Тут возникает сразу множество вопросов начиная от того, почему их вдруг не целое число и как же все-таки оценить сколько телефонов в среднем у человека.

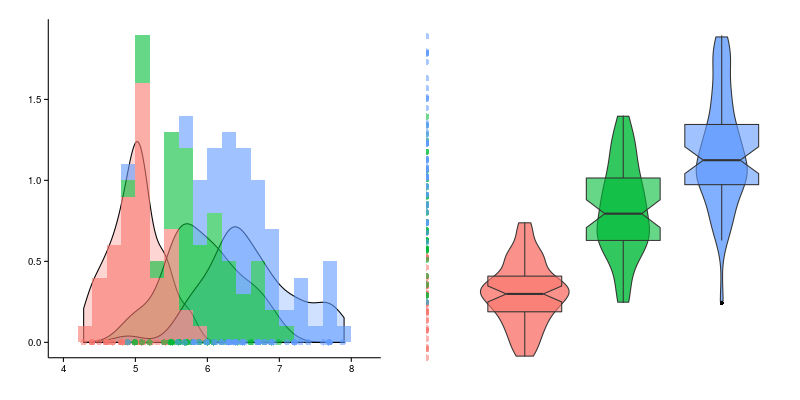
Для таких целей подойдет оценка медианы. То есть такая статистика, что половина значений выборки меньше, а половина больше. Более формально: упорядочим значения выборки
)
по порядку
![(x_{[1]}, ..., x_{[n]})](http://tex.s2cms.ru/svg/(x_%7B%5B1%5D%7D%2C%20...%2C%20x_%7B%5Bn%5D%7D))
и выберем среди них с порядковым номером
)
. У такой оценки есть несколько преимуществ. Она менее подвержена влиянию ошибочных данных, значение всегда будет из того множества, что встречалось в выборке, но есть и неприятные недостатки, главный из них, это сложность подсчета, даже для довольно распространенных распределений не существует общей формулы расчета (точнее есть, но ее сложно применить на практике, смотрите
Распределение порядковой статистики).

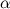 из равномерного распределения на
из равномерного распределения на ![[0,1]](https://habrastorage.org/getpro/geektimes/post_images/1e5/668/a24/1e5668a24690f7b412a044dbc14ad6bd.png) . А именно:
. А именно:  , где
, где  — взятие целой части у аргумента.
— взятие целой части у аргумента. вероятность выпадения грани
вероятность выпадения грани 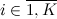 . При этом выполняется естественное ограничение
. При этом выполняется естественное ограничение  . Постараюсь ответить на вопрос: как смоделировать псевдослучайную последовательность с таким распределением?
. Постараюсь ответить на вопрос: как смоделировать псевдослучайную последовательность с таким распределением?