Библиотеки, реализующие стандарт MPI (Message Passing Interface) — наиболее популярный механизм организации вычислений на кластере. MPI позволяет передавать сообщения между узлами (серверами), но никто не мешает запускать несколько MPI процессов и на одном узле, реализуя потенциал нескольких ядер. Так часто и пишутся HPC приложения, так проще. И пока количество ядер на одном узле было мало, никаких проблем с «чистым MPI» подходом не было. Но сегодня количество ядер идёт на десятки, а то и на сотни для со-процессоров Intel Xeon-Phi. И в такой ситуации запуск десятков процессов на одной машине становится не совсем эффективным.
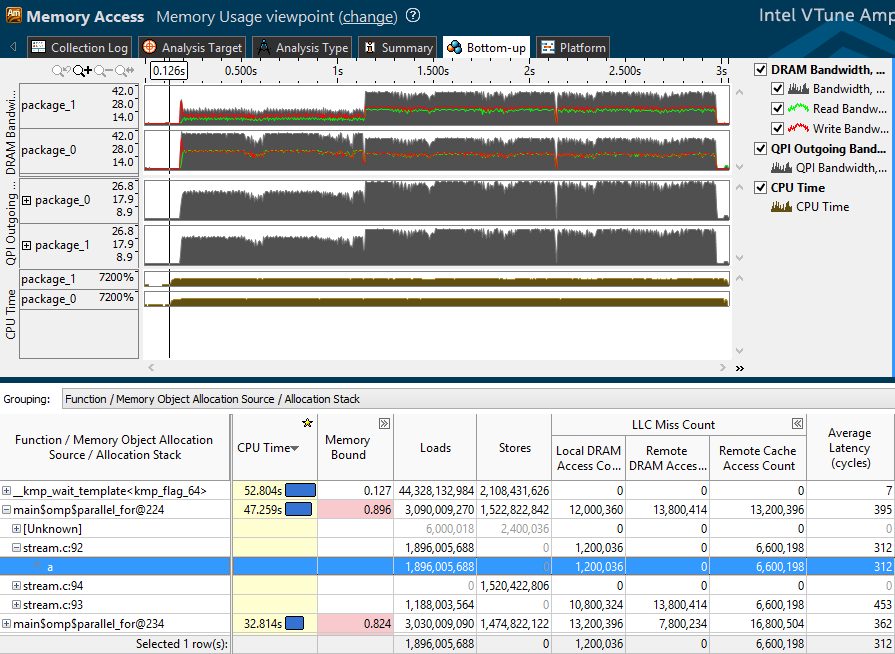
Дело в том, что MPI процессы общаются через сетевой интерфейс (хоть и реализованный через общую память на одной машине). Это влечет за собой избыточные копирования данных через множество буферов и увеличенный расход памяти.
Для параллельных вычислений внутри одной машины с общей памятью гораздо лучше подходят потоки и распределение задач между ними. Здесь наибольшей популярностью в мире HPC пользуется стандарт OpenMP.
Казалось бы – ладно, используем OpenMP внутри узла, и MPI для меж-узловых коммуникаций. Но не всё так просто. Использование двух фреймворков (MPI и OpenMP) вместо одного не только несёт дополнительную сложность программирования, но и не всегда даёт желаемый прирост производительности – по крайней мере, не сразу. Нужно ещё решить, как распределить вычисления между MPI и OpenMP, и, возможно, решить проблемы, специфичные для каждого уровня.
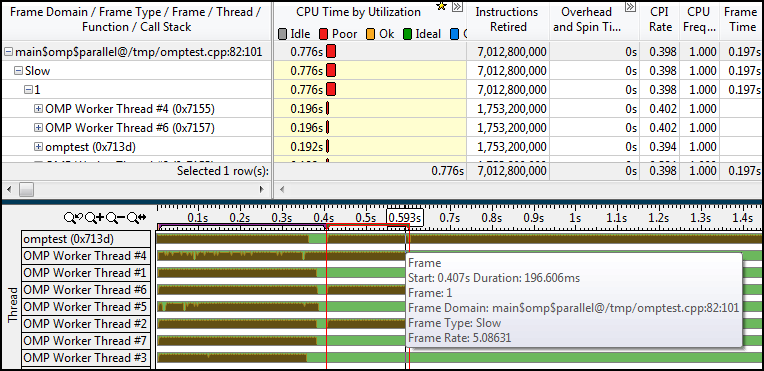
В этой статье я не буду описывать создание гибридных приложений – информацию найти не сложно. Мы рассмотрим, как можно анализировать гибридные приложения с помощью инструментов Intel Parallel Studio, выбирая оптимальную конфигурацию и устраняя узкие места на разных уровнях.