Эта статья - сборник разных вопросов и ответов на них, которые звучали в комментариях к моим предыдущим статьям (Современные технологии обхода блокировок: V2Ray, XRay, XTLS, Hysteria, Cloak и все-все-все, Bleeding-edge обход блокировок с полной маскировкой: настраиваем сервер и клиент XRay с XTLS-Reality быстро и просто и других из той же серии) и в личных сообщениях.

mahoune @mahoune
Пользователь
Изучаем Docker, часть 5: команды
9 мин
Туториал
Перевод
Сегодняшняя часть цикла материалов по Docker, перевод которого мы публикуем, посвящена командам Docker. Документация Docker содержит подробнейшее описание великого множества команд, но тот, кто только начинает работу с этой платформой, может в них и потеряться, поэтому здесь приведены почти два десятка самых важных команд для работы с Docker. Продолжая сложившуюся традицию, мы сравним команды с россыпью ягод.
→ Часть 1: основы
→ Часть 2: термины и концепции
→ Часть 3: файлы Dockerfile
→ Часть 4: уменьшение размеров образов и ускорение их сборки
→ Часть 5: команды
→ Часть 6: работа с данными

→ Часть 1: основы
→ Часть 2: термины и концепции
→ Часть 3: файлы Dockerfile
→ Часть 4: уменьшение размеров образов и ускорение их сборки
→ Часть 5: команды
→ Часть 6: работа с данными
Изучаем Docker, часть 4: уменьшение размеров образов и ускорение их сборки
8 мин
Туториал
Перевод
В этой части перевода серии материалов, которая посвящена Docker, мы поговорим о том, как оптимизировать размеры образов и ускорить их сборку. В прошлых материалах мы сравнивали образы Docker с пиццей, термины с пончиками, а инструкции файлов Dockerfile с бубликами. Сегодня же не будет никакой выпечки. Пришло время посидеть на диете.
→ Часть 1: основы
→ Часть 2: термины и концепции
→ Часть 3: файлы Dockerfile
→ Часть 4: уменьшение размеров образов и ускорение их сборки
→ Часть 5: команды
→ Часть 6: работа с данными

Для того чтобы разобраться с тем, о чём мы будем тут говорить, вам будет полезно освежить в памяти то, о чём шла речь в третьей части этой серии материалов. А именно, там мы говорили об инструкциях файлов Dockerfile. Знание этих инструкций и тех особенностей Docker, которые мы обсудим сегодня, поможет вам оптимизировать файлы образов Docker.
→ Часть 1: основы
→ Часть 2: термины и концепции
→ Часть 3: файлы Dockerfile
→ Часть 4: уменьшение размеров образов и ускорение их сборки
→ Часть 5: команды
→ Часть 6: работа с данными
Для того чтобы разобраться с тем, о чём мы будем тут говорить, вам будет полезно освежить в памяти то, о чём шла речь в третьей части этой серии материалов. А именно, там мы говорили об инструкциях файлов Dockerfile. Знание этих инструкций и тех особенностей Docker, которые мы обсудим сегодня, поможет вам оптимизировать файлы образов Docker.
Изучаем Docker, часть 3: файлы Dockerfile
12 мин
Перевод
В переводе третьей части серии материалов, посвящённых Docker, мы продолжим вдохновляться выпечкой, а именно — бубликами. Нашей сегодняшней основной темой будет работа с файлами Dockerfile. Мы разберём инструкции, которые используются в этих файлах.
→ Часть 1: основы
→ Часть 2: термины и концепции
→ Часть 3: файлы Dockerfile
→ Часть 4: уменьшение размеров образов и ускорение их сборки
→ Часть 5: команды
→ Часть 6: работа с данными

Бублики — это инструкции в файле Dockerfile
→ Часть 1: основы
→ Часть 2: термины и концепции
→ Часть 3: файлы Dockerfile
→ Часть 4: уменьшение размеров образов и ускорение их сборки
→ Часть 5: команды
→ Часть 6: работа с данными
Бублики — это инструкции в файле Dockerfile
Изучаем Docker, часть 2: термины и концепции
6 мин
Перевод
В первой части перевода серии материалов, посвящённых Docker, мы сделали общий обзор этой системы. В частности, мы говорили о том, почему технологии контейнеризации важны в наше время, о том, что такое контейнеры Docker, и о том, с чем их можно сравнить. Сегодня мы поговорим об экосистеме Docker и рассмотрим важные термины, с которыми вы можете столкнуться на пути изучения и использования Docker. Продолжив аналогию с разными вкусностями, представим, что наши термины — это пончики. Дюжина пончиков.
→ Часть 1: основы
→ Часть 2: термины и концепции
→ Часть 3: файлы Dockerfile
→ Часть 4: уменьшение размеров образов и ускорение их сборки
→ Часть 5: команды
→ Часть 6: работа с данными

→ Часть 1: основы
→ Часть 2: термины и концепции
→ Часть 3: файлы Dockerfile
→ Часть 4: уменьшение размеров образов и ускорение их сборки
→ Часть 5: команды
→ Часть 6: работа с данными
Изучаем Docker, часть 1: основы
6 мин
Туториал
Перевод
Технологии контейнеризации приложений нашли широкое применение в сферах разработки ПО и анализа данных. Эти технологии помогают сделать приложения более безопасными, облегчают их развёртывание и улучшают возможности по их масштабированию. Рост и развитие технологий контейнеризации можно считать одним из важнейших трендов современности.
Docker — это платформа, которая предназначена для разработки, развёртывания и запуска приложений в контейнерах. Слово «Docker» в последнее время стало чем-то вроде синонима слова «контейнеризация». И если вы ещё не пользуетесь Docker, но при этом работаете или собираетесь работать в сферах разработки приложений или анализа данных, то Docker — это то, с чем вы непременно встретитесь в будущем.
→ Часть 1: основы
→ Часть 2: термины и концепции
→ Часть 3: файлы Dockerfile
→ Часть 4: уменьшение размеров образов и ускорение их сборки
→ Часть 5: команды
→ Часть 6: работа с данными

Если вы пока не знаете о том, что такое Docker, сейчас у вас есть шанс сделать первый шаг к пониманию этой платформы. А именно, освоив этот материал, вы разберётесь с основами Docker и попутно приготовите пиццу.
Docker — это платформа, которая предназначена для разработки, развёртывания и запуска приложений в контейнерах. Слово «Docker» в последнее время стало чем-то вроде синонима слова «контейнеризация». И если вы ещё не пользуетесь Docker, но при этом работаете или собираетесь работать в сферах разработки приложений или анализа данных, то Docker — это то, с чем вы непременно встретитесь в будущем.
→ Часть 1: основы
→ Часть 2: термины и концепции
→ Часть 3: файлы Dockerfile
→ Часть 4: уменьшение размеров образов и ускорение их сборки
→ Часть 5: команды
→ Часть 6: работа с данными
Если вы пока не знаете о том, что такое Docker, сейчас у вас есть шанс сделать первый шаг к пониманию этой платформы. А именно, освоив этот материал, вы разберётесь с основами Docker и попутно приготовите пиццу.
Настройка LEMP сервера для простых проектов. Инструкция для самых маленьких. Часть первая
12 мин

Ведение
Приветствую читателей. В практике нашей компании часто появляется потребность в настройке серверов для простых односерверных проектов или небольших кластеров. В этой статье я бы хотел рассказать вам о нашем опыте подобной настройки, выделить особенности, которые могут вам пригодиться при дальнейшем администрировании. Статья предназначена для людей, которые только вникают в администрирование, а также для тех, кто самостоятельно администрирует свой небольшой проект и хочет набраться опыта в этом деле. Если вы являетесь опытным администратором, то можете смело пропускать данный материал.
Целью серии статей является описание подготовки работы сервера со стоком LEMP (Linux, Nginx, MySQL, PHP, Apache), развертывание стэка и поднятие на нем работающих площадок. Инструкция подойдет для небольших Bitrix проектов, а тажке для проектов развернутых под любой популярной CMS.
Не смотря на то, что тема уже достаточно подробно отражена в сети, мы решили подробно описать общие стандарты администрирования с нуля, по-скольку регулярно получаем большое количество базовых вопросов от людей, так или иначе, связанных с нашей сферой.
Большая часть проектов базируется на ОС Ubuntu, Debian в статьях будут отражены настройки для этих систем.
В данной статье будут описаны такие вещи как:
Борьба за ресурсы, часть 6: cpuset или Делиться не всегда правильно
6 мин
Во время разговоров о cgroups пользователи Red Hat довольно часто задают один и тот же вопрос: «У меня есть одно приложение, очень чувствительное в смысле задержек. Можно ли с помощью cgroups изолировать это приложение от остальных, привязав его к определенным процессорным ядрам?»

Разумеется, можно. Иначе мы бы не выбрали этот вопрос в качестве темы сегодняшней статьи.
Разумеется, можно. Иначе мы бы не выбрали этот вопрос в качестве темы сегодняшней статьи.
Борьба за ресурсы, часть 5: Начиная с нуля
6 мин
Продолжаем изучать cgroups. В Red Hat Enterprise Linux 7 они задействуется по умолчанию, поскольку здесь используется systemd, а он, в свою очередь, имеет уже встроенные cgroups. С Red Hat Red Hat Enterprise Linux 6 все немного иначе. На самом деле контроллеры cgroups изначально были и там, а вышла эта версия, напомним, в январе 2010 года, то есть пару столетий назад в пересчете на компьютерные годы.

Однако cgroups в Red Hat Enterprise Linux 6 и сегодня на многое способны, что мы сегодня и проиллюстрируем.
Однако cgroups в Red Hat Enterprise Linux 6 и сегодня на многое способны, что мы сегодня и проиллюстрируем.
Борьба за ресурсы, часть 4: Замечательно выходит
5 мин
Разберемся с регуляторами подсистемы хранения данных и посмотрим, что они позволяют делать в смысле блочного ввода-вывода.

Особенно интересно здесь то, что мы вступаем на территорию, где изменения настроек, которые вносятся уже после запуска системы, гораздо менее важны, чем решения, которые принимаются еще до ее развертывания.
Особенно интересно здесь то, что мы вступаем на территорию, где изменения настроек, которые вносятся уже после запуска системы, гораздо менее важны, чем решения, которые принимаются еще до ее развертывания.
Борьба за ресурсы, часть 3: Памяти мало не бывает
3 мин
Продолжаем изучать Control Groups (Cgroups) в Red Hat Enterprise Linux 7. Займемся памятью. Вы помните, что для распределения процессорного времени есть две регулировки: CPUShares для настройки относительных долей и CPUQuota для того, чтобы ограничивать пользователя, службу или виртуальную машину (ВМ) в абсолютных величинах (процентах) процессорного времени. Причем, обе эти регулировки можно использовать одновременно. Например, если для пользователя задана CPU-квота в 50 %, то его CPU-шара тоже будет приниматься во внимание до тех пор, пока он полностью не выберет свою квоту в 50 % процессорного времени.

Что касается оперативной памяти, то systemd предлагает только один способ регулировки, а именно…
Что касается оперативной памяти, то systemd предлагает только один способ регулировки, а именно…
Борьба за ресурсы, часть 2: Играемся с настройками Cgroups
5 мин
Мы начали изучать Control Groups (Cgroups) в Red Hat Enterprise Linux 7 – механизм уровня ядра, позволяющий управлять использованием системных ресурсов, кратко рассмотрели теоретические основы и теперь переходим к практике управления ресурсами CPU, памяти и ввода-вывода.

Однако, прежде чем что-то менять, всегда полезно узнать, как все устроено сейчас.
Однако, прежде чем что-то менять, всегда полезно узнать, как все устроено сейчас.
Глубокое погружение в Linux namespaces, часть 4
10 мин
Перевод
Часть 1
Часть 2
Часть 3
Часть 4
В завершающем посте этой серии мы рассмотрим Network namespaces. Как мы упоминали в вводном посте, network namespace изолирует ресурсы, связанные с сетью: процесс, работающий в отдельном network namespace, имеет собственные сетевые устройства, таблицы маршрутизации, правила фаервола и т.д. Мы можем непосредственно увидеть это на практике, рассмотрев наше текущее сетевое окружение.
Глубокое погружение в Linux namespaces, часть 3
9 мин
Перевод
Часть 1
Часть 2
Часть 3
Часть 4
Mount namespaces изолируют ресурсы файловых систем. Это по большей части включает всё, что имеет отношение к файлам в системе. Среди охватываемых ресурсов есть файл, содержащий список точек монтирования, которые видны процессу, и, как мы намекали во вступительном посте, изолирование может обеспечить такое поведение, что изменение списка (или любого другого файла) в пределах некоторого mount namespace инстанса M не будет влиять на этот список в другом инстансе (так что только процессы в M увидят изменения)
Глубокое погружение в Linux namespaces, часть 2
9 мин
Перевод
Часть 1
Часть 2
Часть 3
Часть 4
В предыдущей части мы только окунули пальцы ног в воды namespace и при этом увидели, как это было просто — запустить процесс в изолированном UTS namespace. В этом посте мы осветим User namespace.
Среди прочих ресурсов, связанных с безопасностью, User namespaces изолирует идентификаторы пользователей и групп в системе. В этом посте мы сосредоточимся исключительно на ресурсах user и group ID (UID и GID соответственно), поскольку они играют фундаментальную роль в проведении проверок разрешений и других действий во всей системе, связанных с безопасностью.
В Linux эти ID — просто целые числа, которые идентифицируют пользователей и группы в системе. И каждому процессу назначаются какие-то из них, чтобы задать к каким операциями/ресурсам этот процесс может и не может получить доступ. Способность процесса нанести ущерб зависит от разрешений, связанных с назначенными ID.
Глубокое погружение в Linux namespaces
7 мин
Перевод
Часть 1
Часть 2
Часть 3
Часть 4
В этой серии постов мы внимательно рассмотрим один из главных ингредиентов в контейнере – namespaces. В процессе мы создадим более простой клон команды docker run – нашу собственную программу, которая будет принимать на входе команду (вместе с её аргументами, если таковые имеются) и разворачивать контейнер для её выполнения, изолированный от остальной системы, подобно тому, как вы бы выполнили docker run для запуска из образа.
Настраиваем двухступенчатый WireGuard для выхода из страны
Средний
4 мин
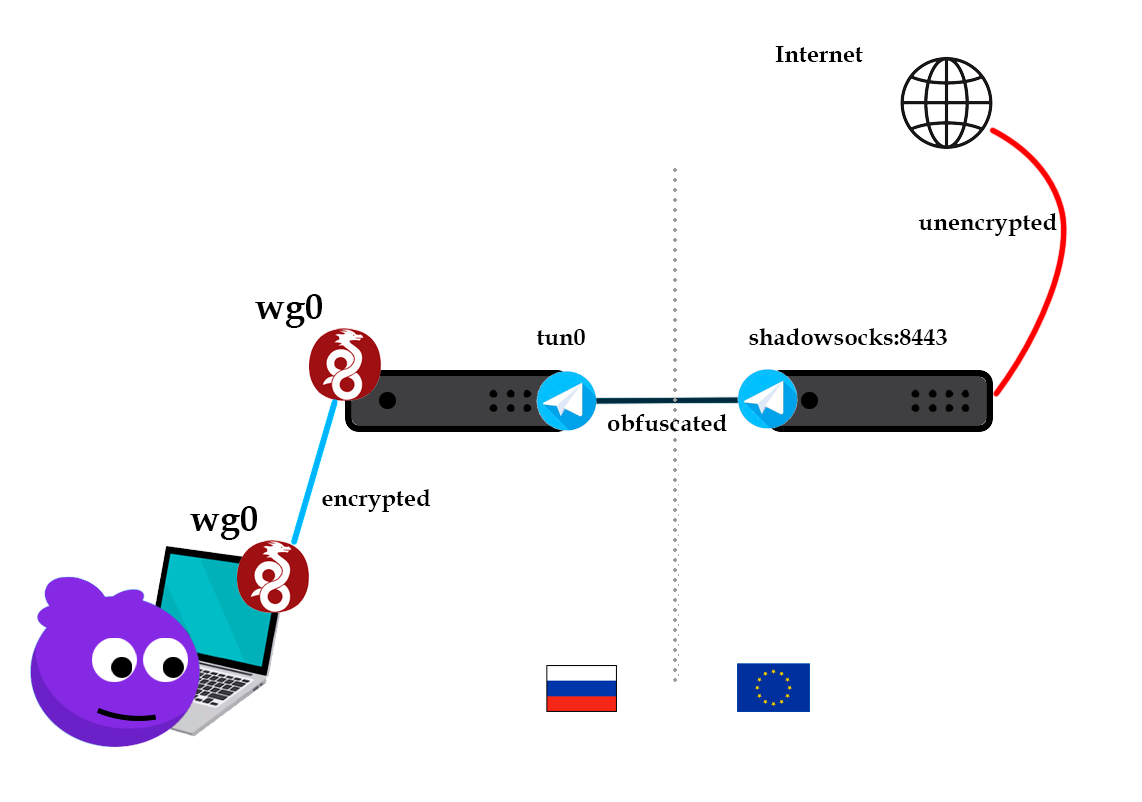
У Wireguard есть немало прекрасного, включая его простоту реализации, скорость и минималистичные клиенты, которые не вызывают проблем у пользователей.
В начале августа некоторые интернет операторы и провайдеры начали блокировку протокола WireGuard в РФ по его рукопожатию.
Лично испытывал блокировку у Мегафон и Теле2, но не заметил у Ростелеком. VPN по-прежнему работал через последнего.
Очень не хотелось отказываться от Wireguard в пользу прокси-серверов в духе VLESS+TLS-Vision, в виду того, что все наши пользователи уже сильно привыкли именно к Wireguard.
Поэтому вариант с кардинальной сменой клиентского софта не рассматривался.
Поскольку трафик Wireguard блокируется только на зарубежные адреса было принято решение добавить еще один хоп в систему, а начальное подключение осуществлять к серверу в РФ.
Механизмы контейнеризации: cgroups
11 мин
Туториал

Продолжаем цикл статей о механизмах контейнеризации. В прошлый раз мы говорили об изоляции процессов с помощью механизма «пространств имён» (namespaces). Но для контейнеризации одной лишь изоляции ресурсов недостаточно. Если мы запускаем какое-либо приложение в изолированном окружении, мы должны быть уверены в том, что этому приложению выделено достаточно ресурсов и что оно не будет потреблять лишние ресурсы, нарушая тем самым работу остальной системы. Для решения этой задачи в ядре Linux имеется специальный механизм — cgroups (сокращение от control groups, контрольные группы). О нём мы расскажем в сегодняшней статье.
Механизмы контейнеризации: namespaces
11 мин

Последние несколько лет отмечены ростом популярности «контейнерных» решений для ОС Linux. О том, как и для каких целей можно использовать контейнеры, сегодня много говорят и пишут. А вот механизмам, лежащим в основе контейнеризации, уделяется гораздо меньше внимания.
Все инструменты контейнеризации — будь то Docker, LXC или systemd-nspawn,— основываются на двух подсистемах ядра Linux: namespaces и cgroups. Механизм namespaces (пространств имён) мы хотели бы подробно рассмотреть в этой статье.
Начнём несколько издалека. Идеи, лежащие в основе механизма пространств имён, не новы. Ещё в 1979 году в UNIX был добавлен системный вызов chroot() — как раз с целью обеспечить изоляцию и предоставить разработчикам отдельную от основной системы площадку для тестирования. Нелишним будет вспомнить, как он работает. Затем мы рассмотрим особенности функционирования механизма пространств имён в современных Linux-системах.