Недавно я наткнулся на интересную статью, опубликованную rgen3, в которой описан DTW-алгоритм распознавания речи. В общих чертах, это сравнение речевых последовательностей с применением динамического программирования.
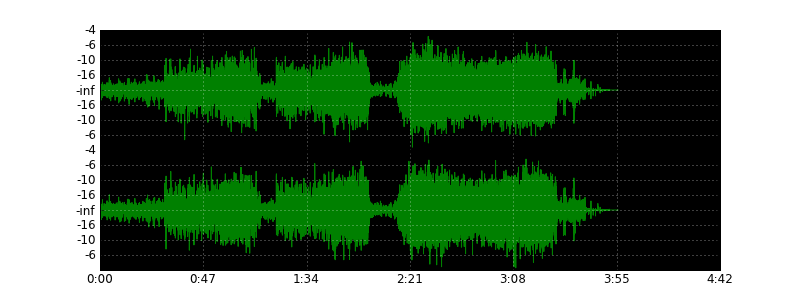
Заинтересовавшись темой, я попробовал применить этот алгоритм на практике, но на этом пути меня поджидало некоторое количество граблей. Прежде всего, что именно нужно сравнивать? Непосредственно звуковые сигналы во временной области — долго и не очень эффективно. Спектрограммы — уже быстрее, но не намного эффективнее. Поиски наиболее рационального представления привели меня к MFCC или Мел-частотным кепстральным коэффициентам, которые часто используются в качестве характеристики речевых сигналов. Здесь я попытаюсь объяснить, что они из себя представляют.
Заинтересовавшись темой, я попробовал применить этот алгоритм на практике, но на этом пути меня поджидало некоторое количество граблей. Прежде всего, что именно нужно сравнивать? Непосредственно звуковые сигналы во временной области — долго и не очень эффективно. Спектрограммы — уже быстрее, но не намного эффективнее. Поиски наиболее рационального представления привели меня к MFCC или Мел-частотным кепстральным коэффициентам, которые часто используются в качестве характеристики речевых сигналов. Здесь я попытаюсь объяснить, что они из себя представляют.